CVPR 2022大会主席、港科大教授权龙:计算机视觉的现状与未来

来源:AI科技评论
本文约5200字,建议10+分钟。
权龙教授发表了题为《三维视觉重新定义人工智能安防》的演讲。
近日,由雷锋网主办的第二届中国人工智能安防峰会在杭州召开。
峰会现场,香港科技大学教授,CVPR 2022、ICCV 2011大会主席,Altizure创始人权龙教授发表了题为《三维视觉重新定义人工智能安防》的演讲。
权教授表示,人工智能的核心是视觉,视觉定义了智能安防,但现在的视觉仍局限在二维识别层面,未来三维视觉重建将会成为最重要的任务, 它也将重新定义智能安防。
权教授也谈到,现在计算机视觉本质上是大数据统计意义上的分类与识别。
“我们的终极目标是对图像的理解,也就是认知,但当前的计算机视觉只处于感知阶段,我们并不知如何理解,计算机视觉一直是要探索最基础的视觉特征,这一轮视觉卷积神经网络CNN本质上重新定义了计算机视觉的特征。但人类是生活在三维环境中的双目动物,这使得人类生物视觉的识别不只是识别,同时也包括三维感知与环境交互。”
“因此我们要和三维打交道,二维识别所能做的事,在当前众多复杂场景中,是远远不够的。但三维重建不是最终目的,而且是要把三维重建和识别融为一体。”
以下为权龙教授的现场演讲内容,我们作了不改变原意的编辑及整理:

感谢邀请,今天我主要分享下现阶段计算机视觉的现状与未来发展方向,以及三维视觉在人工智能安防中的应用。
我们知道,现在AI安防的核心,本质上是计算机视觉,而计算机视觉分为两大部分,分别是识别和重建。
“识别”是现在非常热门的方向,相比而言,大家对“重建”的理解却并没有那么透彻。我们需要知道这一点,计算机视觉不止局限于识别,三维重建在其中扮演的角色甚至更为重要。
这是三维重建和安防融合的实际案例:




这些景物都是由三维构建,我们把实时视频投影到三维,用户在界面上也可以“前、后、左、右”拖动操作。
接下来我要讲的是当前计算机视觉存在的问题,以及为何三维视觉将重新定义计算机视觉,并且重新定义人工智能安防。
人工智能的本质上是让计算机去听、看、读,在所有的信息里面,视觉信息占了所有感官的80%,所以视觉基本上是现代人工智能的核心。
对我们来说,其实并没有泛泛的人工智能,人工智能需要具体根据技术维度和场景维度,区分开来看,人工智能的发展、革命和应用落地,一定是取决于以及受限于计算机视觉发展、革命和应用。
而人工智能安防也同样是伴随着计算机视觉的发展而崛起。
2012年是非常重要的一年,当时在ImageNet比赛中,有团队用卷积神经网络CNN把图像识别准确率从75%提高到了85%,这件“非常小”的事情带动了这一轮深度学习之下的人工智能,所以我们也可把2012年称作是这轮以深度学习为代表的人工智能元年。
这件事再回到1998年,那个年代Yann Lecun已经发表了卷积神经网络LeNet,这个网络呢,首先它输入的图像比较小,只黑白单通道32*32,只能识别出一些字符和字母;因为也没有GPU,所以当时整个网络也只有60万的参数。
到了2012年卷积神经网络复活出现了AlexNet。AlexNet和1998年LeNet的卷积神经网络相比,它的内部结构基本不变,但可输入的图像尺寸不一样:1998年的模型,输入尺寸为32*32,且只有一个通道。新的模型输入尺寸已经扩大到了224*224,而且有三个通道。最关键的是里面有了GPU,当时的训练用到了两块GPU,参数达到将近6000万。
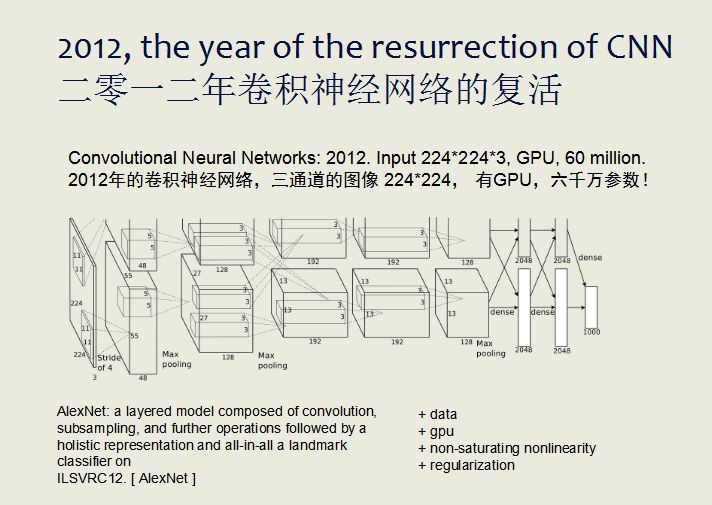
这么多年来计算机视觉的卷积神经网络,算法和结构,基本的结构变化是很小的。
但1998年到2012年这十五年来发生了两件特别重要的事:一是英伟达研发了GPU;第二就是李飞飞创建了ImageNet,她把几百万张照片发到网络上并发动群众做了标注。也正是因为算力和数据,才创造了AlexNet的成就。
到了2015年,机器视觉的识别率基本超越了人类。其实人类在识别方面并没有那么强,我们的记忆非常容易犯错误。根据统计,人类在分类上的错误率达到了5%。而机器,从2015年之后你们看各种ImageNet在公开域数据集上的错误率已经远远低于5%。
但为什么ImageNet在两年前停止了比赛,因为现在比拼的基本上都是靠算力和数据。
2015年随着卷积神经网络下的人工智能技术的成熟,AI也到达了一定的巅峰,计算机视觉或者说更宽泛的安防市场也被重新定义。
也在这一时期,旷视、商汤这几家做视觉的公司进入了安防市场。
从2012年到2019年的7年间,所有的数据又都翻了一千倍,计算速度比以前快一千倍,模型也比以前大一千倍。2012年训练AlexNet模型需要使用两块GPU,花费两个星期;今天做同样的事情只需要一块DGX-2,十几分钟就能完成。
从整个模型的参数来看,2012年的AlexNet已非常可观,6000万的参数非常庞大,这个数字我们当时都不敢想象。到今天这个网络又要放大千倍,达到十亿级的参数量。但是从算法、架构来说,现在基本上都是标准的卷积神经网络,其实并没有太大的进步。
我们也可以想一下,计算机视觉里面的识别到底能够达到什么程度?其实它并没有那么强,它只是在一个大数据统计意义上的识别而已。
大家都听说过无监督学习,但无监督学习的结果和应用的场景并不是太多。现在可用的、做的好的也就是可监督的,也就是CNN。
我简要概括下,现在的计算机视觉就是基于卷积神经网络而来,整个CNN的架构非常简单,能做的事其实也没那么多,它提取了高维的特征,然后要结合其它方法解决视觉问题。
如果你有足够的数据并且能够明确定义你想要的东西,CNN的效果很好,但是它有没有智能?其实没有。
你说它蠢,它跟以前一样蠢。它能识别出猫和狗,但我们要知道猫和狗的分类都是我们人类自己定义的,我们可以把猫和狗分开,也可以把复杂的狗类动物进行聚合和分类,这些东西本质上来说并不是客观的,而是主观的。

我们做计算机视觉研究的理想,是让机器进行理解图像。如何让它进行理解?这非常的困难,直到现在也没有人知道它怎么去进行理解。现在它能做的,只能做到认知。我们研究计算机视觉的目的是得到视觉特征,有了视觉特征后才能开展一系列工作。
为什么视觉特征如此重要?在语音识别领域,语音的特征已经定义得非常清晰——音素。但如果我们拿来一个图像,问它最重要的视觉特征是什么,答案并不明确。大家知道图像包含像素,但像素并不是真正的特征。像素只是一个数字化的载体,将图像进行了数字化的表述。计算机视觉的终极目标就是寻找行之有效的视觉特征。
在这样一个拥有视觉特征前提之下,计算机视觉也只有两个现实目的,一个是识别,另一个是三维重建。
它们的英文单词都以“re”做前缀,说明这是一个反向的问题。
计算机视觉不是一个很好定义(ill-posed)的问题,没有一个完美的答案或方法。
这一轮的卷积神经网络(CNN)最本质的一件事是重新定义了计算机视觉的特征。在此之前,所有的特征都是人工设计的。今天CNN学来的东西,它学到特征的维度动辄几百万,在以前没有这类网络的情况下是根本做不到的。
纵使CNN的特征提取能力极其强,但是我们不要忘记建立在CNN基础上的计算机视觉是单目识别,而人类是双目。我们的现实世界是在一个三维空间,我们要和三维打交道。拿着二维图像去做识别,这远远不够。
在双目视觉下,要包含深度、视差和重建三个概念,它们基本等价,使用哪个词汇取决你处在哪个群体。
传统意义上,三维重建是在识别之前,它是一个最本质的问题,三维视觉里面也要用到识别,但是它的识别是对同样物体在不同视角下的识别,所以说它的识别是更好定义(well-posed) 的一个识别,也叫匹配。
双目视觉对整个生物世界的等级划分是非常严格的。大家知道马的眼睛往外看,对角的部分才有可能得到一部分三维信息,但它的三维视角非常小,不像人类。鱼的眼睛也是往两边看的,它的主要视线范围是单目的,它能看到的双目视区也是非常狭窄的一部分。
人类有两只眼睛,通过两只眼睛才能得到有深度的三维信息。当然,通过一只移动的眼睛,也可以获得有深度的信息。
获取深度信息的挑战很大,它本质上是一个三角测量问题。第一步需要将两幅图像或两只眼睛感知到的东西进行匹配,也就是识别。这里的“识别”和前面有所不同,前面提到的是有标注情况下的识别,这里的“识别”是两幅图像之间的识别,没有数据库。它不仅要识别物体,还要识别每一个像素,所以对计算量要求非常高。

