【情感分析】ABSA模型总结(PART I)

0. 写在前面
前面我们有实战过文本分类的一些模型算法,什么?太简单?!Ok,再开一个坑,接下去整一个稍微复杂点的,情感分析。当然一般的情感分析也是一个分类任务,就可以参考之前文本分类的思路,我们这一系列要看的是「Aspect Based Sentiment Analysis (ABSA)」,关于这一任务的比赛也非常多,可见十分实用呀。enjoy

1. A glance at ABSA
在介绍具体算法之前,先来看一下什么是 ABSA?可以粗暴翻译为基于方面的情感分析,本质就是对句子中不同对象可能会存在不同的情感倾向,例如:“I bought a new camera. The picture quality is amazing but the battery life is too short”,这句话中对于target=picture quality,情感是正的;而对于target=battery,情感就是负的了。ABSA 任务的目的就是去找出给定句子中的不同 target 的情感倾向。
如果大家还不是很清楚的话,可以再参考一下这里:「一个关于ABSA的PPT介绍[1]」。
Effective LSTMs for Target-Dependent Sentiment Classification(COLING2016)[2]
在这篇论文里面作者主要是介绍了三种基于LSTM的模型,来解决 ABSA 任务:
-
LSTM -
Target-Dependent LSTM -
Target-Connection LSTM
2.1 LSTM
第一种方法就是直接使用 NLP 中的万金油模型 LSTM,在该模型中,target words 是被忽略的,也就是说跟普通的对文本情感分析的做法没有区别,最终得到的也是这个句子的全局情感,可想而知最后的效果一般般。具体做法就是对句子中的 token 进行 embedding 处理作为模型的输入,经过一次一次的计算隐层和输入之后得到一个句子表示 ,接着对这个向量进行 softmax 计算概率, 其中 C 是情感类别种类。
