再评Airbnb的经典Embedding论文
作者 | 石塔西
链接 | https://zhuanlan.zhihu.com/p/162163054
编辑 | 机器学习与推荐算法
前言

这篇论文我去年就读过了,把自己的心得发表在知乎上,还收获了不少赞。其实说来惭愧,那时的我,尽管有着好几年的排序算法经验,空有召回模型的理论,但是没有亲自上手实现过召回模型。用我根深蒂固的排序思维,来理解召回算法,其实范下不少的低级错误。比如,我在回答中说认为这种非监督的学习方式是"非主流",就被同行在评论中diss了,着实让人汗颜。
缺点一:强套word2vec算法概念
word2vec是NLP算法,它的某些概念,比如上下文、窗口,其实并不适用于推荐系统。论文强把召回问题,抽象成一个center word找context word的问题,好套用word2vec算法,反而模糊了问题的本质,加上论文中的那几幅示意图的误导,让人难以理解。
其实在一年前我的上篇评论中,就已经感受到这种理解上的困难,比如:
为什么final booked listing要成为点击序列中的每个listing的邻居?
word2vec中的center word与context word隐含了一种顺序上的正确性。比如“我今天回家吃饭”就是一句人话,而倒过来"吃饭回家今天我"就不是人说的。而一个点击序列中两次clicked listing的顺序那么重要吗?交互了点击顺序,就是一条异常的点击序列吗?
同理,word2vec中的窗口在这里适用吗?难道一条点击序列中的两个listing相隔较远,超过了窗口的限制,二者就没关系了吗?就不相似了吗?
学习user-type/list-type embedding时,为什么要将user-type/listing-type画在一序列里? 代表了什么?代表了user与listing是相似的?
造成这种困惑的原因是Airbnb在论文中把自己的算法描述成“衍生自word2vec”,从而不得不把所有话术都往往“父亲”word2vec那里套,把简单问题复杂化了。
其实Airbnb算法,与word2vec是兄弟关系,但是怎么命名它们共同的父亲,我尚没有很好的思路,只好以“xx2vec”算法代称。可以从如下三个方面来理解xx2vec算法的共性:
-
相关性 :看word2vec的公式,最基础的模块就是两个向量的点积。众所周知,向量点积就代表两个向量是相似的。而这里,我把这种关系定义成更广义的“相关性”。毕竟,你不能说word2vec中center word与context word是相似的,只能说它们是“相关”的。
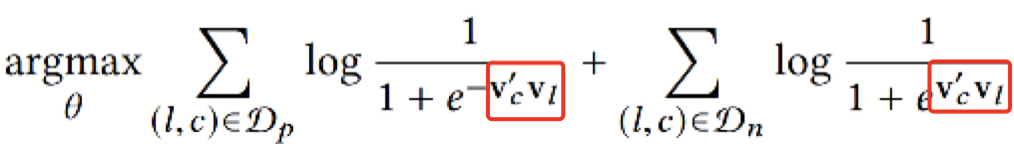
Pairwise思想
排序中常用的CTR预估思想,代表了一种Pointwise思想,每个样本由<user,doc,label>组成,正负例分属不同的样本
而经典的召回算法,比如youtube, dssm, word2vec的公式,都采用了Pairwise的思想。以u2i召回为例,一个样本由<$u,d_+,d_{-1},d_{-2},...,d_{-N}$>组成,loss要求user与$d_+$的匹配程度尽可能高,而与$d_-$的匹配度尽可能低
没错,word2vec也可以看成一种召回算法,由center word在整个词典中召回context word
Youtube/Word2Vec论文里面用的都是softmax,而最后都(可以)转化为pairwise模式,即一个正例配若干负例
至于为什么召回用的是Pairwise思想,而不是排序常用的Pointwise思想,我以为主要是召回面对的候选集巨大(几十、上百万),目标不要求十分精确(还有排序把关),缺少显式负反馈(召回的,用户不点击,未必代表用户不喜欢,有可能是因为没有曝光)
选择负样本: Pairwise中,一个正样本搭配的负样本从哪里来?
一来,我不可能拿u与库中所有物料都比较一遍;二来,如果真的都比较一遍,就发现u与$d_+$未必是最匹配的
因此,最常见的做法就是拿随机采样出来的做负样本。如果库足够大,随机抽样出来的,很大程度是与user"八杆子打不着的",我们有充足信心要求user与这些负样本的匹配度足够低。
但是同样因为负样本是随机采样出来的,信号没那么强,使模型可能只学习到一些粗粒度的差异,False Positive可能性较大。
重新理解word2vec
-
相关性 -
word2vec中的"相关“描述了词语的共现性,即center word与context word出现的可能性,要比center word与随机词共现的可能性高 -
Pairwise思想 -
因为要衡量共现,所以才引入“窗口”的概念。只有在一个窗口中共现的两个词,才能构成一个正样本对儿。 -
所以“窗口”是word2vec所独有的,并非所有类似算法不可缺少的标配。 -
选择负样本 -
缺乏人工显式负反馈(没有”一个词绝对不能出现在另一个词周围“的知识) -
只能在词库里随机抽词。如果库大,抽样数目较少,大概率抽到的都是不可能出现在center word周围的词。
重新理解Airbnb Listing Embedding算法
-
相关性 -
与word2vec不同,这里的”相关“就是”相似性“,而不是共现性。同属一个点击序列中的listing应该是相似的 -
Pairwise -
与word2vec不同,其实这里没有窗口的概念,一个序列里所有的listing可以cross join,它们彼此都是相似的 -
但是如果全部做cross join,样本量太大,只好还考虑窗口。但是保留信号最强的那个listing,即让final booked listing与点击序列中的所有listing都相似 -
如果还按照word2vec窗口的方式来理解,增加final booked listing作为global context,好似突然冒出来的"神来之笔" -
而如果参考了本来就没有什么窗口的限制,增加final booked listing,不过是水到渠成,而且还是基于工程代价考虑的保守、替代方案。 -
负样本 -
随机抽样,大概率是与listing不相关的,是合格的负样本 -
但是,这种信号太弱,可能让模型学习到粗粒度的特征差异,比如“是否同城”,导致大量的false positive -
因此,要增加一批“同城”做负样本,缓解正样本在"地域"上的bias
重新理解Airbnb User-type/Listing-type Embedding算法
-
相关性 -
这里的相关性,即user-type embedding与listing-type embedding的点积,表达是二者之间的匹配性。不是word2vec中的共现性,也不是item2vec中的相似性 -
“预订成功”代表了一种正的匹配性 -
“被拒绝”代表了一种负的匹配性。从这个角度来看,加入“被拒绝”做负样本,显而易见,水到渠成 -
Pairwise -
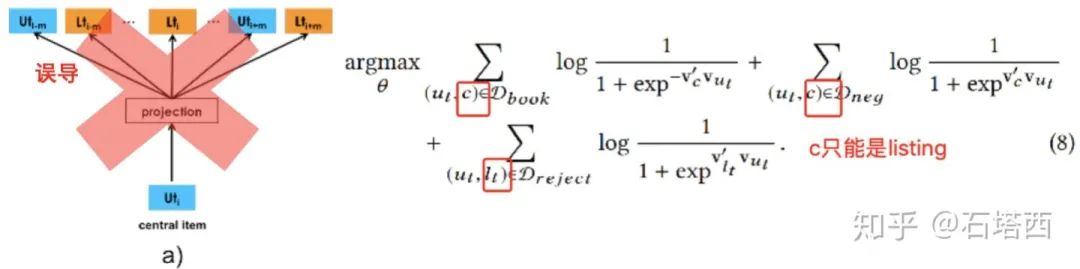
与item2vec类似,这里也没有序列、窗口的限制,论文中将user-type, listing-type画在一个序列里,只能误导读者,让人徒生迷惑 -
从公式(8)(9)中可以看到,$D_{book}, D_{neg}, D_{reject}$都是<user, listing>对,那么当中心是user时,其context只能是listing,而不能是其他user。这就更突现出图5给读者造成的误导
负样本
-