在生物世界里,双目视觉非常重要,哺乳动物都有双目视觉,而且越凶猛的食肉的动物双目重叠的区域越大,用双目获得的深度信息去主动捕捉猎物。吃草的或被吃的动物视觉单目视觉,视野很宽,只有识别而无深度,目的是被进攻时跑得快!
在这一轮的CNN之前,计算机视觉里面研究最多的是三维重建这样的问题,在CNN之前有非常好的人工设计的视觉特征,这些东西本质上最早都是为三维重建而设计,例如SIFT特征。而在这之后的“识别”,只是把它放在一个没有结构的图像数据库里去搜索而已。 由此可见,现代三维视觉是由三维重建所定义。CNN诞生之前,它曾是视觉发展的主要动力源于几何,因为它的定义相对清晰。
我们再来看一下当今的三维重建技术的现状和挑战。
三维视觉既有理论又有算法,一部分是统计,另外一部分则是确定性的,非统计,也就是传统的应用数学。
计算机视觉中的三维重建包含三大问题:
定位置。假如我给出一张照片,计算机视觉要知道这张照片是在什么位置拍的。
多目。通过多目的视差获取三维信息,识别每一个像素并进行匹配,进行三维重建。
语义识别。完成几何三维重建后,要对这个三维信息进行语义识别,这是重建的最终目的。
这里我再强调下,我们要把三维场景重新捕捉,但三维重建不是最终的目的,你要把识别加进去,所以说最终的应用肯定要把三维重建和识别融为一体。
现在三维重建的主要挑战是,算力不够,而且采集也比较困难。我举个例子,我们安防场景识别一个摄像头比较容易,但如果实时重建N个摄像头的实景,这对算力要求非常高。这些限制也使得当前的单目应用比较多,但我认为,未来双目一定会成趋势。
在深度学习的影响下,三维重建已经取得了比较大的成就。CNN在2012年之后的几年内,对三维重建的影响不是很大。但是从2017年开始,CNN就对三维重建产生了重要的影响。在三维重建领域有一个数据集叫KITTI,从2017年,我们开始用三维卷积神经网络。
以前是把它作为一个跟识别有关系的二维CNN,更现代的双目算法都是基于完整的三维卷积神经网络。现阶段三维卷积神经网络的表现也非常强,给任何两幅图像,错误率只有百分之2到3。
现在计算机视觉覆盖的应用场景,被计算机视觉重新定义,但这些应用也受制于计算机视觉的技术瓶颈。
虽然计算机视觉对安防行业的推动作用很大,但基本也不外乎识别人脸、车、物体等应用,如果计算机视觉得到进一步发展,安防行业也将再度被重新定义。
而我认为,三维视觉将对安防产生非常深远的影响。
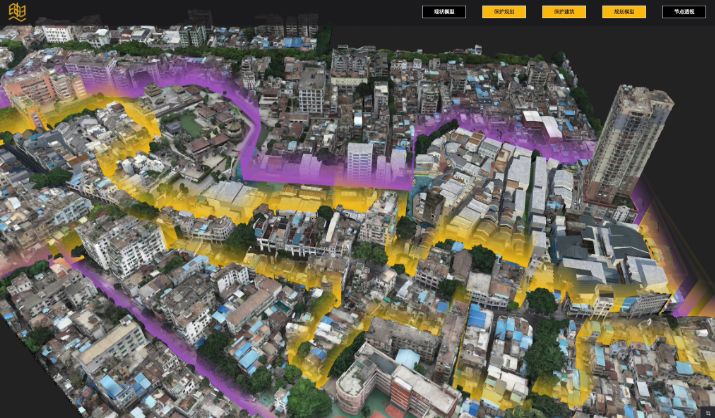
三维重建在安防领域的应用,第一个是大规模城市级别的三维重建。