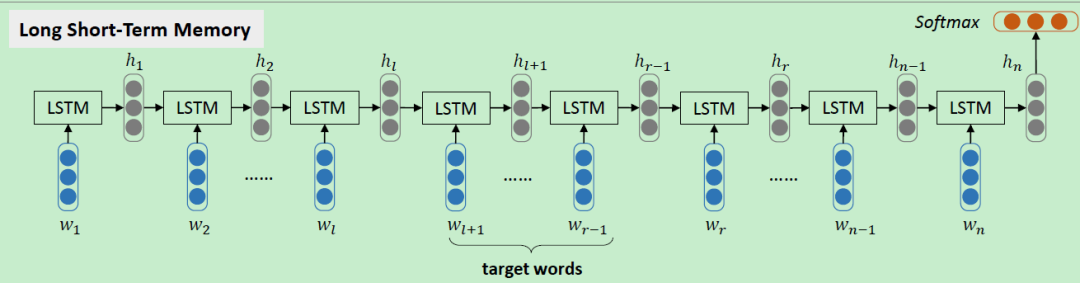
2.2 TD-LSTM
为了解决上面 LSTM 忽略目标词的问题,提出了 Target-Dependent LSTM (TD-LSTM) 模型,如下图所示。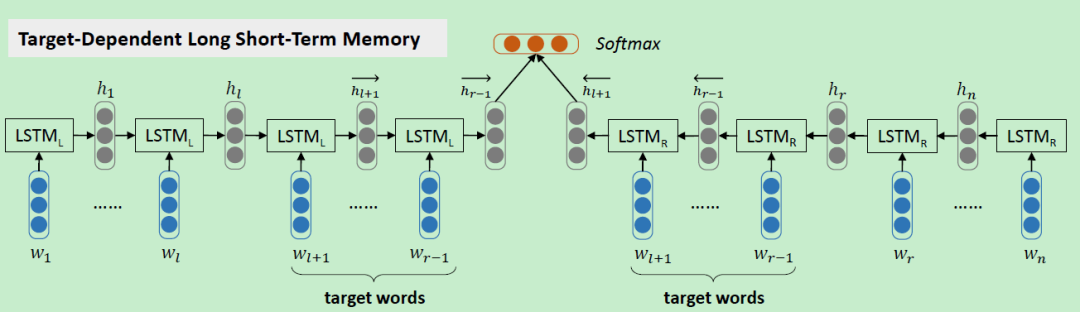
2.3 TC-LSTM
Target-Connection LSTM (TC-LSTM) 在 上一节TD-LSTM 的基础上进一步加强了 target-word 与句子中每个 token 的关联,看模型框架就会很清晰,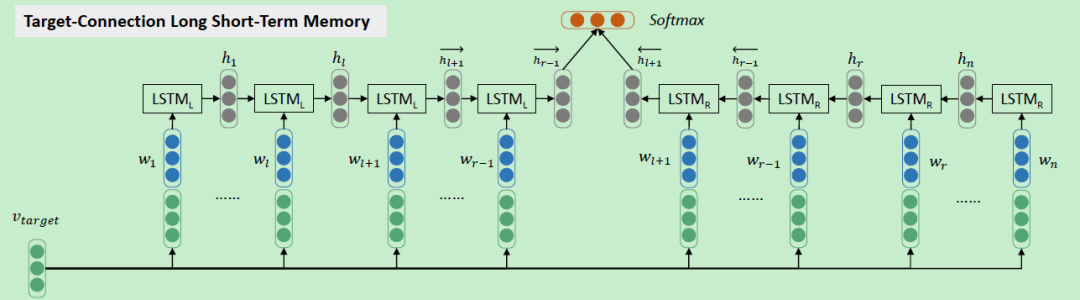
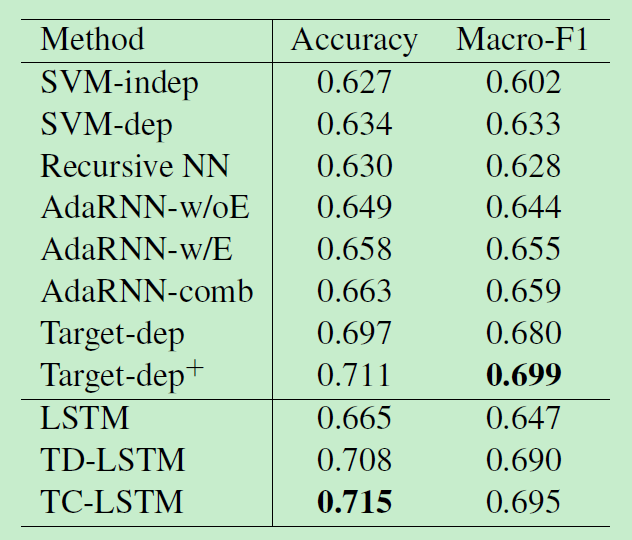
2.4 实验结果比对
Attention-based LSTM for Aspect-level Sentiment Classification(EMNLP2016)[3]
这是在上一篇论文之后发的文章,指出前者的不足之处:
❝However, those models can only take into consideration the target but not aspect information which is proved to be crucial for aspect-level classification.
作者这里提到了两个概念:target 和 aspect。我们可以认为 target 是包含在句子中出现的词,而 aspect 属于预先定义的比较 high-level 的类别刻画。基于以上,提出了两种模型:
-
Attention-based LSTM (AT-LSTM) -
Attention-based LSTM with Aspect Embedding (ATAE-LSTM)
3.1 Aspect Embedding
对于 ABSA 问题,aspect 信息对于最终的情感判别是非常重要的。因此作者对每个 aspect 都学习一个相应的 aspect embedding 来表示,
3.2 AT-LSTM
