微博情绪分析评测(SMP2020-EWECT) 参赛总结

转载自知乎账号 白胡子小生
地址 | https://zhuanlan.zhihu.com/p/222138885
机构 | 苏州大学 SUDA-HLT
作者 | Ting
编辑 | 机器学习算法与自然语言处理公众号
前言
我们是“炬火”,在此次评测中B榜第6,三等奖。本文除介绍我们自己的竞赛方案外,还将总结其它获奖队伍的技术报告,并对此类竞赛给出个人意见。本文联合作者: @thinking慢羊羊
直达链接:
官网:https://link.zhihu.com/?target=https%3A//smp2020ewect.github.io/
获奖队伍技术报告:https://link.zhihu.com/?target=https%3A//github.com/smp2020ewect/smp2020ewect.github.io/tree/master/reports
获奖队伍PPT(密码ast3):https://link.zhihu.com/?target=https%3A//pan.baidu.com/s/1kxHqM4SXtxDTKkLKpX1ibQ
炬火 开源代码:https://link.zhihu.com/?target=https%3A//github.com/thinkingmanyangyang/smp-ewect-code
目录
竞赛简介
我们的方案
其它队伍的方案
总结
温馨提示
1. 赛事简介
此次比赛报名队伍共189支,其中刷榜队伍有77支,提交最终结果的队伍仅42支
SMP2020微博情绪分类技术评测(The Evaluation of Weibo Emotion Classification Technology,SMP2020-EWECT)共包含两类数据集,分别是通用(usual)与疫情(virus),这两类数据集都包含六类情绪,积极(happy)、愤怒(angry)、悲伤(sad)、恐惧(fear)、惊奇(surprise)和无情绪(neural)。
