Storm精华问答 | storm与Hadoop有什么区别?
戳蓝字“CSDN云计算”关注我们哦!

归于Apache社区,Storm被业界称为实时版Hadoop。随着越来越多的场景对Hadoop的MapReduce高延迟无法容忍。而目前已是分布式技术领域最新爆发点,Storm更是流计算技术中的佼佼者和主流。今天我们就一起来看看Storm的精华问答!

Q:task与executor有什么关系?
A:在我们安装配置Storm的时候,不知大家是否主要到了一个问题,就是我们在配置的时候会加几个worker的端口(supervisor.slots.ports:),比如众多文档中提到的6700/6701等等类似的东西。没错,这就是我们定义了该supervisor最多的worker数,worker中执行一个bolt或者spout线程,我们就称之为task,而executor是物理上的线程概念,我们可以将其称为执行线程;而task更多是逻辑概念上的,有时候bolt与spout的task会共用一个executor,特别是在系统负荷比较高的时候。
Q:storm与Hadoop区别?
A:storm用于实时计算,hadoop用于离线计算
storm处理的数据保存在内存中,源源不断;hadoop处理的数据保存在文件系统中,一批一批
storm的数据通过网络传输进来的;hadoop的数据保存在磁盘中
storm与hadoop的编程模型相似:
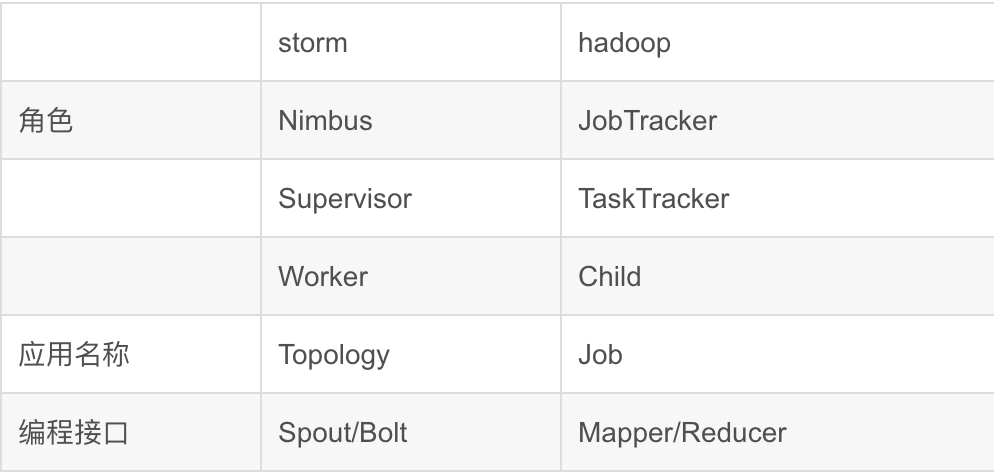
Q:Storm的Spout组件中的ack及fail是一个什么样的机制呢?
A:Storm保证每一个数据都得到有效处理,这是如何保证的呢?正是ack及fail机制确保数据都得到处理的保证,但是storm只是提供给我们一个接口,而具体的方法得由我们自己来实现。例如在spout下一个拓扑节点的bolt上,我们定义某种情况下为数据处理失败,则调用fail,则我们可以在fail方法中进行数据重发,这样就保证了数据都得到了处理。其实,通过读storm的源码,里面有讲到,有些类(BaseBasicBolt?)是会自动调用ack和fail的,不需要我们程序员去ack和fail,但是其他Bolt就没有这种功能了。
Q:IRichBolt与IBasicBolt接口有什么区别?
A:首先从类的组成上进行分析可以看到,IBasicBolt接口只有execute方法和declareOutputFields方法,而IRichBolt接口上除了以上几个方法还有prepare方法和cleanup及map方法。而且其中execute方法是有些不一样的,其参数列表不同。
总体来说Rich方法比较完善,我们可以使用prepare方法进行该Bolt类的初始化工作,例如我们链接数据库时,需要进行一次数据库连接操作,我们就可以把该操作放入prepare中,只需要执行一次就可以了。而cleanup方法能在该类调用结束时进行收尾工作,往往在处理数据的时候用到,例如在写hdfs(hadoop的文件系统)数据的时候,在结束时需要进行数据clear,则需要进行数据收尾。当然,根据官网及实际的测验,该方法往往是执行失败的。
Q:发布topologies 到远程集群时,出现Nimbus host is not set 异常,请问是什么问题?
A:原因是Nimbus 没有被正确启动起来,可能是storm.yaml 文件没有配置,或者配置有问题。解决方法是:打开storm.yaml 文件正确配置:nimbus.host: "xxx.xxx.xxx.xxx",重启nimbus后台程序即可。

小伙伴们冲鸭,后台留言区等着你!
关于Hadoop,今天你学到了什么?还有哪些不懂的?除此还对哪些话题感兴趣?快来留言区打卡啦!留言方式:打开第XX天,答:……
同时欢迎大家搜集更多问题,投稿给我们!风里雨里留言区里等你~
福利
1、扫描添加小编微信,备注“姓名+公司职位”,加入【云计算学习交流群】,和志同道合的朋友们共同打卡学习!

2、公众号后台回复:白皮书,获取IDC最新数据白皮书整理资料!
推荐阅读:





