【机器人】北大教授陈宝权:AI+三维视觉,让机器人具备决策和执行力

新智元报道
编辑:大明
【新智元导读】人类不仅可以通过眼睛“看清”周围环境中的东西,还能“识别并理解”这些东西,对这些东西形成“认知和决策”。现在,研究人员正努力让AI也做到这一点。北京大学博雅特聘教授、前沿计算研究中心执行主任陈宝权的这篇精彩演讲,对当前国内三维视觉智能领域研究概况、技术应用方向和未来前景做了精彩分析。
众所周知,人工智能是模拟人类智能的技术,实现对人类智能的完全再现,是人工智能的终极目标。而人类智能是从人类的感官和认知开始的。所以,人类的感官往往成为研究人工智能的入手点,比如视觉。
对于人类而言,不仅可以通过眼睛“看清”周围环境中的东西,还能“识别并理解”这些东西,对这些东西形成“认知和决策”。现在,越来越多的AI领域的研究人员正努力让AI同样做到这一点。从人类的三维视觉出发,三维视觉智能已成为人工智能研究和应用的热门领域。
在今年3月27日新智元举办的“智能云·新世界”AI技术峰会上,北京大学博雅特聘教授、前沿计算研究中心执行主任陈宝权发表了题为《三维视觉智能及应用》的演讲,从研究人员的视角,对当前国内三维视觉智能领域研究概况、技术应用方向和未来前景做了精彩的分析。
以下为新智元整理的演讲内容:

北京大学博雅特聘教授、前沿计算研究中心执行主任陈宝权
今天很高兴有机会能够在这里发表演讲!今天下午的讲者主要来自于企业,我就从学术研究的角度,对现在非常流行的人工智能技术的重要分支——视觉智能来做下介绍。
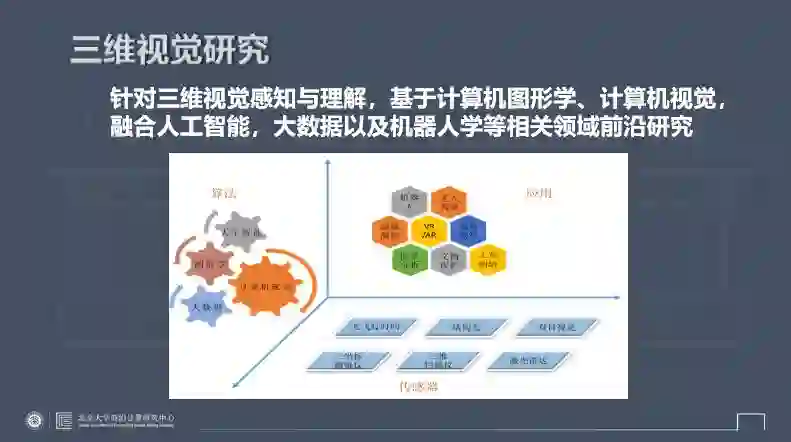
说到视觉智能,大家都不陌生,人工智能的很多技术是基于人的各种感观的,其中视觉感观就是非常重要的一环。在视觉智能方面的很多技术已经在工业界得到非常好的应用。随着应用的深入,越来越多的视觉智能技术进入“三维视觉智能”阶段。也就是说,我们的眼睛不仅要看清某个东西,认识某个东西,还要走到这个场景里面去,在三维世界里真实地感受场景,如同身临其境。

这就需要具有三维空间感知与认知能力的智能,即三维视觉智能。任何一个新的研究方向的出现都不是凭空而来,而是和许多其他学科交叉而来的。三维视觉智能的研究就是集合计算机图形学、计算机视觉等领域的技术与传统的人工智能、学习、大数据等很好地交叉融合。
三维视觉技术的发展得益于视觉传感器的快速发展,已经在推动很多应用,比较有代表性的包括无人车、机器人,以及娱乐、影视等其它领域的应用。
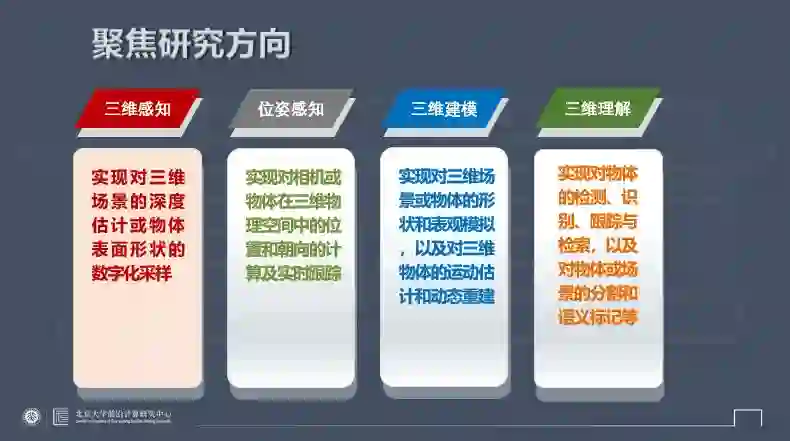
三维视觉研究什么?总结起来有几大主要方向:
首先是三维感知,也就是感知三维空间,获取和处理三维深度等;然后是位置感知,比如感知相机的位置等;第三是三维建模,不仅对场景有基本的深度感知,还要获得关于场景完整几何模型的描述。最重要的就是三维理解,对场景和其中的物体从三维空间来进行理解。