我们已经学习出了 aspect embedding,那么如何把它结合进模型里呢?这里使用的是超级火的注意力机制,如下图所示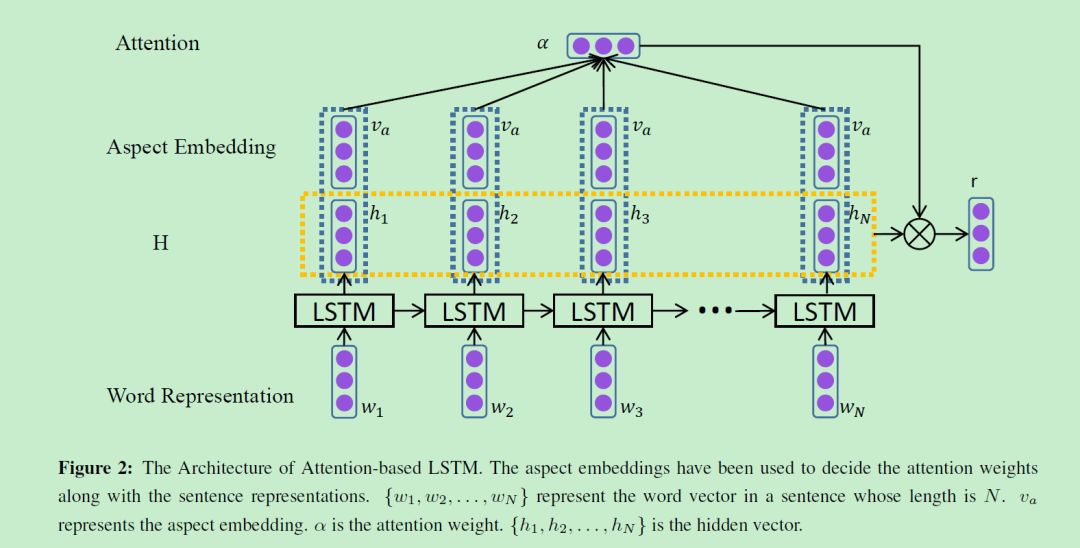
key=H, value=H, query=aspect embedding,整个 attention 的过程可以用数学表示为:
其中 r 表示各 hidden state 带权重后的表示,然后最终句子的表示为:
得到句子的表示后再进行情感分析:
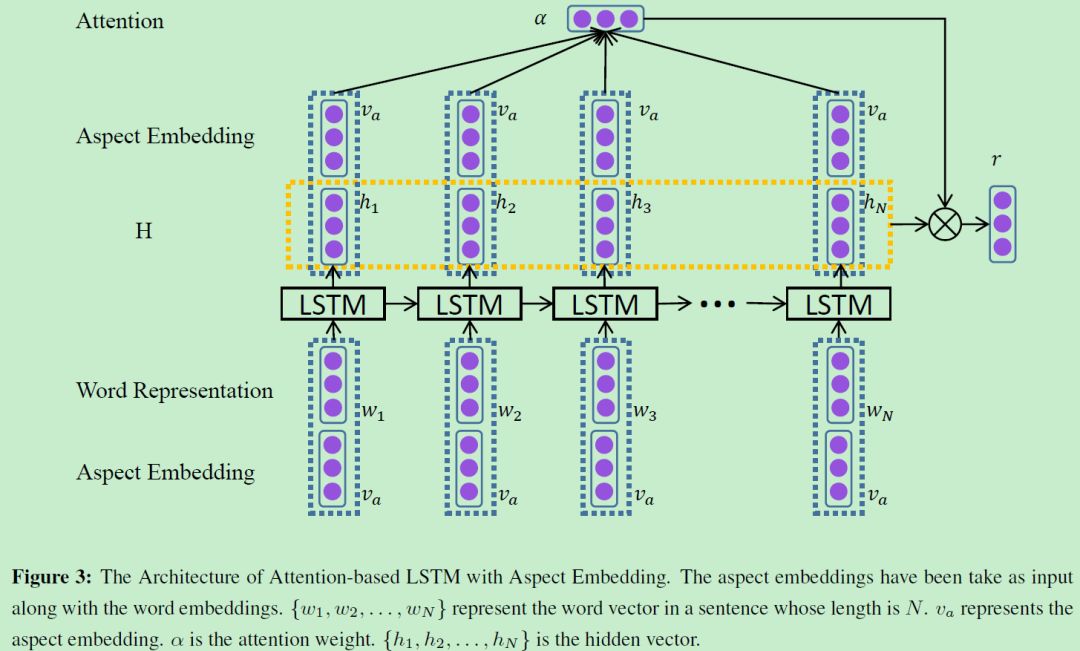
3.3 ATAE-LSTM
为了进一步利用 aspect embedding 的信息,类似于上一节中 TC-LSTM 中的思想,即将 aspect embedding 与 word embedding 共同组合成模型的输入。模型的其他部分与 AT-LSTM 相同。
3.4 注意力结果可视化

3.5 试验分析
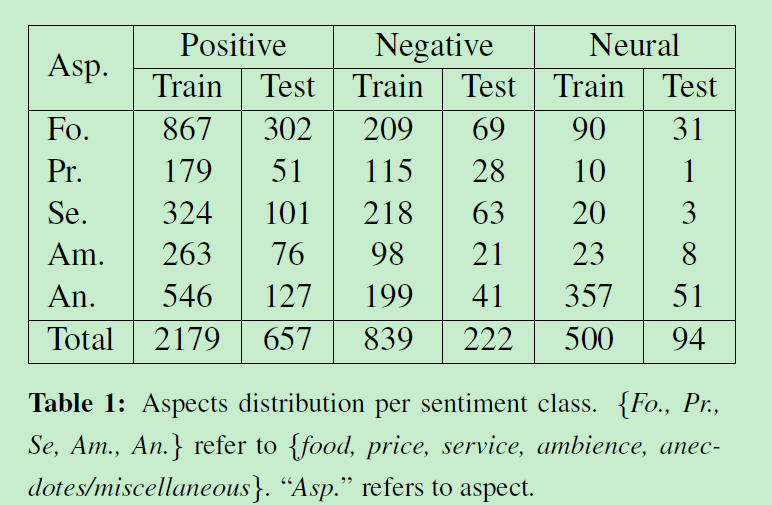
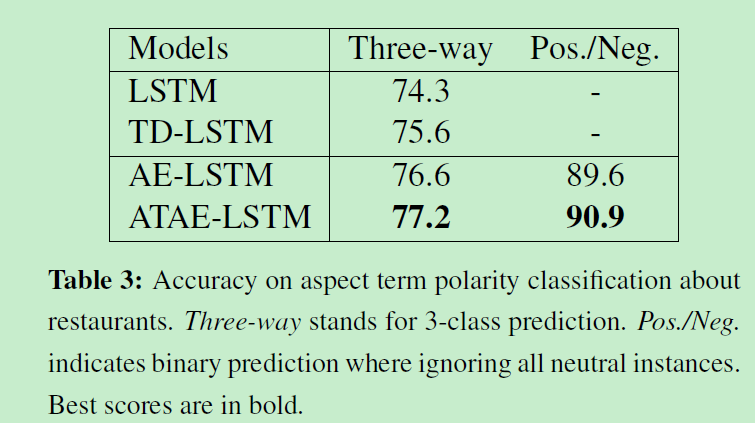
论文使用的数据集是 SemEval 2014 Task 4[5]。
Learning to Attend via Word-Aspect Associative Fusion for Aspect-based Sentiment Analysis(AAAI2018)[6]
对于上一节的 ATAE-LSTM,作者认为仍然存在以下不足:
-
不是让注意力层专注于学习上下文词的相对重要性,而是给注意力层增加了对aspect和上下文词之间的关系进行建模的负担; -
除了对顺序信息进行建模之外,LSTM的参数现在还承担了额外的负担,即,它还必须学习aspect和单词之间的关系。ATAE-LSTM中的LSTM层在一个由sapect embedding主导的序列上进行训练,这将大大增加模型的训练难度; -
简单的拼接会使ATAE-LSTM中LSTM层的输入加倍,这会增加LSTM层参数成本, 影响内存占用量,计算复杂性和存在过拟合风险。
