Redis高负载下的中断优化

总第229篇
2018年 第21篇
背景
2017年年初以来,随着Redis产品的用户量越来越大,接入服务越来越多,再加上美团点评Memcache和Redis两套缓存融合,Redis服务端的总体请求量从年初最开始日访问量百亿次级别上涨到高峰时段的万亿次级别,给运维和架构团队都带来了极大的挑战。
原本稳定的环境也因为请求量的上涨带来了很多不稳定的因素,其中一直困扰我们的就是网卡丢包问题。起初线上存在部分Redis节点还在使用千兆网卡的老旧服务器,而缓存服务往往需要承载极高的查询量,并要求毫秒级的响应速度,如此一来千兆网卡很快就出现了瓶颈。经过整治,我们将千兆网卡服务器替换为了万兆网卡服务器,本以为可以高枕无忧,但是没想到,在业务高峰时段,机器也竟然出现了丢包问题,而此时网卡带宽使用还远远没有达到瓶颈。
定位网络丢包的原因
从异常指标入手
首先,我们在系统监控的net.if.in.dropped指标中,看到有大量数据丢包异常,那么第一步就是要了解这个指标代表什么。
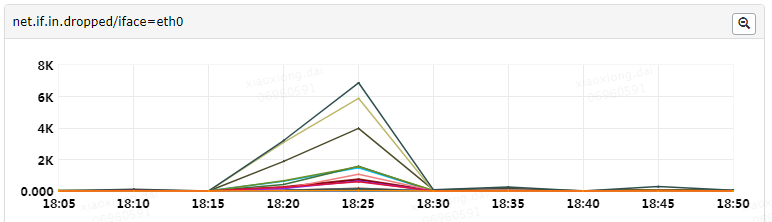
这个指标的数据源,是读取/proc/net/dev中的数据,监控Agent做简单的处理之后上报。以下为/proc/net/dev 的一个示例,可以看到第一行Receive代表in,Transmit代表out,第二行即各个表头字段,再往后每一行代表一个网卡设备具体的值。

其中各个字段意义如下:
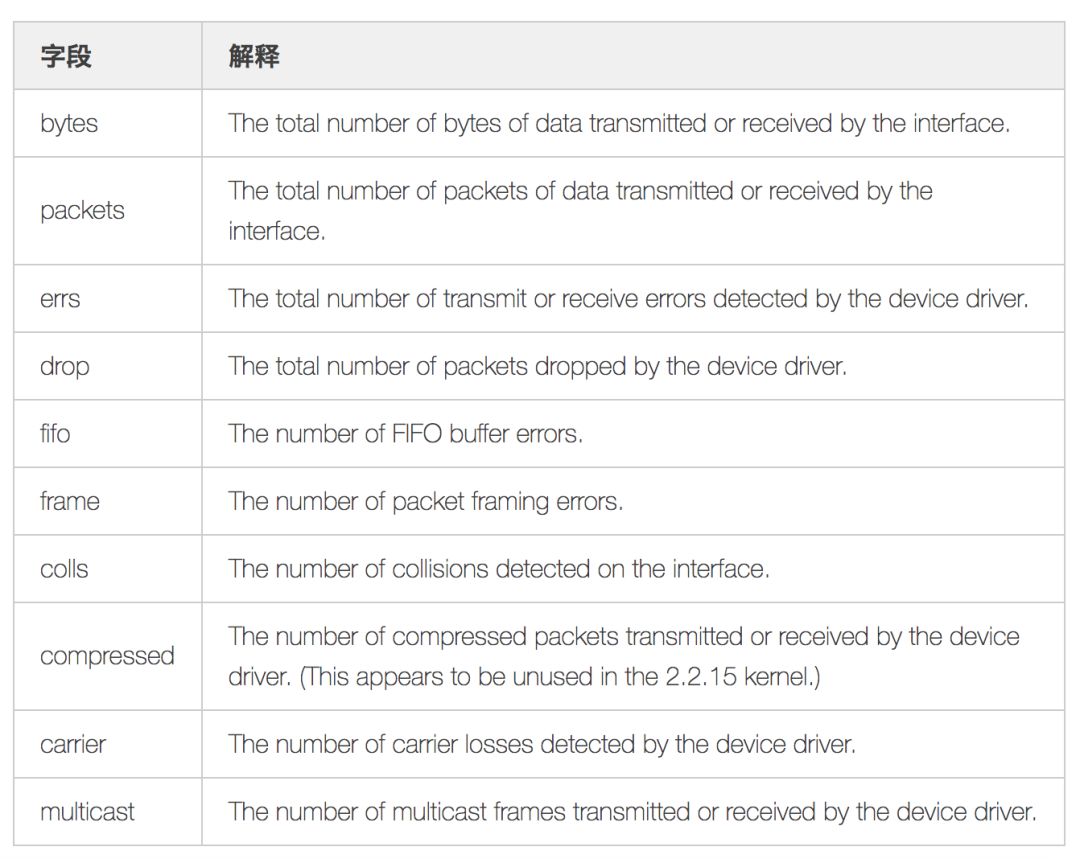
/proc/net/dev的数据来源,根据源码文件net/core/net-procfs.c,可以知道上述指标是通过其中的dev_seq_show()函数和dev_seq_printf_stats()函数输出的:通过上述字段解释,我们可以了解丢包发生在网卡设备驱动层面;但是想要了解真正的原因,需要继续深入源码。
static int dev_seq_show(struct seq_file *seq, void *v)
{
if (v == SEQ_START_TOKEN)
/* 输出/proc/net/dev表头部分 */
seq_puts(seq, "Inter-| Receive "
" | Transmit\n"
" face |bytes packets errs drop fifo frame "
"compressed multicast|bytes packets errs "
"drop fifo colls carrier compressed\n");
else
/* 输出/proc/net/dev数据部分 */
dev_seq_printf_stats(seq, v);
return 0;
}
static void dev_seq_printf_stats(struct seq_file *seq, struct net_device *dev)
{