1.1 数据详情

通用数据集:该数据集内的微博内容是随机获取到微博内容,不针对特定的话题,覆盖的范围较广。
疫情数据集:该数据集内的微博内容是在疫情期间使用相关关键字筛选获得的疫情微博,其内容与新冠疫情相关。

可以看出,usual和virus虽然在主题上有较大差异,但同种情绪下的样例有着一定的相似性
1.2 类别分布
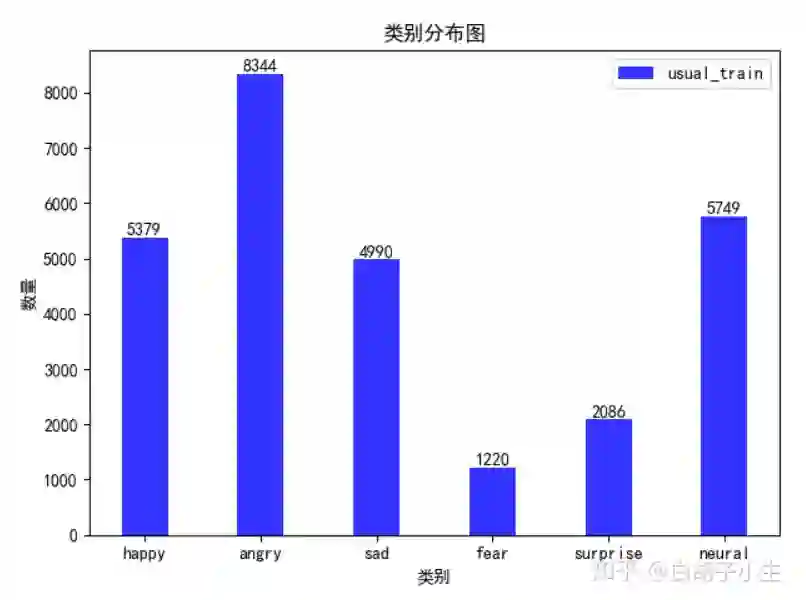
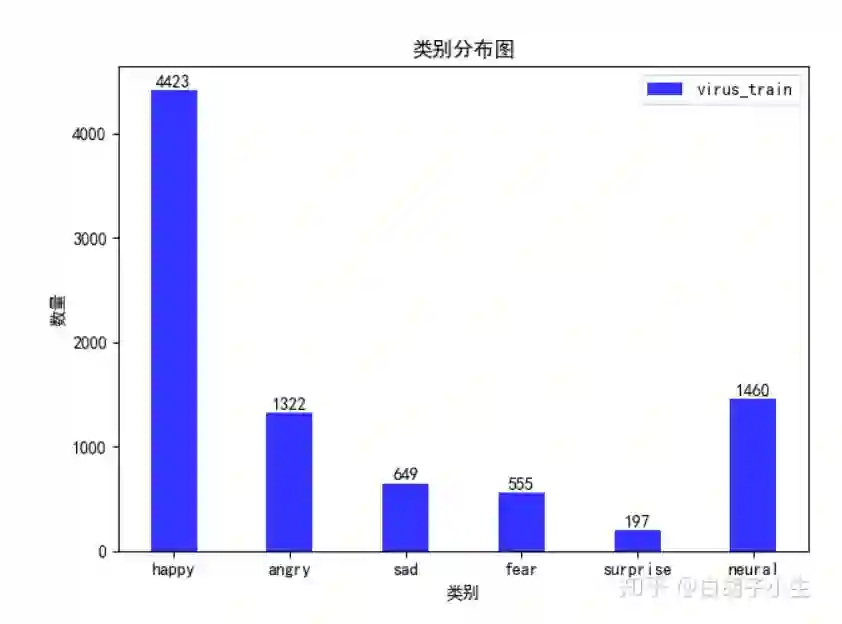
从上述两图可以看出,两类数据集都存在数据不平衡的情况,其中virus更加严重
1.3 评测指标
本次评测以宏平均F1值作为评测指标,最终对通用微博测试集的测试结果和疫情微博的测试结果进行平均,作为最终的测试结果,即:

2. 我们的方案
2.1 数据预处理
2.1.1 数据清洗
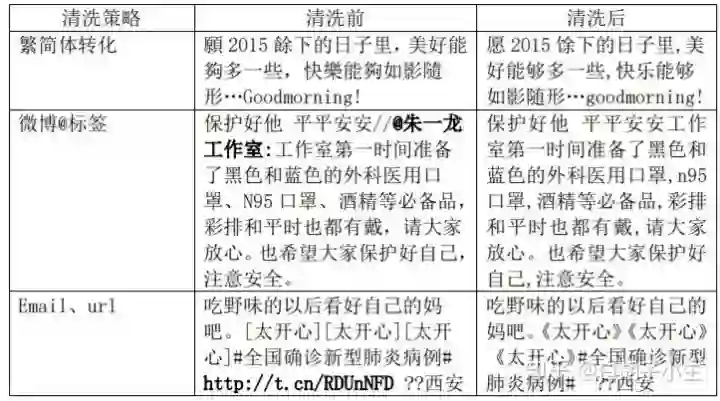
我们进行了全角转半角、繁转简、英文大写转小写、去除url、去除email、去除@以及保留emoji等操作,下表展示了部分清洗数据,在模型处理中,我们限制数据的最大长度为140。
2.1.2 数据扩充
virus的训练数据只有usual的1/3,我们考虑对它进行数据扩充,我们尝试的策略有eda、上采样,但在验证集上指标没有提升,故弃用。
2.2 模型结构
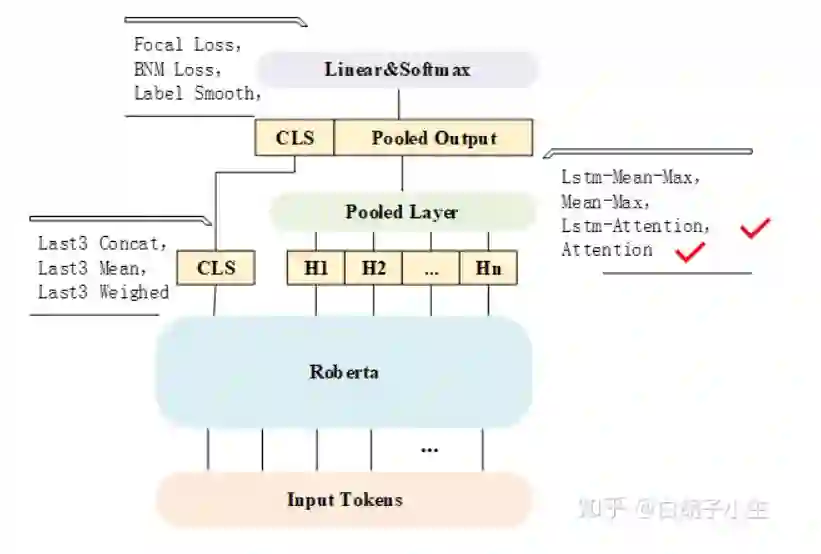
模型的主体结构借鉴自“2019 CCF BDCI”冠军团队(“我们都上哈工深”)的方案,usual和virus共用这一结构,我们主要对三方面进行了调整,分别是CLS、pooled layer、output layer,经过一番比较后,我们最终选择了 最后一层的CLS,LSTM-Attention/Attention,Cross Entropy loss 。
2.3 其它技巧
