从Deep Image Prior到NAS Deep Image Prior
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达

本文作者:科技猛兽
https://zhuanlan.zhihu.com/p/242222614
本文已由原作者授权,不得擅自二次转载
1. Deep Image Prior
论文:https://arxiv.org/abs/1711.10925
https://github.com/DmitryUlyanov/deep-image-prior
被收录在 CVPR 2018。
不同的神经网络可以实现给图像去噪、去水印、消除马赛克等功能,但我们能否让一个模型完成上述所有事?事实证明 CNN 确实有这样的能力。来自 Skoltech、Yandex 和牛津大学的学者们提出了一种可以满足所有大胆想法的神经网络,去噪、去水印、超分辨率,这款不用学习的神经网络无所不能。
Deep Image Prior 的重要特点是,网络由始至终仅使用了输入的,被破坏过的图像做为训练,没有经历过大多数神经网络所需要的学习过程即可完成任务。它没有「看过」任何其它图像,也没有看过未受破坏的正常图像,但最终恢复的效果依然很好,这说明自然图像的局部规律和自相似性确实很强。
什么?对于去噪,修复,超分等任务不需要原始图片,只需要一个神经网络和degraded的数据就能得到很棒的性能?
作者展示的结果的确如此。
我们的目的是学习图像的先验(Prior)
其实上面的每一项任务都有很多研究,目前在图像复原,图像生成任务中表现优异的CNN都是使用大量的数据集进行训练,以往通常的解释是,网络能够学到数据的先验信息。它们假设模型能从大型真实图像数据集中学习到图像的先验信息,即像素怎样才能组合成一张「正常」的图像,这样学习到通用图像信息的模型就能用来修补图像或生成高分辨率图像了。但是这种观点正确吗?Deep Image Prior 表示,在损坏的「非正常」图像上训练同样能学习到图像的「先验」,注意这种「训练」仅表示模型在单张损坏图像上反复迭代。
作者认为,一个随机初始化的网络就是一个非常好的prior,它能够解决大多数常见的逆问题(standard inverse problems),比如说去噪,超分,修复等等。
与传统观点相反,该项目的研究论文表示未经任何「学习过程」的卷积图像生成器架构可以捕捉到大量图像数据,尤其是解决不同图像修复问题的图像数据。在卷积网络对损坏图像反复迭代时,它能自动利用图像的全局统计信息重构丢失的部分。
作者认为,解决以上这些问题,一个神经网络和的degraded image(待修复/超分/复原/去噪的图片)就足够了。
主要思路
作者假设 


其中, 

进而有:

网络的架构 

说了这么多,我们详细看下具体的做法:
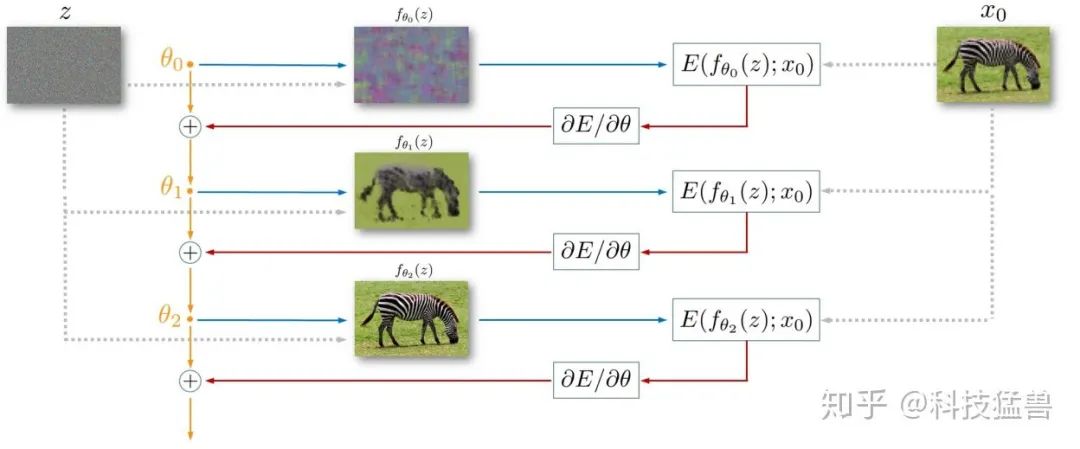
请认真阅读本工作的方法:
首先人工设计一个网络架构
,将其随机初始化。
将随机编码
(如上图所示)作为网络的输入,需要注意两点:第1是
在整个过程中是不变的;第2是
的维度和输出是一样的。
目标函数就是
,这里我们让网络的输出
与degraded image
尽量接近。是的,你没看错,是与待修复/超分/复原/去噪的图片尽量接近。
采用如Adam方法训练。你可能会有疑问,那训练出来的网络输出不应该是degraded image吗?答案是:没错,如果把网络训练至稳定或者收敛,网络就会输出和degraded image一模一样的图像。
所以我们在训练到一半时打断训练,网络依旧输入随机编码
,此时输出的就是修复/超分/复原/去噪后的图片。
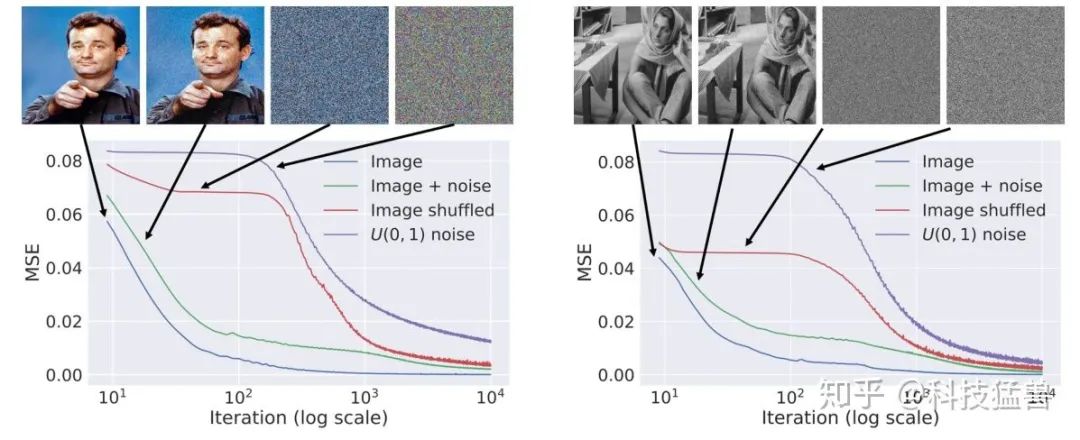
上图为作者展示的4个不同任务的learning curve:
natural image
natural image+noise
natural image+随机排列像素
白噪声
从结果可以看出前2个任务优化过程更快,后2个任务展示出惰性。
这说明网络对自然图像fit的最快, 噪声也能fit, 但是就比较reluctant, 或者说网络参数对自然图像有low impedence, 而对噪声有high impedance, 所以可以用来去噪。就是说, 一幅图像, 给足够的iteration step, 总是可以学的很像的, 但是先学的是主要pattern, 然后才会去学detail, 那我们就是控制什么时候学好了主要的pattern停止iteration, 这样作为detail的noise就不会还原, 这样就去噪了。
这意味着网络先学会图片中“未被破坏的,符合自然规律的部分”再学会图片中“已被破坏的部分”它会先学会如何复制出一张没有噪点的图片,然后才会学会复制出一张有噪点的图片。
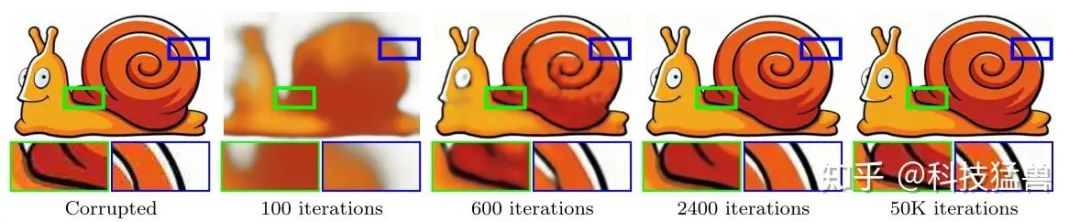
如下图所示,最左边是目标图像,它经过JPEG压缩,有很多压缩瑕疵。网络的目标是学会输出它。在100次迭代后,网络学会了输出很模糊的形体。在2400次迭代后,网络学会了输出一张清晰光滑的高质量图片。在50000次迭代后,网络才学会了输出原图。
不同任务的具体目标函数:
去噪:


超分:

其中, 


图像修复:

目的就是让未损坏的部分尽量去接近,训练出网络参数,根据自然图像的自相关性补出损坏的区域。结果表明,Deep Image Prior在text噪声和随机噪声方面很好,对于large-hole这种噪声,结果的好与坏与超参数很相关。


网络模型
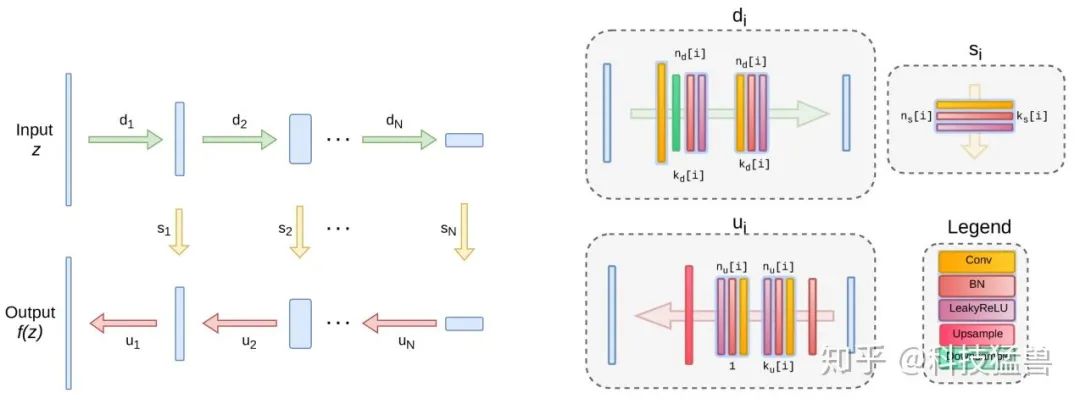


论文使用了LeakyReLU来作为激活函数,下采样是基于卷积调整stride来实现的,上采样方面,作者选择了双线性上采样和最近邻上采样。另一种上采样的方法是使用转置卷积,不过结果很差。另外,虽然可以针对每个任务都调整结构,甚至对每个图片都调整结构来达到最好的结果,但作者发现在一个大致的范围内,超参数和结构的实验表现都差不多。
下图展示了使用不同架构的结果:使用更深的随机网络可以获得更好的修复结果。然而,在U-Net中向ResNet添加skip-connection是非常有害的。

