基于大数据搭建社交好友推荐系统
云栖君导读:本文来自资深架构师翟永东“基于MaxCompute搭建社交好友推荐系统”为主题的分享,主要对大数据在好友推荐系统中的应用、好友推荐系统的分析模型、好友推荐系统在阿里云上的实现方式和MaxCompute技术进行了精彩的介绍。
大数据在好友推荐系统中的应用
给大家分享一下基于MaxCompute搭建社交好友推荐系统,使用MaxCompute阿里的大数据计算的方法可以做哪些事情,如果说是以社交好友的推荐,来给大家去演示一下。好友推荐系统它的一个场景介绍,现在大家都在讲大数据,如果想去使用这些数据,我们认为它需要具备三个要素,第一个要素是海量的数据,数据量越多越好,只有数据量达到了足够大,我们才能够成为一个数据里面潜在去挖掘出来。第二个是处理数据的能力,有了这样很高的快速处理数据的能力,可以让我们更快的去把数据里面的信息挖掘出来。第三个是商业变现的一个场景,我们采集大数据的时候,并不是数据越多越好,一定要有一个具体的场景。以推荐系统为例来看一下大数据的一个应用。
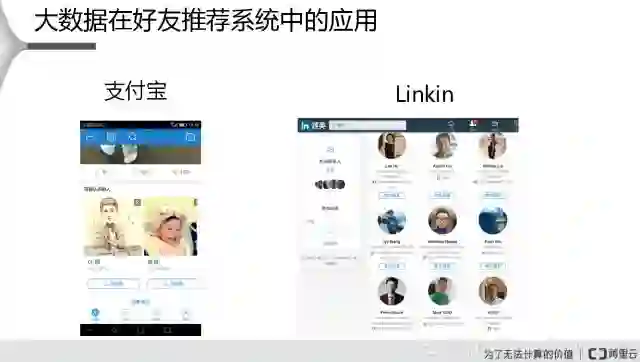
左边是支付宝,在支付宝一打开的时候,下面会有一栏推荐可能是你的好友,一般的话下面的那些人都是你认识的,可能还没加他们为好友。右侧是Linkin,它是一个求职社交网站,Linkin也会给你这样的一个推荐,会告诉你哪一些用户是你潜在的好友,而且Linkin会告诉你这个好友跟你是一度的关系的还是两度的关系或者是三度的关系。潜在关联性高的,会在前面直接显示出来,潜在关联性没有那么高的也会在后面显示出来,这两个都是典型的一个好友推荐。
进行好友推荐的时候,怎么给用户进行推荐,首先这两个人是非好友的关系,接着我们去看一下他们俩潜在共同好友的处理,通过这种方式去给用户推送,比方说潜在好友数量多,我就认为这两个人是好友关系,就是通过这种方式来实现的。
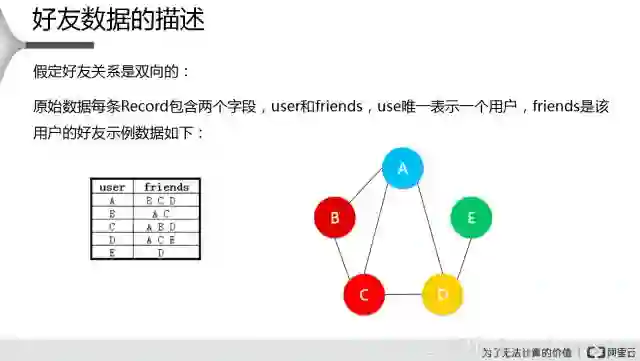
上图的右侧是人与人之间的一个社交关系的服务,比如说A跟B是一个好友,我们可以通过这五个方式画出来,让机器去分析这些数据,需要把右边这种社交的关系,转换成机器可以识别的数据,转换成左侧这样的二维表的数据,比如说A跟B、C、D他们之间是好友,我们左侧是A跟B、C、D是好友关系,剩下这些也是类似的,这样就可以把这个表传到机器里面进行分析,比方说通过分析之后,发现A跟E有一个共同好友,B跟D有两个共同好友,然后C跟E有一个共同好友。这个时候就可以推荐B跟D他两个是一个潜在的好友,而排在前面,A跟E或者C跟E排在概率往下,稍微低一些,潜在好友多的排在前面,潜在好友少的排在后面,通过这种方式来进行排列,这个是我们期望的结果。