三维视觉的发展得益于视觉传感器的发展,而传感器大致可以分为两类,一类是被动传感器,现在我们用的各种相机就是被动传感器。另一类就是主动传感器,比如激光扫描,以及各类以主动发射信号为主导进行测量的传感器。大家知道,随着手机的快速发展,未来的手机会同时配备两类传感器,也就是深度传感器和传统的颜色传感器。

下面简要介绍一下我们在这方面的一些探索性工作。2009年,当时大疆无人机还做定制化产品,我们请大疆做了一台定制化无人机,目的用它来做倾斜角航拍,利用无人机从空中得到航拍影像,经过三维重建计算以后得到三维影像数据(注意,还不是完整的三维模型),有了三维描述就可以从任意视角自由地漫游场景。可以看到,尽管用的只是二维传感器,依然可以通过视觉计算得到三维数据的描述。
隐式三维感知:动态相机实现视频无缝接合
在我讲如何利用主动式传感器直接获得三维场景几何模型之前,我想先介绍一下,其实对于影像的三维感知不一定要以显式的方式表示出来,可以通过隐式的方法获得一定程度的三维感知,也能实现一些类比于直接采用三维信息才能实现的功能。

这个好比人的视觉感知,我们虽然对视觉的认知是三维的,但也不是一切基于精确的三维测量。这里举几个例子。比如,上面是电影里的一个片断,我们可以把其中的人物和表演放到一个新的场景里去,因为相机是动态的,这里就需要有一个隐式的相机三维位置恢复,才能把一个动态的前景和一个动态的视频背景无缝融合在一起。

上面是一段表演视频,我们可以提取它的一部分三维骨架信息,驱动一个不会跳舞的人来跳舞。左边的这个人假设不会跳舞,她只是做几个动作,右边大图里面左上角是真正会跳舞的舞者,我们用她的专业动作来驱动不会跳舞的人来跳舞。就是通过对“驱动”视频进行三维理解并“迁移”三维动作到参考视频中的人物而并合成新的视频,于是在右边大图里,这位女士也会跳舞了。

我们不仅可以把一个人的动作迁移到另外一位骨架类似的人身上,也可以把小孩的动作迁移到大人身上,甚至可以把动物的动作迁移到人的身上。这就需要具备一定的三维骨架重定向的能力。
比如,下面的动图中有两个人在跳舞,但是每个人的动作方向、脸部朝向、身高都有所不同。像这样一个运动的定向差值,都是通过隐式三维理解和编码实现的。


下面讲主动传感器的使用,近年来主动式传感的发展非常非常快。特别是无人车技术的发展要求,进一步推动了传感技术的飞速发展。早在无人车火爆之前,我们就于2009年开始采用车载移动激光扫描器来进行城市级别的大场景三维扫描,构建城市场景的三维模型。
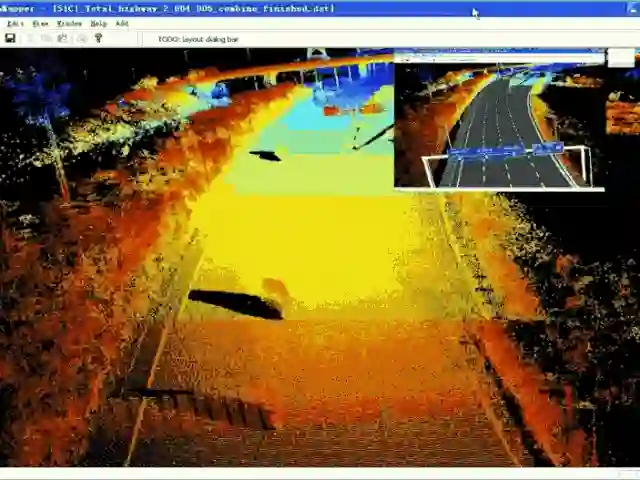
我们通过车载三维传感技术得到了大量点云数据,并利用这些数据进行几何建模,得到了非常精细的三维模型。我们对城市场景里各种类别的复杂物体进行建模,例如对树木等目标进行三维识别,识别出不同类型的树,再针对不同树木的几何特征,对树木进行高精细化的三维建模。