2.3.1 FGM对抗学习
这是在embedding vector上添加一个扰动,增强模型的泛化能力,计算公式如下:
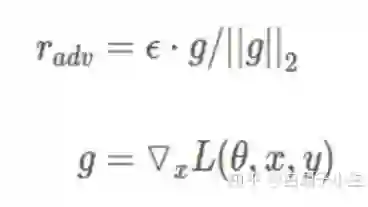
其中g是embedding vector的梯度,我们设置epsilon为1.0, 详情点这里(附插件式pytorch代码)
2.3.2 伪标签(pseudo)
用训练好的virus模型去标注virus 验证集,随机选取部分添加到训练集中,有一定效果。
2.3.3 k折训练与集成
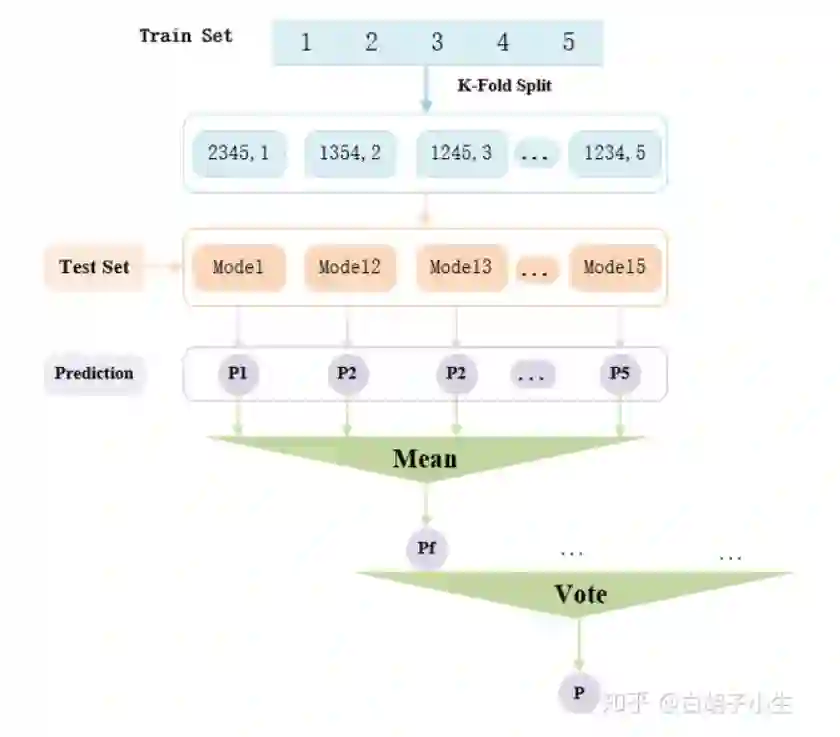
我们默认使用5折训练,对每一个模型采用5折输出结果的均值作为最终结果,对所有模型进行简单投票集成。
2.3.4 迁移学习
我们用训练好的usual模型的encoder参数初始化virus模型的encoder参数,其它保持不变,有效提升了virus模型的性能,我们认为更大规模的usual训练数据使得encoder能够更好地处理文本的语言结构,另外由于疫情微博数据与通用微博数据的内在相似性,使得encoder能够迁移使用。
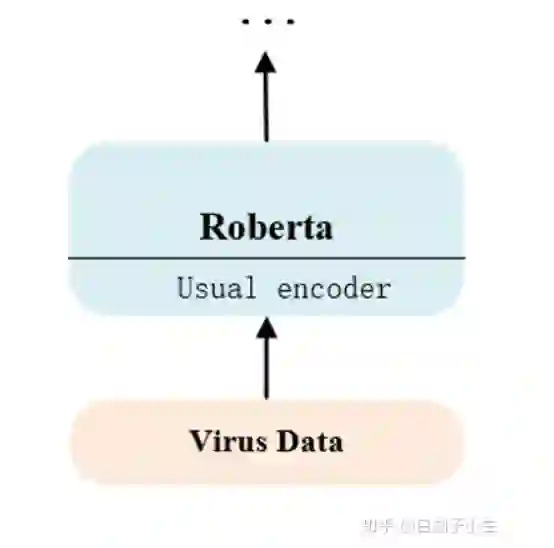
除了迁移encoder参数,我们还尝试过迁移完整的usual参数,但在验证集上指标没有提升,遂弃用。
2.4 实验结果

上下两表的结果都是在k折训练(默认5折)中随机划分的dev上的平均性能,所有实验都是在FGM对抗训练、数据清洗的基础上进行的

roberta_large的结果要优于roberta_wwm_ext_large,但由于我们之前实验的疏忽,之后的实验依旧在roberta_wwm_ext_large的基础上进行,迁移学习(transfer learning)都是在base上做的,没有用large是因为后期算力和时间不充裕。
3. 其它队伍方案
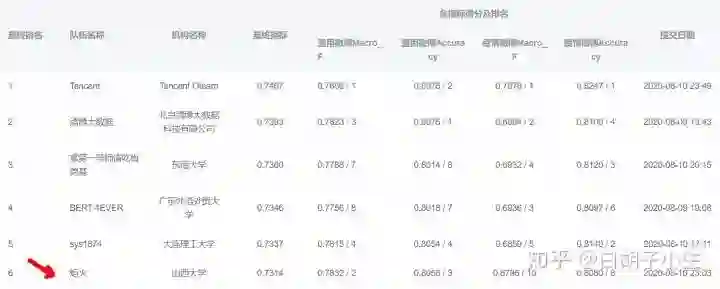