好友推荐系统的分析模型
我们怎么来去计算呢?我们一般使用方式是什么呢?使用的是MapReduce这样的一个计算模型,MapReduce是一种编程模型,用于大规模数据集的并行运算,它由三部分组成分别是Map、Combine、Reduce。
以好友推荐这样的一个场景为例。
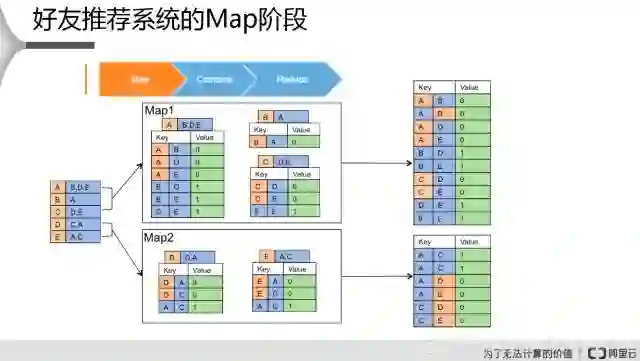
首先输入左侧机器可以识别的数据,输入之后,在Map端先把数据做一个拆分,拆分成两份不同的数据,在拆分的同时把它转换成key、value的类型,比方说A、B、D、E这几行数据转换成什么呢?A跟B,然后value是零,零代表他们两个已经是好友。如果两个不是好友的话,自定义这一行数据,B跟D不是好友,就把他的值视为1。下面的B、E,还有D跟E也是1。把原来一行数据转换成Key、Value这个形式的数据,类似于右边这样的数据,上面是key、value的一个类型,下面也是类似的。这个是在Map做的事情,把这个数据通过两个key、value进行一个拆分,转化成key、value这样的一个类型。
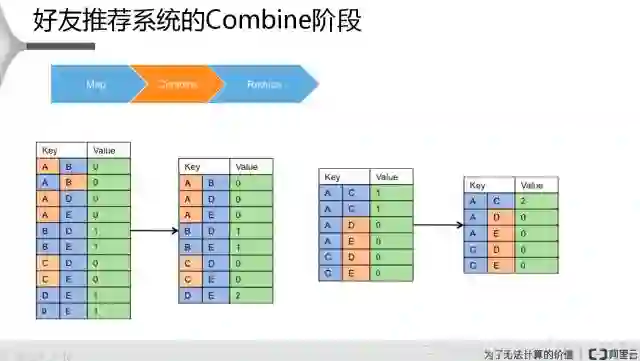
Combine是对数据先做一个本地的汇总,先看到有一些数据是重复的,比如说A跟B是零,A跟B是零,出现了两次,这个时候就存一个就可以。其他类似的,这样我把这些数据在本地做完汇总,类似于这张表,这两个数据。
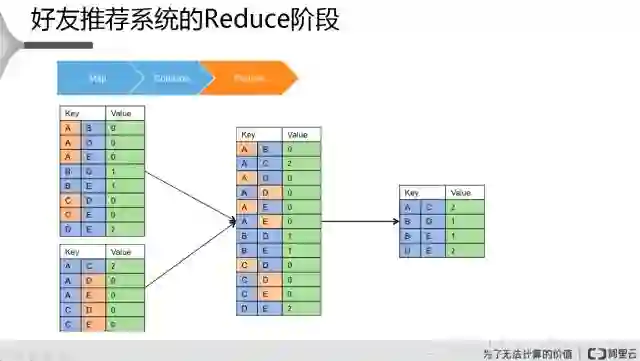
接着是第三步是Reduce阶段,Reduce是对这些数据进行一个汇总,把两边数据汇总到一起,然后对每一个Key值对应唯一的一个value值做一个汇总,这个就是它最终计算的一个结果。如果两个用户已经是好友了,Value值是零的话,不需要再给他推荐。所以说A、B如果是零的话就剔掉,只需要知道它的value值是大于零的,有潜在好友,同时这两个人目前还是非好友的关系,这个就达到了想要的效果。
好友推荐系统在阿里云上的实现方式
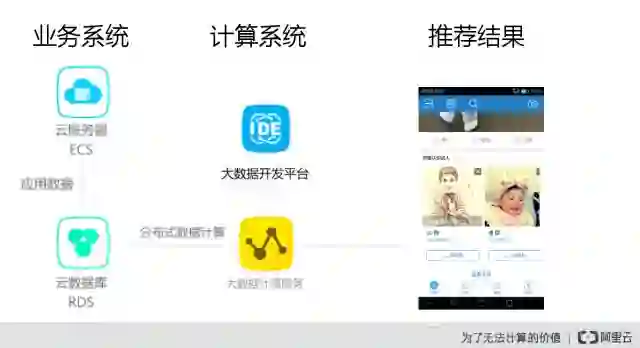
好友推荐阿里云实现整个的架构是怎么样的呢?比方现在有一个社交软件是一个业务系统,前端使用阿里云的云服务器ECS去部署整个的社交的软件的应用,入库的一些数据存到阿里的RDS,这个就是当前的一个社交应用系统。业务系统里面产生了一个数据,怎么来对数据进行分析,首先需要在数据库里边把这个数据提取出来,提取到阿里云的大计算服务MaxCompute里面,很类似于我们传统做数仓的时候ETL的一个过程,会利用阿里云的大数据开发平台对数据进行分析和处理。