struct rtnl_link_stats64 temp;
/* 数据源从下面的函数中取得 */
const struct rtnl_link_stats64 *stats = dev_get_stats(dev, &temp);
/* /proc/net/dev 各个字段的数据算法 */
seq_printf(seq, "%6s: %7llu %7llu %4llu %4llu %4llu %5llu %10llu %9llu "
"%8llu %7llu %4llu %4llu %4llu %5llu %7llu %10llu\n",
dev->name, stats->rx_bytes, stats->rx_packets,
stats->rx_errors,
stats->rx_dropped + stats->rx_missed_errors,
stats->rx_fifo_errors,
stats->rx_length_errors + stats->rx_over_errors +
stats->rx_crc_errors + stats->rx_frame_errors,
stats->rx_compressed, stats->multicast,
stats->tx_bytes, stats->tx_packets,
stats->tx_errors, stats->tx_dropped,
stats->tx_fifo_errors, stats->collisions,
stats->tx_carrier_errors +
stats->tx_aborted_errors +
stats->tx_window_errors +
stats->tx_heartbeat_errors,
stats->tx_compressed);
}dev_seq_printf_stats()函数里,对应drop输出的部分,能看到由两块组成:stats->rx_dropped+stats->rx_missed_errors。
继续查找dev_get_stats函数可知,rx_dropped和rx_missed_errors 都是从设备获取的,并且需要设备驱动实现。
/**
* dev_get_stats - get network device statistics
* @dev: device to get statistics from
* @storage: place to store stats
*
* Get network statistics from device. Return @storage.
* The device driver may provide its own method by setting
* dev->netdev_ops->get_stats64 or dev->netdev_ops->get_stats;
* otherwise the internal statistics structure is used.