如上所述,“被拒绝”代表了一种明确的负匹配性,加入公式(8),理所应当 -
这种人工反馈,比随机采样得到的负样本信号更强,能够让模型学习到细粒度的差异 -
这种方式对我们有什么借鉴意义?我是做内容推荐的,内容推荐中也不乏显式负反馈,比如“曝光未点击” -
将“曝光未点击”与“随机抽样”,合起来做负样本,我做过尝试,效果上也没有明显提升 -
我猜测的原因,一是“曝光未点击”本身的噪声很多,用户未点击,并不能代表用户不喜欢。可能时机不对,或者同屏的有用户更喜欢的而已。 -
二来,从召回的角度来看,“曝光未点击”毕竟经过了上一版召回+排序的双重筛选,可能应该做权重较小的“正样本”,而不是负样本。
缺点二:人工聚类是败笔
-
依赖于产品经理对业务的理解,主观性太强 -
维护困难。比如价格变化了,那么原来价格划分方式,是否还适用? -
表达能力比较弱。比如房间1/2/.../5间都是独立的类别,但是,是否1间/2间的特征更相近,表示是“小房子”;而4/5间的特征更相似,表示是“大房子”。
-
先把画像特征离散成id型特征 -
每个离散化的画像,embedding成一个向量 -
画像的embedding与用户id或物料id的embedding,pooling成一个向量,代表这个用户或物料的向量 -
拿这个整合了id和画像的用户或物料的向量,参与Skip-Gram或CBOW的算法迭代
重申一下,模型学习到的,未必就一定比人工聚类的效果更好。但是,模型自动学习到的,更顺应潮流趋势。就好比,早期的火枪故障率高,精度差,阴天下雨还打不响。有很多战例,弓箭手打败了火枪兵。但是现在,步枪已经是军队的基本装备,而弓箭大多数已经变成了体育器械。为什么?其中一个原因,就是培养一个弓箭手既费时又费钱,而火枪大幅降低了使用者的门槛。这里,模型自动学习和人工规则,也是同样的道理。
亮点:离线评估
-
为了得到稳定结果,AB实验往往要进行一段时间,时间成本太高 -
AB实验,受外界因素的影响很大。大盘、特殊时间或事件、其他模块,都可能对AB实验造成影响,短时间内观察到的收益起伏不定,让我们难以下结论。
离线评估召回算法的难点
-
召回缺乏显式负反馈。如果召回的,用户没有点击,可能并不代表用户不喜欢,而可能是压根没有曝光给用户。而没有曝光的原因有很多,比如排序偏向老召回,没有将你的召回结果排上去;或者你本路召回,在多路召回融合时的配比太低。 -
召回,受后面的粗排、精排的影响较大。配合不好,可能排序会大大减弱你这一路召回的影响。 -
召回之间存在重叠、竞争的关系。没准你单路召回的指标非常好看,但是对大盘没什么影响,原因这一路召回的东西和其他线上的召回返回的结果,重合度太高了。
小结
-
从算法技巧上来看,这篇论文描述的算法,不如阿里的EGES -
在“在word2vec中引入画像”方面,EGES的“embedding+pooling”的方法,要比这里“人工规则聚类”的方法,更加是大势所趋,更加有模仿的价值。 -
EGES根据图上的随机游走产生序列,产生的序列突破了单个用户序列的限制,能够描述user/doc之间更深层次的关系。
-
而从结合业务实际,选择样本上来看,Airbnb的这篇论文仍然是我们学习的榜样 -
增加final booked embedding突破了word2vec对窗口的限制 -
增加“同城负例”与“显式拒绝”,增加了更强的负信号,能够让模型学习到正负例之间细粒度的差异,减少False Positive -
如果不强套word2vec,不在“序列+窗口+上下文”的语境下阐述算法,就更清晰了
推荐阅读
模型的Robustness和Generalization什么关系?