使用它可以快速便捷的去开发我们数据植入或者数据这样的一个流程,这个就是会使用大数据开发平台和大数据制造,结果是一个数据分析结果,还需要前端的应用数据对分析出来的结果展示出来。
MaxCompute的技术特点
对于MaxCompute的一些技术特点主要有一下几点:
分布式:分布式集群、跨集群技术、可灵活扩展。
安全性:从安全性来讲具有自动存储纠错、沙箱机制、多分备份。
易用:具有标准API、全面支持SQL、上传下载工具。
权限控制:多租户管理、用户权限策略、数据访问策略。
MaxCompute的使用场景
对于MaxCompute的使用的场景,可以使用MaxCompute搭建自己的一个数据仓库,同时,MaxCompute还可以提供一种分布式的应用系统,比方说可以通过图计算,或者通过有效的宽幅的方式,可以搭建一个工作流;比方说数据分析并不是说只分析一天就不分析了,其实是周期性的。如果数据每天要分析一次,可以在MaxCompute里面生成那样的任务工作流,设置一个周期性的调度,每天要让它调度一次,MaxCompute可以按照设计好的工作流,调动周期,然后去运行;MaxCompute在机器学习里面也是有用的,因为机器学习会用到MaxCompute分析出来的数据,其他相类似的服务对数据进行分析处理,分析出来的结果数据放到机器学习平台里面,让机器通过一些算法一些模型,去学习这里边的数据,生成一个希望达到的一个模型。
大数据开发套件DataIDE
另外一个除了MaxCompute之外还有一个会用到一个大数据开发操作DateIDE,大数据开发套件DataIDE(现名:数据工场DataWorks)提供一个高效、安全的离线数据开发环境。为什么介绍它呢?是因为DateIDE只是对数据任务工作流的一个开发,其实底层的数据处理,数据分析,都是在MaxCompute上完成,可以简单理解为DateIDE就是一个图象化的数据开发的服务,它是为了帮助我们更好去使用MaxCompute。也可以看到,这我们可以在DateIDE进行一个开发,不需要直接在MaxCompute里面进行开发了,在MaxCompute开发的一个效果,跟在DateIDE里面开发的效果对比。
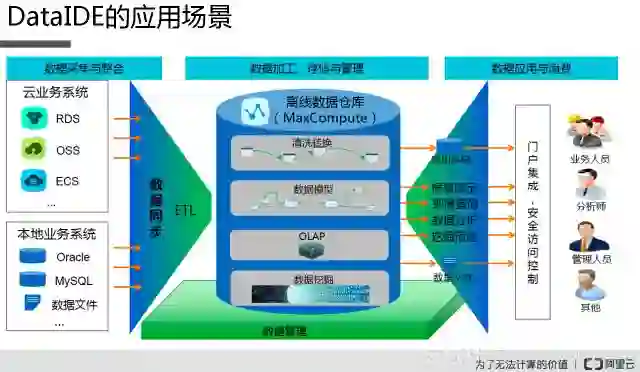
这个是DateIDE整个应用的一个场景,我们在进行数据分析的时候,需要对里面的原数据进行整合统一保存,这个时候可以在DateIDE上实现,把所有的原数据的信息统一汇总到MaxCompute里面进行一个保存,同时还可以DateIDE进行数据的加工,存储等操作都可以在DateIDE上完成。DateIDE在整个数据分析的过程中可以对数据存储、分析、处理、集群等处理。
MaxCompute的应用开发流程