3.1 No.1 Tencent
3.1.1 数据预处理
原始数据中带有大量的标记,对分析文本的情感倾向没有帮助(例如用户 ID,转发标记、URL 等),于是利用正则表达式过滤以上标记,并且将 emoji 表情翻译成中文释义。

在后续的训练中,同时使用了经过预处理和不经过预处理的数据作为模型输入。
3.1.2 模型结构
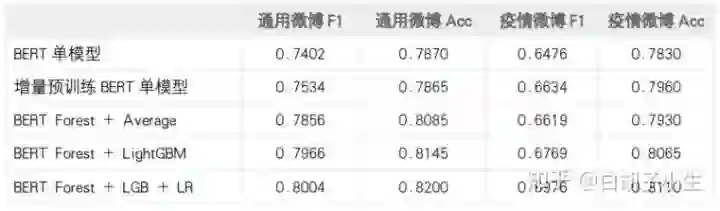
通过随机选择和组合不同技术(如图 6所示),得到大量性质不同的分类模型,进行模型集成。这种方法能够以很少的人力成本,持续地堆积模型,增加系统的参数量。最终训练了数百个分类模型,得到了超过 3000 亿(1TB)参数的系统。由于这项技术主要围绕着 BERT展开,因此我们把这个系统叫做 BERT forest 。
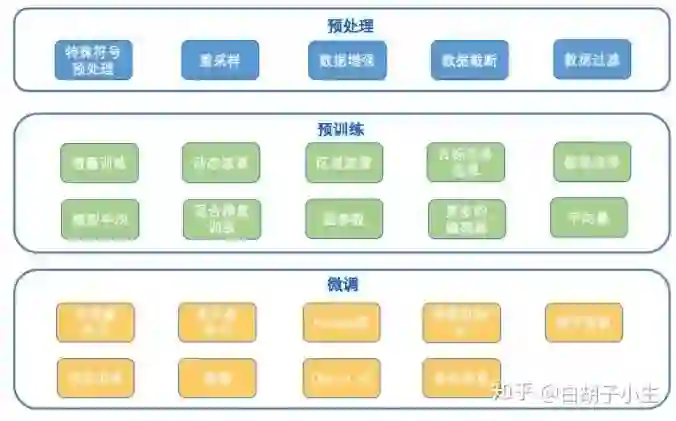
Tencent从模型池(下表)中选取预训练模型进行微调和增量训练(上表),此外还使用了 LSTM、GPT、Gated CNN等模型,基于这些模型,随机组合了文本长度、损失函数、对抗训练等训练策略(上表),为 usual 和 virus 分别提供超过 300 个基模型特征用于 stacking 融合学习。
3.1.3 算法框架
要组合这么多策略,没有一个好用的算法框架是很费劲的,Tencent选择自研的UER框架,可以快速复现大量模型。
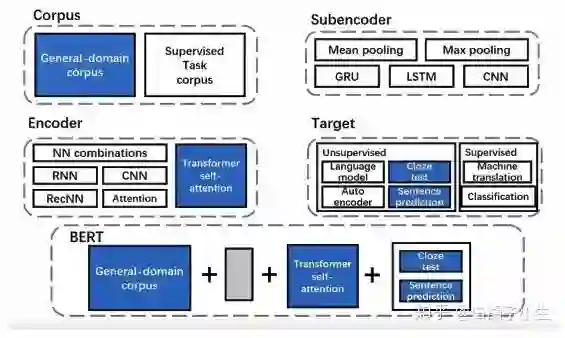
通过选取不同的组件,Tencent可以快速复现Bert模型,通过修改组件以及组合方式,即可完成模型创新
3.1.4 模型融合
Tencent框架使用 4 层模型,3 次融合的方案,在第一层使用大量预训练模型作为基模型特征,第二层使用 LightGBM 作为次模型特征,第三层使用 Linear Regression 之后平均作为最终结果。
具体步骤见Tencent技术报告
3.1.5 实验结果
