商汤入局围剿Deepfake:推出迄今最大人脸伪造检测数据集 DeeperForensics-1.0
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

鱼羊 发自 凹非寺
本文转载自:量子位(QbitAI)
反deepfake阵营今日又有新成果,商汤入局,献出迄今最大检测数据集:
包含60000个视频,共计1760万帧,是现有同类数据集的10倍。
deepfake进化了一版又一版,效果越来越逼真,门槛却越来越低。

△施瓦辛格、比尔·哈德无痕换脸
不仅是明星们,连普通人都不禁瑟瑟发抖。
眼见亦不为实,难道就没有什么能制住AI换脸了?
其实,魔高一尺时,道也未曾停止修炼。并且,还要以彼之道,还施彼身。
现在,商汤就携手新加坡南洋理工的研究人员们,推出了迄今为止最大的deepfake检测数据集,DeeperForensics-1.0。
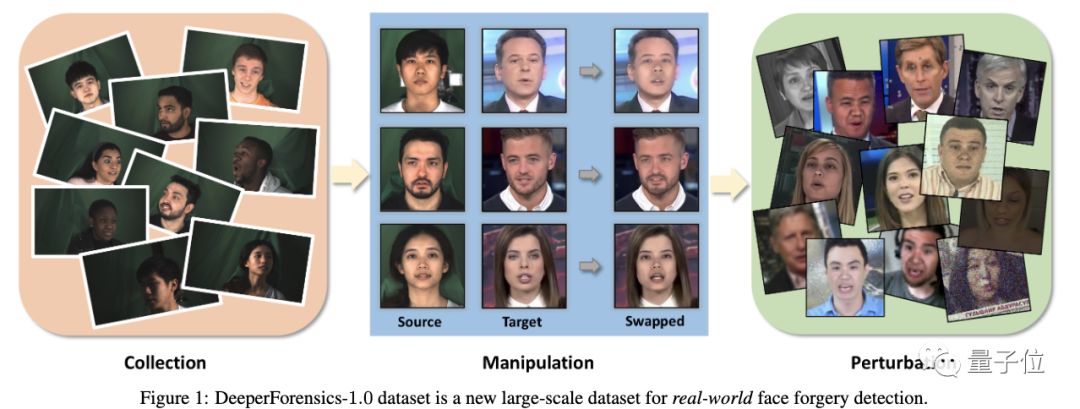
并且,更接近现实场景,更具多样性、挑战性。
数据、代码和预训练模型,正在开源的路上。
DeeperForensics-1.0
在DeeperForensics-1.0的60000个视频中,有50000个是研究团队收集的原始视频,剩下的10000则是他们造出来的“伪视频”。
数据集的打造,一共分为三步。
第一步,是数据采集。
将真实视频中原本的人脸称作目标人脸,被替换上去的人脸称作源人脸,研究人员发现,在构建高质量数据集的过程中,源人脸比目标人脸起到了更为关键的作用。
源人脸的表情、姿势和拍摄时的照明条件越丰富,人脸交换的可靠性就越高。
于是,研究人员雇佣了100位演员来参与人脸视频的录制。他们分别来自26个不同的国家,其中有53名男性和47名女性,年龄范围在20-45岁之间,四种肤色(白,黑,黄,棕)比例为1:1:1:1。

这些视频的录制分辨率为1920×1080。拍摄过程中,演员们被要求展示各种不同的表情:中立,愤怒,快乐,悲伤,惊讶,鄙视,厌恶,恐惧等。
脸部面对镜头的角度在-90°到90°之间变化。还设置了九种不同的照明效果。