*/
struct rtnl_link_stats64 *dev_get_stats(struct net_device *dev,
struct rtnl_link_stats64 *storage)
{
const struct net_device_ops *ops = dev->netdev_ops;
if (ops->ndo_get_stats64) {
memset(storage, 0, sizeof(*storage));
ops->ndo_get_stats64(dev, storage);
} else if (ops->ndo_get_stats) {
netdev_stats_to_stats64(storage, ops->ndo_get_stats(dev));
} else {
netdev_stats_to_stats64(storage, &dev->stats);
}
storage->rx_dropped += (unsigned long)atomic_long_read(&dev->rx_dropped);
storage->tx_dropped += (unsigned long)atomic_long_read(&dev->tx_dropped);
storage->rx_nohandler += (unsigned long)atomic_long_read(&dev->rx_nohandler);
return storage;
}结构体 rtnl_link_stats64 的定义在 /usr/include/linux/if_link.h 中:
/* The main device statistics structure */
struct rtnl_link_stats64 {
__u64 rx_packets; /* total packets received */
__u64 tx_packets; /* total packets transmitted */
__u64 rx_bytes; /* total bytes received */
__u64 tx_bytes; /* total bytes transmitted */
__u64 rx_errors; /* bad packets received */
__u64 tx_errors; /* packet transmit problems */
__u64 rx_dropped; /* no space in linux buffers */
__u64 tx_dropped; /* no space available in linux */
__u64 multicast; /* multicast packets received */
__u64 collisions;
/* detailed rx_errors: */
__u64 rx_length_errors;
__u64 rx_over_errors; /* receiver ring buff overflow */
__u64 rx_crc_errors; /* recved pkt with crc error */
__u64 rx_frame_errors; /* recv'd frame alignment error */
__u64 rx_fifo_errors; /* recv'r fifo overrun */
__u64 rx_missed_errors; /* receiver missed packet */
/* detailed tx_errors */