中央电视台曾经对我们做过一期专门报道——《把城市搬到电脑里》。当时我们对深圳一个片区进行了完整的三维建模。这之后我们接到了很多电话,问我们:用你们的车开过一遍是不是就能获得我们城市的三维模型?实际上我们做不到,原因不是因为数据处理的问题,而在于前端的数据获取。
我们的城市绿化做得太好了,车开过去只能扫描到树,扫描不到建筑。如果要真正解决这个问题,就要把解决方案移到前端,想办法能够完整地获取数据。
因此,我们开始提出利用机器人获取数据,来进一步解决这个问题。机器人在现场采集数据的同时进行数据分析,看看数据是不是有缺失,如果有缺失就要走到相应地点去获取所需信息,从而形成一个数据获取与处理的闭环。
让机器人不仅看得见,还要看得懂

首先从单个物体的实验开始,机器人手持Kinect(一种利用结构光获取三维模型信息的主动式传感器)扫描一个物体,例如一个3D打印的玩具,能获取目标物体全方位的三维数据。机器人自己规划扫描路径,直到最后获得一个完整的三维模型。

接着实验的是场景认知问题。不仅要获得场景的完整三维数据,而且还要认识每个物体到底是什么,要去理解场景里的每个物体,获取物体的语义信息。同样的道理,认知的过程必须形成一个闭环,机器人的实时决策能不能根据现有的三维数据对这个物体进行识别。如果不可以,就要走到新的角度去获取数据。

进一步,我们的算法就可以拓展到一个更大的室内场景中。这种情况下,只有一个机器人是不够的,我们可以利用多个机器人。这些机器人要实现协作,需要一个实时的协同工作算法。在室内环境下,我们已经有了非常好的机器人协同方案。


机器人不仅可以在三维空间导航行走,还应该成为真实世界的一员。实现这一点就要让机器人和现实场景打交道,比如让机器人拿起一个杯子,打开一扇门,甚至和人握手等。这种直接的三维交互非常重要。这需要对机器人空间定位和路径规划进行更多的研究,这方面我们近期做了一些工作。
让机器人具备决策和执行力,替人类完成更多工作
我们沿着这个技术路线探索,思路也变得愈发清晰。通过三维视觉与人工智能技术的结合,我们让机器人更加智能化与功能化,让机器人做更多人在现实生活中能够做的事。机器人具备现场自主决策和执行的能力,比如在工业流水线上可以帮助组装配件,物流场景中搬箱子等。这样的应用,涉及到非常精细化的技术,比如准确高效的运动规划,还有各种各样的控制,智能的执行等。我们在这方面也有了些探索性的工作。

随着三维传感器的普及,三维数据越来越多,如何实现对三维场景的精细化理解变得非常重要。理解场景很重要也很有效的一个方法就是深度学习。最早所有的深度学习都是针对二维影像。卷积神经网络面向的是二维影像,而对于三维场景,输入数据是三维的点云。
因为没有卷积神经网络能够天然地处理非结构化的三维点云,我们针对这个问题设计了PointCNN卷积神经网络,它的性能是相当好的,我们也很高兴看到有很多公司在使用我们的网络。

面向物流领域的应用,我们还尝试了一个机器人搬箱子的测试。在去年京东“双11”期间进行了10天的压力测试,机器人在现场代替一组人(两人一组)去识别箱子、搬箱子,并把大大小小不同的箱子搬到传送带上。这是我们的技术第一次从学校的实验室走进现实场景中。但是我们也感受到,越走近现实场景,问题就会越复杂。在座有很多企业界的人,欢迎各位能过来跟我们交流合作。
三维视觉智能的研究与应用如此重要,但国内还没有一个基于三维视觉的社区。去年底,由本人召集在中国图像图形学会旗下成立了三维视觉专业委员会,目的是把学术界和企业界的相关人士联合在一起。欢迎更多相关企业加入进来,一起推动三维视觉技术的发展。
谢谢各位!

先进制造业+工业互联网
产业智能官 AI-CPS
加入知识星球“产业智能研究院”:先进制造业OT(自动化+机器人+工艺+精益)和工业互联网IT(云计算+大数据+物联网+区块链+人工智能)产业智能化技术深度融合,在场景中构建“状态感知-实时分析-自主决策-精准执行-学习提升”的产业智能化平台;实现产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。

版权声明:产业智能官(ID:AI-CPS)推荐的文章,除非确实无法确认,我们都会注明作者和来源,涉权烦请联系协商解决,联系、投稿邮箱:erp_vip@hotmail.com。