优缺点分析
Deep Image Prior的优点很明显:
(1)这个思路可以解决许多image restoration的问题(修复/超分/复原/去噪等)。
(2)思路简单, 就是利用网络结构本身的先验知识(先学nature-looking, 再学noise)。
(3)不需要原始图片,只需要一张退化的图片就足以完成训练。
缺点也很明显:
(1)速度慢。去噪的例子用了2400 iters 才跑出结果,根据作者的说法,512x512的图像,在GPU上要好几分钟才能出结果。
(2)不知道什么时候应该停止iteration, 训练到一定的iteration,生成的结果是需要的natural-looking的图像,但继续训练就会得到退化图,因为网络的最终目的是朝向退化图去的,而且目前尚没有有效的指标说明什么时候就得到较好的结果,所以这个尺度的把握很困难。
2. NAS Deep Image Prior
论文:https://arxiv.org/abs/2008.11713
被收录在 ECCV 2020,作者不是原班人马。
Deep Image Prior向我们证明了一个神经网络和的degraded image(待修复/超分/复原/去噪的图片)就足以解决以上的问题。在这篇工作的视角下,神经网络相当于是Prior。但是,不同任务使用人工设计的架构结果是次优的,所以本文借助NAS对这个架构进行搜索。
设计的搜索空间包含upsampling cell与skip connection连接是否存在,搜索算法使用了强化学习RNN controller,Reward是PSNR。
但是在Deep Image Prior工作中:作者发现在一个大致的范围内,超参数和结构的实验表现都差不多,为什么还要再用NAS这里比较牵强,但也说得通。
作者将典型的上采样操作分解为两个步骤:
改变空间分辨率的方法(例如双线性、双三次或最近邻上采样)。
特征转换方法(例如,二维卷积或二维转置卷积)。
实验结果表明,与传统的神经网络结构相比,搜索上采样单元和跨层特征连接可以提高性能。
本文的核心contribution:为每个任务寻找一个新的upsampling cell,在多数image restoration tasks任务上与learning-free approaches相比取得了最优的性能。
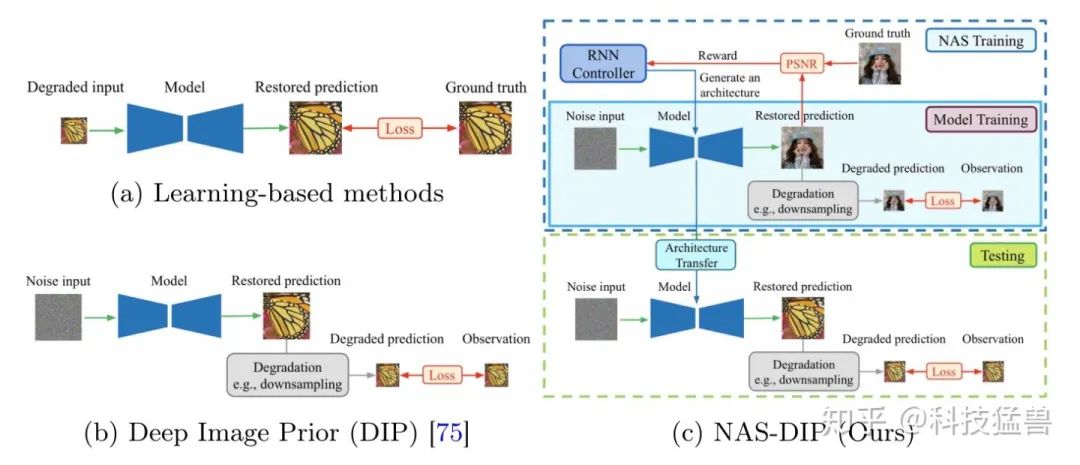
具体的工作流程如下图所示:先使用NAS搜索出最优的网络架构(蓝色框),再对搜索出的架构重复Deep Image Prior的所有步骤(绿色框)。
搜索最优的网络架构
首先从训练集中拿一张图片 
超分SR:
,降采样。
去噪denoising:
,加噪声。
修复inpainting:drop certain pixels。


采样随机编码 
根据目标函数 
此时我们有真值 


测试搜索的网络架构
得到了
搜索空间
upsampling cell
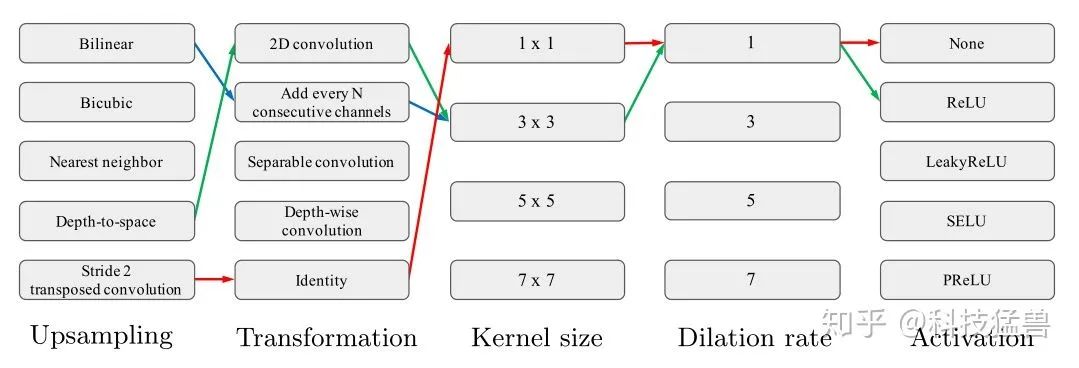
上采样的操作类型包括:bilinear upsampling, bicubic upsampling, nearest-neighbor interpolation, depth-to-space, stride 2 transposed convolution。
特征变换的操作类型包括:2D convolution, add every N consecutive channels, separable convolution, depth-wise convolution, identity。
Cross-scale residual connections
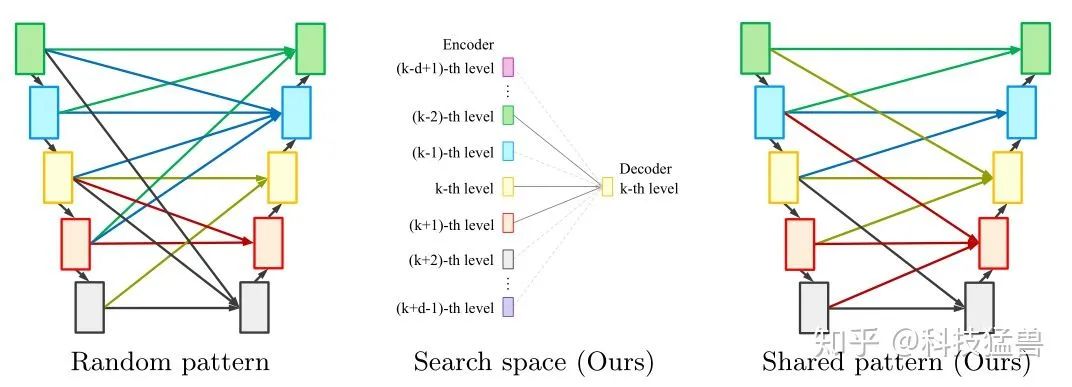
不同于U-Net的只在相同特征上进行skip-connection,作者允许进行跨层的连接。
跨尺度连接的搜索空间是很大的,假设encoder和decoder各有 