3.2 No.2 清博大数据
3.2.1 模型结构
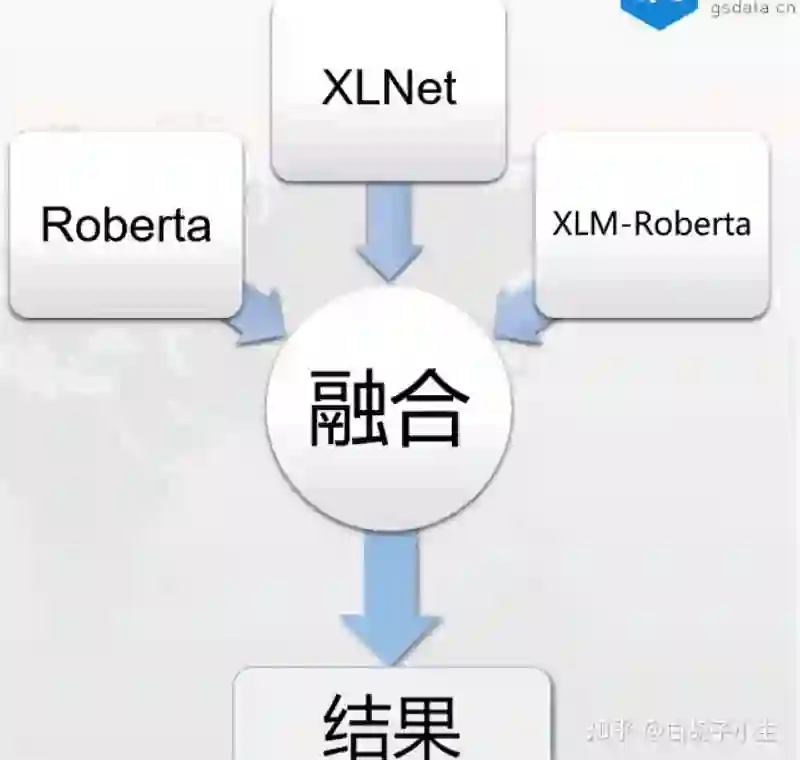
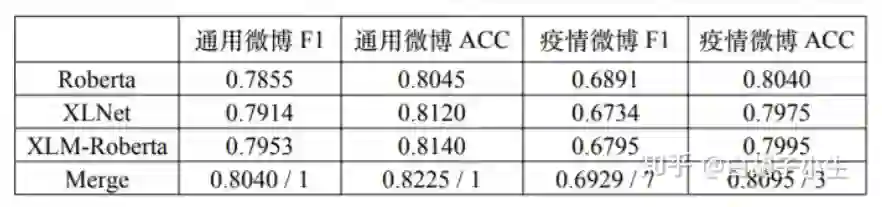
针对不同的数据,分开训练两个模型,这两个模型都采用了三个相同的预训练模型(Roberta、XLNet、XLM-Roberta)构建了六个 fineturn 结构相同的模型,通过调参和调整模型输入来获得最好的单模型效果。
3.2.2 预训练
清博大数据使用疫情期间网民情绪文本,共 1820606 条,对Roberta 模型进行了动态掩码(dynamic Masking)任务的训练,得到了针对疫情的预训练模型。
3.2.3 训练方法
迁移学习:在训练好的适用范围更广的通用模型的基础上,加入疫情标注数据对模型进行适应性训练,相比于在不足一万的疫情数据集上训练得到的模型,这种方式大大增加了模型的泛化能力。
数据增强:使用BERT的MaskedLM能力,对文本中的 Token 随机进行遮挡预测,并选取可能性最大的两个预测结果替换原文中的 Token,最终从一个文本中获得多个生成文本,并控制总体的数据比例,减少数据不均衡带来的影响。但预测结果不是很符合语言规律,导致性能下降,弃用。
k折训练:默认9折
预处理:使用不同预训练模型时,对输入做了不尽相同的预处理,例如微博昵称的去除和文本内网址的去除,详见代码。
处理数据泄露:验证集中存在100条左右训练集中的数据,预测不一致的有4条,使用训练集的标注结果进行修正,验证集分数有一定提升。
类别加权:每一个模型训练好之后,对输出的6维向量进行加权得到最终结果。
模型融合:概率加权(相同的预训练模型)、加权投票(不同的预训练模型,每个模型在验证集上的得分作为投票权重)
3.2.4 实验结果
3.3 No.3 拿第一导师请吃肯德基
3.3.1 模型结构
3.3.1.1 usual
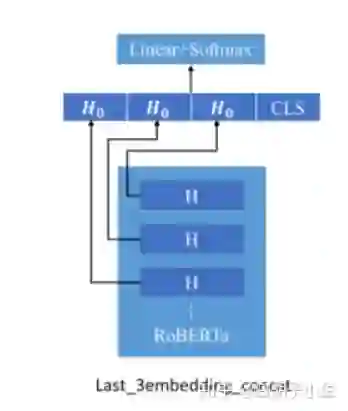