针对以上提出了 Aspect Fusion LSTM (AF-LSTM),模型整体框架如下:
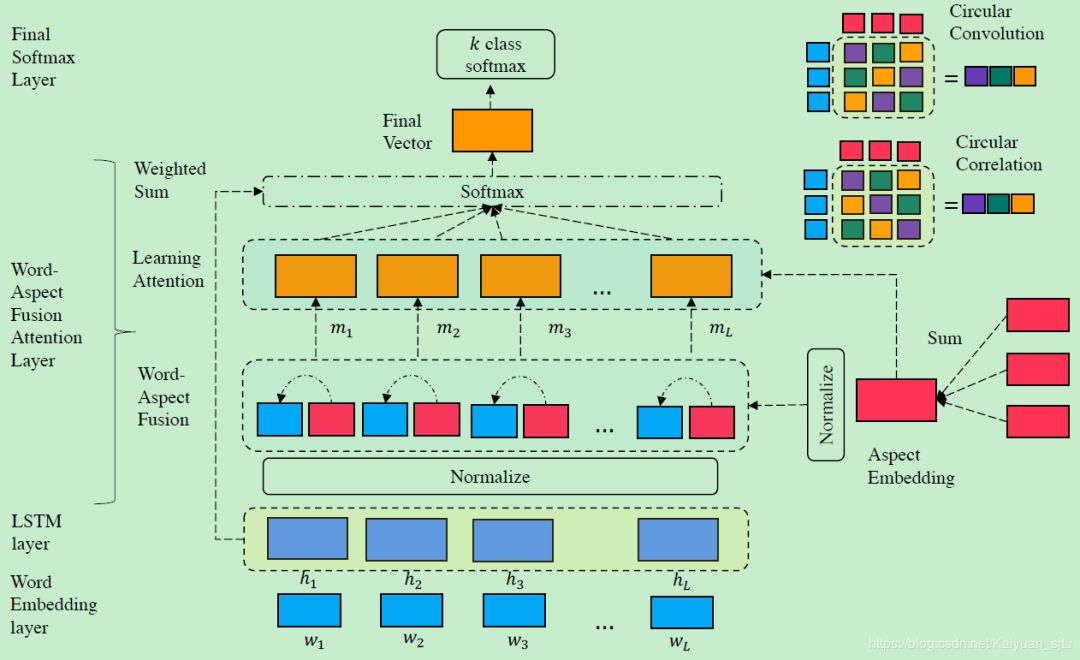
4.1 Word-Aspect Fusion Attention Layer
在输入经过 embedding 层和 LSTM 层之后进入到 Word-Aspect Fusion Attention Layer,这也是该模型的重点。
-
「Normalization Layer(optional):」 在隐状态矩阵和 aspect vector 进行交互之前可以选择性地对其进行正规化操作,可以选用 Batch Normalization;
-
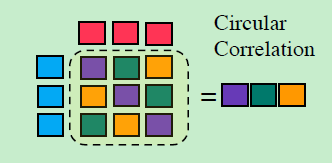
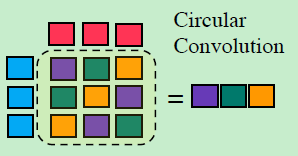
「Associative Memory Operators:」 用于计算 context word 和 aspect word 之间的关系。有两种:circular correlation 和 circular convolution
circular correlation
也可以用傅里叶变化得到:
3.「Learning Attentive Representations:」 将 aspect 和 context 进行 fusion 之后得到的向量表示进行 attention 操作
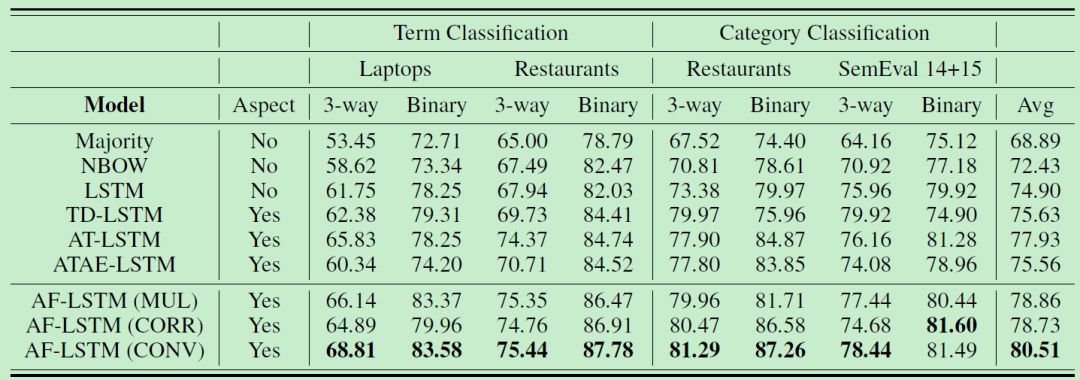
4.2 试验分析
Targeted Aspect-Based Sentiment Analysis via Embedding Commonsense Knowledge into an Attentive LSTM(AAAI-18)[1]
作者在对先前论文review之后给出了几个仍未解决的问题:
-
target包含多个实体或单词时,现有的研究都是认为各部分重要性一致并且简单地计算平均值作为向量表示; -
使用hierarchical attention建模得到的target和情感词之间的关联是一个黑箱; -
未引入包含更多信息的外部知识 -