MaxCompute的应用开发流程一共需要六步分别是:
安装配置环境
开发MR程序
本地模式测试脚本
导处jar包
上传到MaxCompute项目空间
在MaxCompute中使用MR
下面我们以一个好友推荐的事例来详细讲解一下这个过程。首先需要去安装MaxCompute客户端,使用它的好处是可以在本地通过命令的方式去远程使用阿里云的MaxCompute,在本地只需要配置MaxCompute信息就可以。另外还需要去配置自己的一个开发环境,因为现在阿里云的MaxCompute主要是两种语言,一种是Java一种是Eclipse。然后新建项目,在开发新建项目的时候,大家可以看到这个红包,这个红包就是需要配置本地的客户端的信息。在进入到写代码的过程 。
接下来就是简单的测试,开发之后要测试,这个代码是不是按照设想的方式去工作的。接着这边输入的是一个测试数据,这个输出的数据类别,就是输出的这样的一个表格,表格有三列,第一类是用户A,第二类是用户B,第三类是两个潜在的共同好友的数量,只需要关注这三个数据就可以,然后就可以测试。接着第三个本地运行的数据的代码,运行的结果就是通过本地的开发测试,在本地测试的时候这边有一个数据,你第一步需要选择是使用哪一个的一个项目处理。第二个要选择输入表和输出表,要告诉他输出表是哪个,输出表的目的是什么,告诉这个程序,你输出的结果保存在表里面,配置好点击运行这个结果就出来了。
本地开发测试成功之后,接着要把它打成一个Jar包,然后上传到阿里云上,就是上传到MaxCompute的集群里边。第二个打完Jar包以后添加资源,下面就把刚刚输出的Jar包,通过资源的管理,把刚刚输入的Jar包上传上来。本地开发测试好的一个MR的Jar包已经上传到MaxCompute集群里边。
上传好了之后就可以使用它,去新建一个任务,然后这个任务去起个名字,这个任务跟哪一个Jar包相关联,接着是OPENBMR,我们选的是MR的程序,所以里面选的是OPENMR模块,生成这样的一个任务,进入到编辑页面,在编辑页面里面首先告诉它,这个OPENMR这样的一个任务,使用的是上传的好友推荐的一个Jar包,最下面告诉它Jar包里面的程序的逻辑是什么,在这个里面制定好之后点击运行结果就会出来。这个就是我们在本地开发测试,把资源上传到MaxCompute的集群里面,接着在集群里面去使用我在本地开发好的Jar包,这个就是整个的一个开发和部署的一个流程。
精彩活动
识别下方二维码
看看你在云栖社区排第多少位?
你的2018关键词是什么?
进入H5还能抽相机、阿里云代金券、公仔等好礼!
-END-

云栖社区
ID:yunqiinsight
云计算丨互联网架构丨大数据丨机器学习丨运维