尝试过Last_3embedding_concat、Last_3embedding_meanmax、LSTM_MaxPool、LSTM_RCNN、Last_2embedding_concat,根据实验结果,最终选取Last_3embedding_concat,并且由于模型融合效果不佳,通用微博模型最终选用该单模型
3.3.1.2 virus
首先使用usual数据集在预训练模型 RoBERTa 上进行训练,将获得的预训练模型参数作为virus模型的初始权重,然后通过相同方式在不同的模型结构上进行训练,最终选取线下结果较优的多个单模型进行 Stacking 集成,获得了较好的效果。
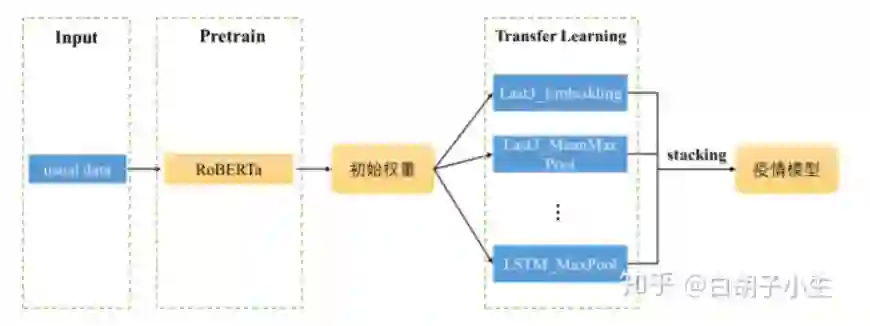
3.3.2 其它技巧
k折训练:usual使用6折(由对比实验得出),virus使用5折。
多层学习率 & 学习率衰减:任务预测层(Task Specific Layer)学习率使用 1e-4,预训练模型内部学习率使用 1e-5,且内部学习率随层数降低逐步衰减。
类别不平衡:数据处理(同义词替换、过采样、欠采样)、训练过程(标签平滑、focal loss)、后处理(F1指标优化),实验表明F1指标优化对最终预测结果有较大提升。
FGM & multi-sample-dropout:无明显提升。
预训练:尝试使用通用微博数据进行领域预训练,通过情感极性微博数据集进行相关任务预训练,最终结果并未有明显提升。
F1值优化:在多分类求解求解时,一般使用argmax(logits)获得最终类别,对此可以修改为argmax(w * logits),并且在验证集上进行非线性优化得到权重w
3.3.3 实验结果
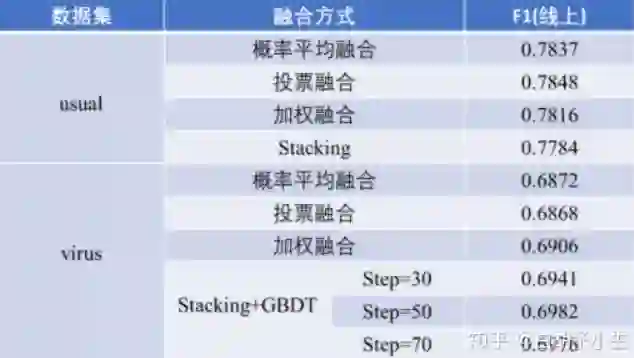
usual:模型融合效果不理想,最终采用最优单模型作为提交结果。
virus:使用stacking+GBDT方法对多模型进行集成融合。
3.4 No.4 BERT 4EVER
3.4.1 模型结构

对比了 RoBERTa-WWM-Ext、BERT-WWM-Ext、Erine 和 SKEP 四个模型的表现性能,最终选择roberta_wwm_ext作为baseline
3.4.2 其它技巧
3.4.2.1 预训练(信息增强)

将usual和virus合并用于初训练模型,之后在各自数据集上重新训练模型
3.4.2.2 数据增强
随机遮掩:随机将语句中部分词语替换成符号
同义词替换:随机将语句中部分词语替换成对应的同义词
伪标签:用标注语料训练好一个模型,再用这个模型去预测未标注语料,将得到的数据也用于训练模型
回译:中->英->中
3.4.2.3 模型融合
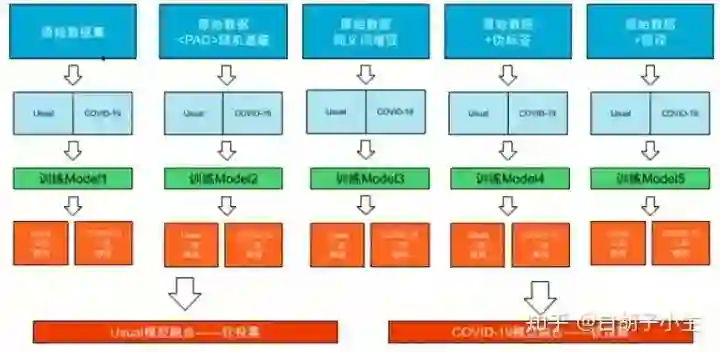
软投票:对模型的输出结果取平均
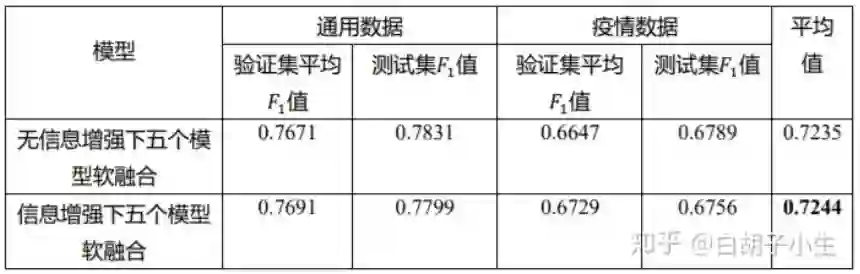
3.4.3 实验结果
3.5 No.5 sys1874
3.5.1 训练策略
baseline:roberta_large + linear + tanh + linear
特征融合:考虑到有些语句的情感词比较明显(例如愤怒、悲伤等,对应浅层语义),而有些则比较内敛(对应深层语义),因此该团队把解码器隐藏层中第10、15、20 以及最终的输出(24)层的特征取出。
模型融合:对于通用微博以及疫情微博,分别训练了 10 个和 6 个相同结构的模型,最终结果为这些模型预测结果的平均。
3.5.2 实验结果
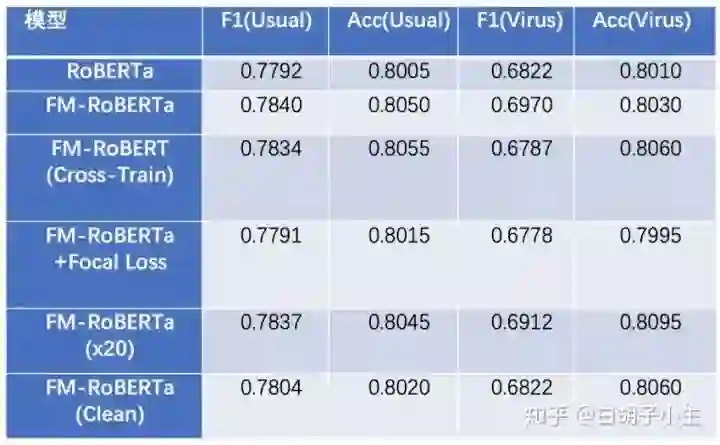
FM-Roberta: 采用了特征融合
FM-Roberta(cross train):在使用各自数据训练模型后,再用对方数据训练各自模型作为最终模型
FM-Roberta( x20 ):使用20组模型进行集成,取这些模型预测结果的平均
FM-Roberta(clean):去除人名、微博id等
4. 总结