每个大型城市动辄都百万级的摄像头,把摄像头融合在这样的一个实景三维场景里,才可达到城市级管控的效果,这是AI安防最理想化的形态。
现在政府都在通过一张实景图对城市进行治理,这张图以前是二维的,但今后一定是实景的,是三维的。
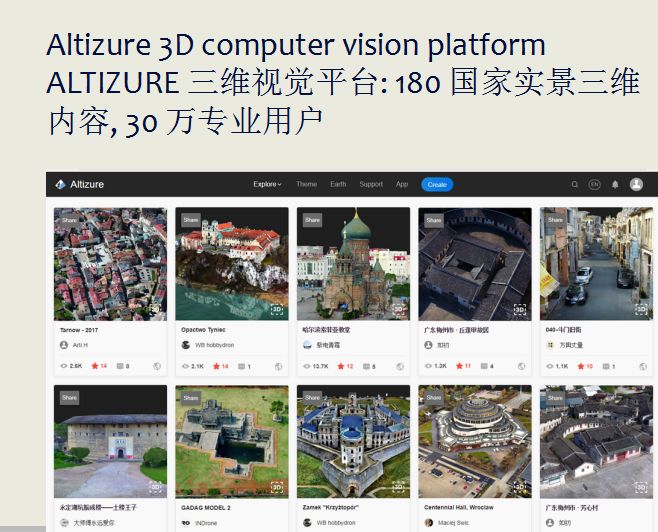
我们港科大的三维视觉初创公司Altizure就是一家做城市级别的实景三维重建和平台企业,大规模重建有两方面非常有挑战性:
第一是因为它的数据量非常大,我们现在建模动辄百万级的高清图像,要有强大的分布式以及并行算法,几个星期才能做完。
第二就是可视化,一张实景图的展示也特别有挑战性,因为一张实景图数据量非常大,即便是在任何一个端口的浏览实景三维都是非常有挑战性的。
现时只有Altizure可以应对这个挑战。
我们做的一个典型案例就是为深圳坪山区布局了时空信息云平台,我们对坪山的大片住宅区域进行了三维重建,后台用户可在三维实景图像上进行“上、下放大“以及”前、后、左、右”拖拽移动,来查看区域实景。
后台用户也可用鼠标在三维实景图像中选取部分区域,然后这一区域的各个重点视频监控画面便在大屏幕中一一实时展示。坪山第一期项目的实时监控视频显示,与常规的视频监控后台呈现效果相似,总体更为传统一些。
而在二期和三期,我们开始可以把所有的视频在三维平台上进行展示。
现在深圳已经有很多区在布局这类实景三维立体时空信息平台。
有了这样的平台,不仅是视频,其实还有一些别的数据也是可以加进去应用。
这个总控系统,集成了景区的监控摄像,闸机,商店,wifi等公共设施,实时可视化人流、电瓶车位置。三维实景给景区总控和下一步游客的导览带来了便利。
下图是我们在广州做第一个案例,对历史建筑进行保护以及城市规划。
Altizure实景三维视觉平台现在已经有180个国家的实景三维内容和30万专业用户。
我们的香港科技大学计算机视觉实验室和初创公司Altizure 在全球引领视觉三维重建的研究与应用。我们的目的并不是为刷榜而刷榜,但在一些关键的三维榜单,我们从去年四月以来一直稳居榜首!

最后总结一下,计算机视觉中的“识别”定义了智能安防,但现在的“视觉”和“识别”仍局限在二维,三维重建是未来计算机视觉中最为重要的任务,因此三维重建也将重新定义人工智能以及智能安防。
现在的视觉研究,同质化现象非常明显。
我们在八十年代就开始做人工智能了,今天的现状,有点像是历史重演,计算机视觉的本质跟以往并没什么差别,只是大家用的硬件工具不一样。
计算机视觉虽然正处于黄金时期 ,但它的发展还是非常有局限性的,我认为,所谓的通用人工智能和通用计算机视觉还遥遥无期。
谢谢大家!
编辑:黄继彦
校对:林亦霖