__u64 tx_aborted_errors;
__u64 tx_carrier_errors;
__u64 tx_fifo_errors;
__u64 tx_heartbeat_errors;
__u64 tx_window_errors;
/* for cslip etc */
__u64 rx_compressed;
__u64 tx_compressed;
};至此,我们知道rx_dropped是Linux中的缓冲区空间不足导致的丢包,而rx_missed_errors则在注释中写的比较笼统。有资料指出,rx_missed_errors是fifo队列(即rx ring buffer)满而丢弃的数量,但这样的话也就和rx_fifo_errors等同了。后来公司内网络内核研发大牛王伟给了我们点拨:不同网卡自己实现不一样,比如Intel的igb网卡rx_fifo_errors在missed的基础上,还加上了RQDPC计数,而ixgbe就没这个统计。RQDPC计数是描述符不够的计数,missed是fifo满的计数。所以对于ixgbe来说,rx_fifo_errors和rx_missed_errors确实是等同的。
通过命令ethtool -S eth0可以查看网卡一些统计信息,其中就包含了上文提到的几个重要指标rx_dropped、rx_missed_errors、rx_fifo_errors等。但实际测试后,我发现不同网卡型号给出的指标略有不同,比如Intel ixgbe就能取到,而Broadcom bnx2/tg3则只能取到rx_discards(对应rx_fifo_errors)、rx_fw_discards(对应rx_dropped)。这表明,各家网卡厂商设备内部对这些丢包的计数器、指标的定义略有不同,但通过驱动向内核提供的统计数据都封装成了struct rtnl_link_stats64定义的格式。
在对丢包服务器进行检查后,发现rx_missed_errors为0,丢包全部来自rx_dropped。说明丢包发生在Linux内核的缓冲区中。接下来,我们要继续探索到底是什么缓冲区引起了丢包问题,这就需要完整地了解服务器接收数据包的过程。
了解接收数据包的流程
接收数据包是一个复杂的过程,涉及很多底层的技术细节,但大致需要以下几个步骤:
网卡收到数据包。
将数据包从网卡硬件缓存转移到服务器内存中。
通知内核处理。
经过TCP/IP协议逐层处理。
应用程序通过read()从socket buffer读取数据。
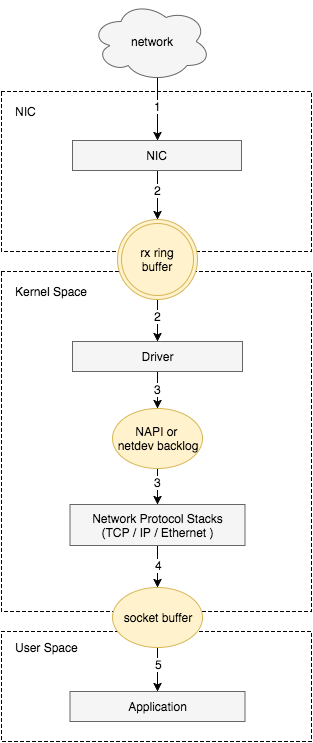
将网卡收到的数据包转移到主机内存(NIC与驱动交互)
NIC在接收到数据包之后,首先需要将数据同步到内核中,这中间的桥梁是rx ring buffer。它是由NIC和驱动程序共享的一片区域,事实上,rx ring buffer存储的并不是实际的packet数据,而是一个描述符,这个描述符指向了它真正的存储地址,具体流程如下:
驱动在内存中分配一片缓冲区用来接收数据包,叫做sk_buffer;
将上述缓冲区的地址和大小(即接收描述符),加入到rx ring buffer。描述符中的缓冲区地址是DMA使用的物理地址;
驱动通知网卡有一个新的描述符;
网卡从rx ring buffer中取出描述符,从而获知缓冲区的地址和大小;
网卡收到新的数据包;
网卡将新数据包通过DMA直接写到sk_buffer中。
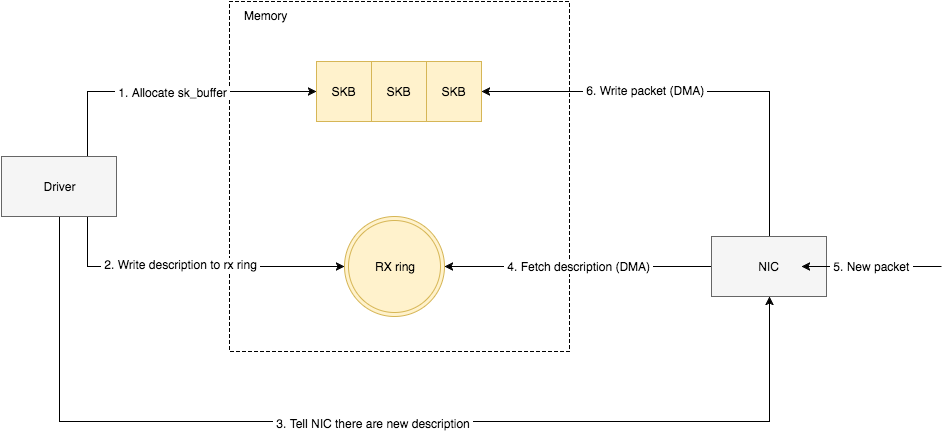
当驱动处理速度跟不上网卡收包速度时,驱动来不及分配缓冲区,NIC接收到的数据包无法及时写到sk_buffer,就会产生堆积,当NIC内部缓冲区写满后,就会丢弃部分数据,引起丢包。这部分丢包为rx_fifo_errors,在 /proc/net/dev中体现为fifo字段增长,在ifconfig中体现为overruns指标增长。
通知系统内核处理(驱动与Linux内核交互)
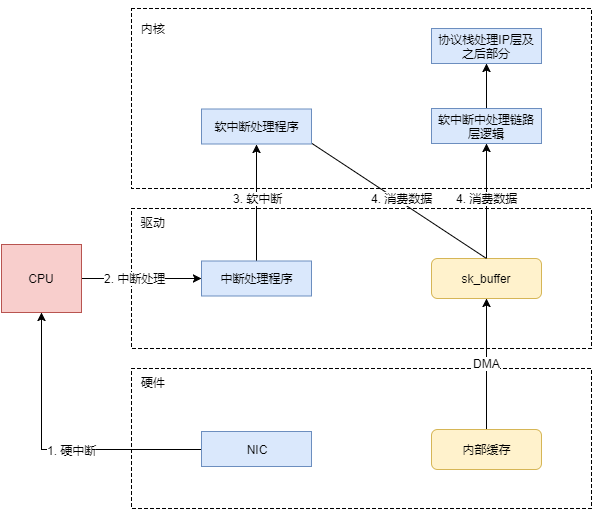
这个时候,数据包已经被转移到了sk_buffer中。前文提到,这是驱动程序在内存中分配的一片缓冲区,并且是通过DMA写入的,这种方式不依赖CPU直接将数据写到了内存中,意味着对内核来说,其实并不知道已经有新数据到了内存中。那么如何让内核知道有新数据进来了呢?答案就是中断,通过中断告诉内核有新数据进来了,并需要进行后续处理。
提到中断,就涉及到硬中断和软中断,首先需要简单了解一下它们的区别:
硬中断: 由硬件自己生成,具有随机性,硬中断被CPU接收后,触发执行中断处理程序。中断处理程序只会处理关键性的、短时间内可以处理完的工作,剩余耗时较长工作,会放到中断之后,由软中断来完成。硬中断也被称为上半部分。
软中断: 由硬中断对应的中断处理程序生成,往往是预先在代码里实现好的,不具有随机性。(除此之外,也有应用程序触发的软中断,与本文讨论的网卡收包无关。)也被称为下半部分。
当NIC把数据包通过DMA复制到内核缓冲区sk_buffer后,NIC立即发起一个硬件中断。CPU接收后,首先进入上半部分,网卡中断对应的中断处理程序是网卡驱动程序的一部分,之后由它发起软中断,进入下半部分,开始消费sk_buffer中的数据,交给内核协议栈处理。
通过中断,能够快速及时地响应网卡数据请求,但如果数据量大,那么会产生大量中断请求,CPU大部分时间都忙于处理中断,效率很低。为了解决这个问题,现在的内核及驱动都采用一种叫NAPI(new API)的方式进行数据处理,其原理可以简单理解为 中断+轮询,在数据量大时,一次中断后通过轮询接收一定数量包再返回,避免产生多次中断。
整个中断过程的源码部分比较复杂,并且不同驱动的厂商及版本也会存在一定的区别。 以下调用关系基于Linux-3.10.108及内核自带驱动drivers/net/ethernet/intel/ixgbe:
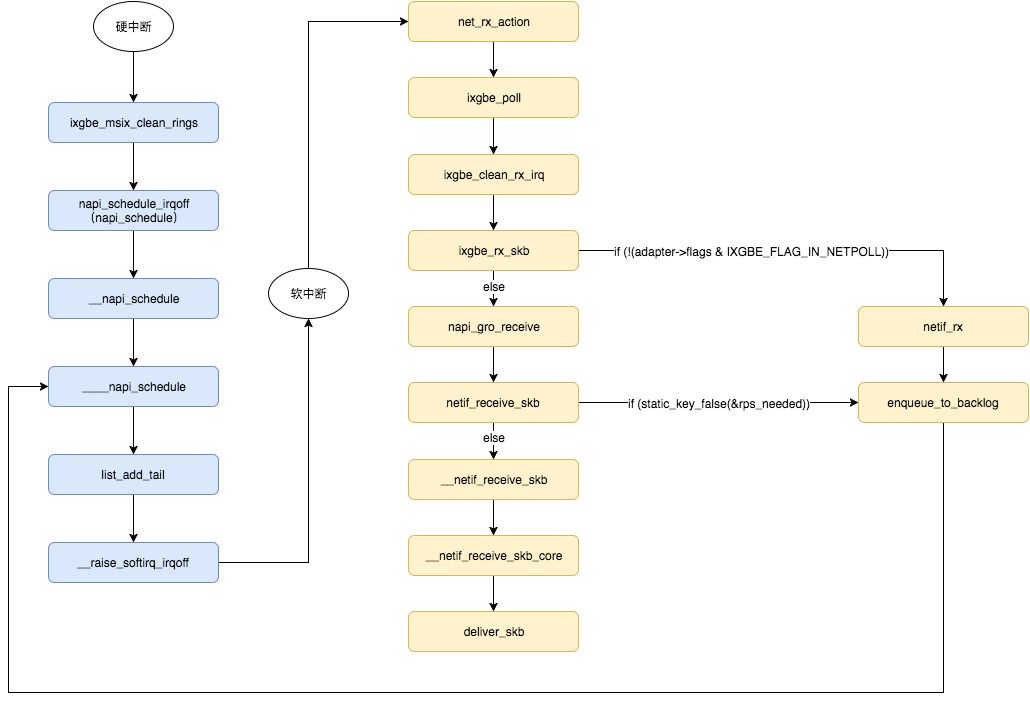
注意到,enqueue_to_backlog函数中,会对CPU的softnet_data 实例中的接收队列(input_pkt_queue)进行判断,如果队列中的数据长度超过netdev_max_backlog ,那么数据包将直接丢弃,这就产生了丢包。netdev_max_backlog是由系统参数net.core.netdev_max_backlog指定的,默认大小是 1000。
/*
* enqueue_to_backlog is called to queue an skb to a per CPU backlog
* queue (may be a remote CPU queue).