全局的attention会编码与任务不相关的信息
对此,文章给出了三个解决方案:
-
创建多层attention模型来分别明确计算目标词(target)和整个句子; -
将外部知识引入传统LSTM网络; -
将常识性情感知识融入深层神经网络。
整体框架如下所示,主要包括两个组分:「sequence encoder」和「hierarchical attention」
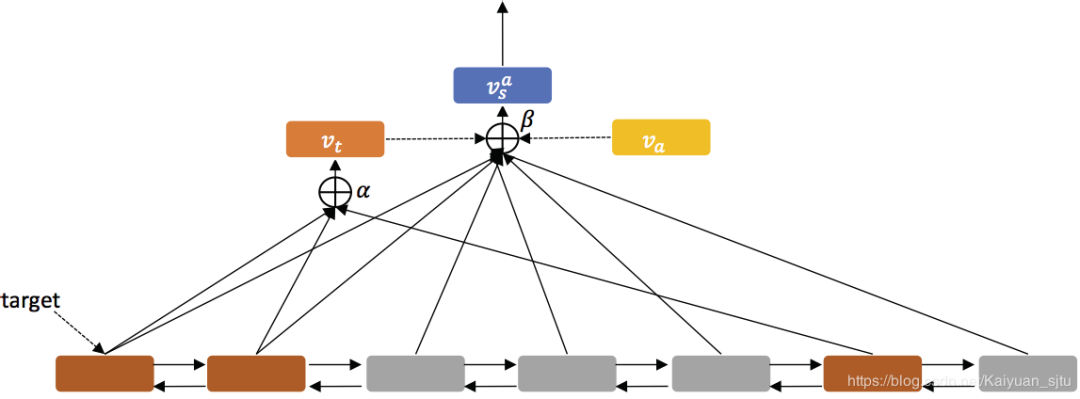
-
「word embedding:」 原始句子 变为向量表示 -
「sequence encoder:」 将向量送入双向LSTM得到每一个词的隐状态表示 -
「Target-Level Attention:」 对句子中的所有target实例(如上图中的棕色框框)做self-attention获得target word attention representation; -
「Sentence-Level Attention:」 把步骤3得到的target words attention 向量和步骤2得到的所有隐状态向量给contact起来,再做一次attention; -
「Output:」 将步骤4得到的attention向量经过一个dense层和一个softmax层,得到最终的分类概率输出。
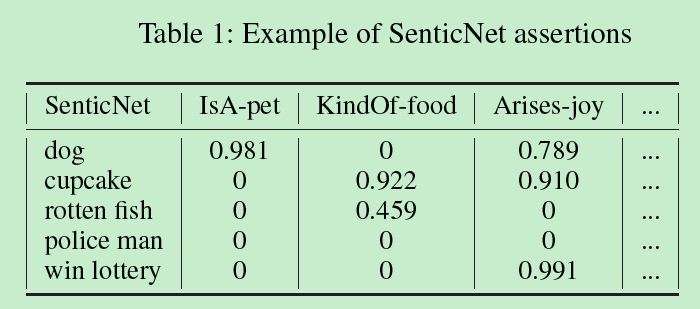
「Commonsense Knowledge:SenticNet」
引入外部知识库SenticNet,含有50000个实例,每个实例对应一系列情感属性。情感属性提供了每个实例的表示,也将各个aspect与其情感链接起来。
「Sentic LSTM」
为了能够有效利用secticnet,本文对LSTM做了延伸:输入门中情感概念的存在可以防止记忆细胞受到与已有知识冲突的输入标记的影响。同样,输出门使用这些知识过滤存储在记忆网络中的无关信息,调控模型是否使用情感知识。
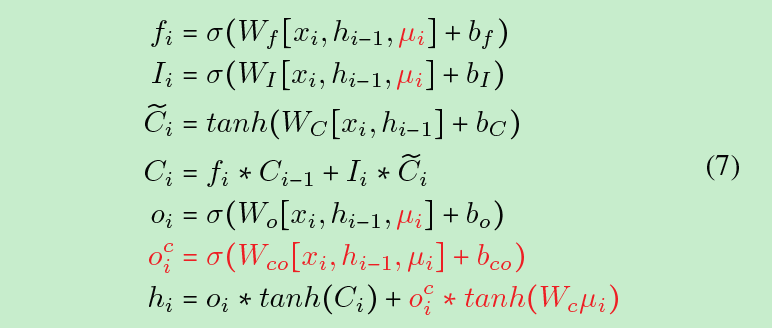
本集Over~期待马上会有的PART II.
本文参考资料
一个关于 ABSA 的 PPT 介绍: https://www.iaria.org/conferences2016/filesHUSO16/OrpheeDeClercq_Keynote_ABSA.pdf
[2]Effective LSTMs for Target-Dependent Sentiment Classification(Tang/COLING2016): https://arxiv.org/abs/1512.01100
[3]Attention-based LSTM for Aspect-level Sentiment Classification(Wang/EMNLP2016): https://www.aclweb.org/anthology/D16-1058
[4]理解 Attention 机制原理及模型: https://blog.csdn.net/Kaiyuan_sjtu/article/details/81806123
[5]SemEval 2014 Task 4: http://alt.qcri.org/semeval2014/task4/
[6]Learning to Attend via Word-Aspect Associative Fusion for Aspect-based Sentiment Analysis(Tay/AAAI2018): https://arxiv.org/pdf/1712.05403.pdf
- END -

推荐阅读
百度PaddleHub NLP模型全面升级,推理性能提升50%以上
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
From Word Embeddings To Document Distances 阅读笔记
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
可解释性论文阅读笔记1-Tree Regularization
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。