一个权重共享的办法:Progressive upsampling
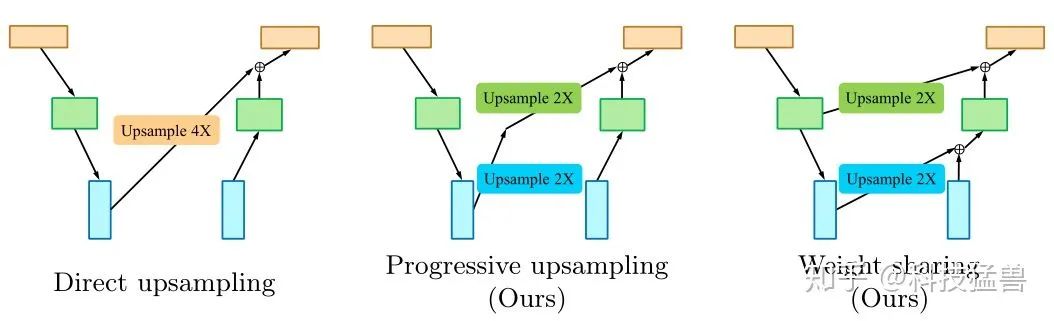
对于跨尺度上采样操作,如上图所示,我们建议将左侧的4×上采样操作解耦为中间两个连续
的2×上采样操作,并在同一特征级别上与右侧的2×上采样操作共享权重。这使得我们只需在
每个连续的特征层之间定义2×上采样操作,所有其他可能的上采样尺度都可以通过将它们解
耦为一系列2×上采样操作来实现。交叉比例下采样连接可以类似地实现。
缺点:
强化学习的方法,流程是(采样架构,训练,评估性能)循环,无疑会消耗大量计算资源,复现困难。
在Deep Image Prior工作中:作者发现在一个大致的范围内,超参数和结构的实验表现都差不多,那为每个任务寻找一个新的upsampling cell究竟有多大的意义值得商榷。
跨尺度连接的设计讲的不清楚,原文略微自相矛盾。
下载1:动手学深度学习
在CVer公众号后台回复:动手学深度学习,即可下载547页《动手学深度学习》电子书和源码。该书是面向中文读者的能运行、可讨论的深度学习教科书,它将文字、公式、图像、代码和运行结果结合在一起。本书将全面介绍深度学习从模型构造到模型训练,以及它们在计算机视觉和自然语言处理中的应用。

下载2:CVPR / ECCV 2020开源代码
在CVer公众号后台回复:CVPR2020,即可下载CVPR 2020代码开源的论文合集
在CVer公众号后台回复:ECCV2020,即可下载ECCV 2020代码开源的论文合集
重磅!CVer-论文写作与投稿交流群成立
扫码添加CVer助手,可申请加入CVer-论文写作与投稿 微信交流群,目前已满2300+人,旨在交流顶会(CVPR/ICCV/ECCV/NIPS/ICML/ICLR/AAAI等)、顶刊(IJCV/TPAMI/TIP等)、SCI、EI、中文核心等写作与投稿事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如论文写作+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
整理不易,请给CVer点赞和在看!