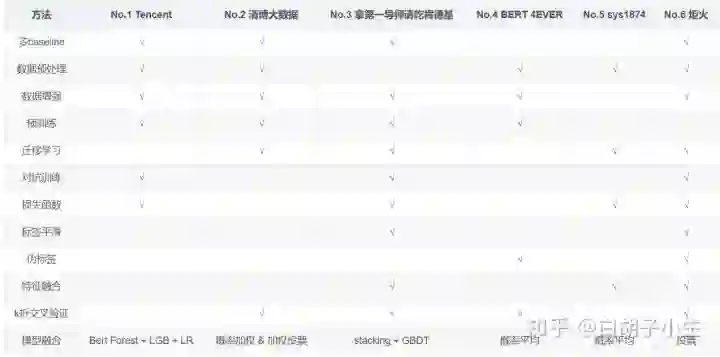
√ 表明该参赛队伍尝试过该方法,但未必有效
以上所述并未完全覆盖各队伍参赛技巧
5. 温馨提示
进行多baseline对比,根据队伍实力挑选合适的baseline个数,另外请仔细调好baseline的参数
调试模型较为费时,而且并非每个技巧都能带来性能上的提升,但在模型融合时可以提高模型泛化性能
竞赛注重参赛者的trick以及调参能力,并不一定要参赛者针对某一问题提出创新性的解决方案(当然能提出就更好了)
比赛过程中,请详细记录模型改动、实验条件以及实验结果,这对于指导模型改进 & 赛后复盘至关重要
对于大多数队伍而言(这次比赛中,Tencent除外),常规的思路是通过深入理解数据集以及大量的消融实验,进而验证不同技术和技术组合的有效性,并对多个高质量的模型进行集成,这要求参赛者有足够的耐心,能够坚持到比赛结束
6. 关于我们
苏州大学人类语言技术研究所(Institute of Human Language Technology, Suda-HLT),所长是国家杰出青年科学基金获得者、苏州大学计算机学院院长张民教授,研究所主要从事自然语言分析、知识图谱构建、机器翻译等方向的研究,在顶级国际会议(ACL、EMNLP、AAAI、IJCAI、COLING)上发表过多篇论文。本研究所拥有非常好的科研氛围和环境、丰富的软硬件资源、民主自由的团队氛围,欢迎志同道合者加入我们。同时也可以关注我们的知乎专栏“suda-hlt”,我们正在完善该专栏。
比赛的另一位主要合作者来自东北大学数据挖掘课题组,组内主要有王大玲,冯时,张一飞三位老师,课题组以社会媒体为平台,以其中的多模态资源和各类用户为数据源,研究社会媒体资源与用户及其关系的表示、挖掘、搜索和推荐,基于人机情感交互的对话系统等,在CCF A/B类会议(ACL,WWW,IJCAI等)发表过多篇论文。
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