第二步,以假治假。
知己知彼,百战不殆。
为了生成更真的假视频,研究人员提出了一种新的人脸交换框架:DeepFake变分自动编码器(DeepFake Variational Auto-Encoder,DF-VAE)。
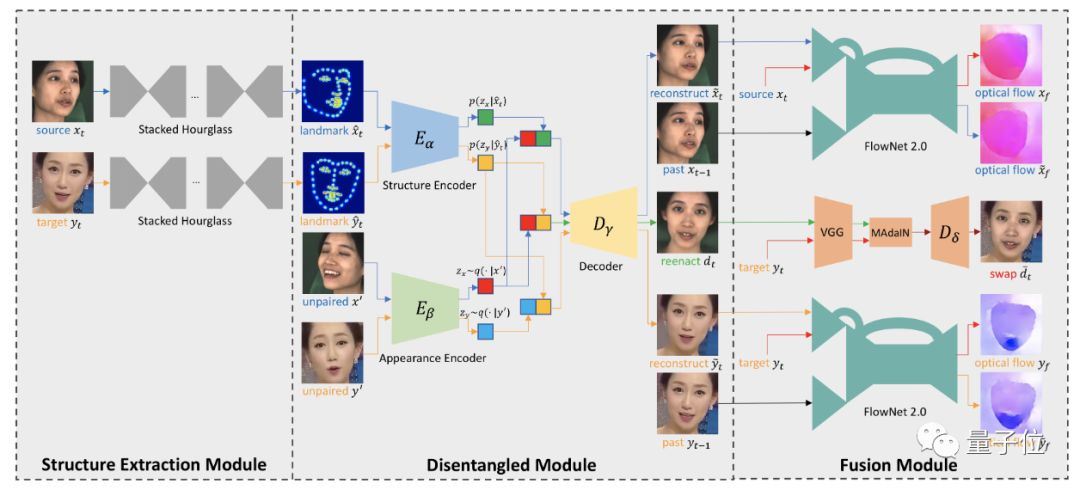
DF-VAE由三个模块组成:结构提取模块,解耦模块和融合模块。
在训练中,通过提取标志物、构造未配对的样本作为条件,重构源人脸和目标人脸。
重构后,最小化光流差异来改善时间连续性。
而MAdalN模块,负责会将重现的面孔与原始背景融合到一起。

第三步,是进一步提升难度,加入扰动模拟真实场景中的视频。
具体而言,就是在视频中加入色彩饱和度变化、局部图像块失真、色彩对比变化、高斯模糊、色彩分量中的高斯白噪声、JPEG压缩和视频压缩率变化这七种失真。

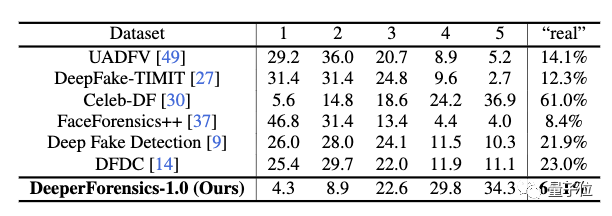
为了评估DeeperForensics-1.0的质量,研究人员邀请了100位计算机视觉专家对其进行评分。
根据反馈,专家们认为,与FaceForensics++、Celeb-DF等流行的Deepfake检测数据集相比,DeeperForensics-1.0更加真实。
阻击Deepfake
假视频越演越真,引发了广泛的担忧。
以AI治AI的行动,也早已展开。
此前,Facebook就壕掷千万,举办换脸视频检测挑战赛。
UC伯克利EECS教授Hany Farid评价说:
为了从信息时代走向知识时代,我们必须更好的辨明真伪,奖真惩假,教育下一代成为更好的数字公民。这需要全面的投资,需要工业界、学界、非政府组织一同努力研究,发展和实施能快速精准辨别真伪的技术。
美国初创公司Truepic,则以打击AI造假照片、视频为核心业务,在2019年7月筹集了800万美元(约合5680万人民币)资金。
国内,2019年11月底印发的《网络音视频信息服务管理规定》,则可视作针对AI造假视频的一次针对性管控。

这项规定已于1月1日正式施行。
传送门
项目地址:
https://liming-jiang.com/projects/DrF1/DrF1.html
论文地址:
https://arxiv.org/abs/2001.03024
VB报道:
https://venturebeat.com/2020/01/15/sensetime-face-forgery-research-deepfakes/
作者系网易新闻·网易号“各有态度”签约作者
重磅!CVer-学术交流群已成立
扫码可添加CVer助手,可申请加入CVer大群和细分方向群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索等群。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加群

▲长按关注我们
麻烦给我一个在看!