*/
static int enqueue_to_backlog(struct sk_buff *skb, int cpu,
unsigned int *qtail)
{
struct softnet_data *sd;
unsigned long flags;
sd = &per_cpu(softnet_data, cpu);
local_irq_save(flags);
rps_lock(sd);
/* 判断接收队列是否满,队列长度为 netdev_max_backlog */
if (skb_queue_len(&sd->input_pkt_queue) <= netdev_max_backlog) {
if (skb_queue_len(&sd->input_pkt_queue)) {
enqueue:
/* 队列如果不会空,将数据包添加到队列尾 */
__skb_queue_tail(&sd->input_pkt_queue, skb);
input_queue_tail_incr_save(sd, qtail);
rps_unlock(sd);
local_irq_restore(flags);
return NET_RX_SUCCESS;
}
/* Schedule NAPI for backlog device
* We can use non atomic operation since we own the queue lock
*/
/* 队列如果为空,回到 ____napi_schedule加入poll_list轮询部分,并重新发起软中断 */
if (!__test_and_set_bit(NAPI_STATE_SCHED, &sd->backlog.state)) {
if (!rps_ipi_queued(sd))
____napi_schedule(sd, &sd->backlog);
}
goto enqueue;
}
/* 队列满则直接丢弃,对应计数器 +1 */
sd->dropped++;
rps_unlock(sd);
local_irq_restore(flags);
atomic_long_inc(&skb->dev->rx_dropped);
kfree_skb(skb);
return NET_RX_DROP;
}内核会为每个CPU Core都实例化一个softnet_data对象,这个对象中的input_pkt_queue用于管理接收的数据包。假如所有的中断都由一个CPU Core来处理的话,那么所有数据包只能经由这个CPU的input_pkt_queue,如果接收的数据包数量非常大,超过中断处理速度,那么input_pkt_queue中的数据包就会堆积,直至超过netdev_max_backlog,引起丢包。这部分丢包可以在cat /proc/net/softnet_stat的输出结果中进行确认:
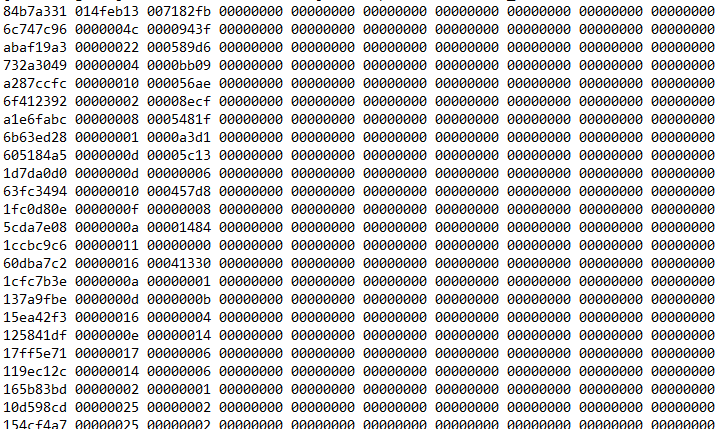
其中每行代表一个CPU,第一列是中断处理程序接收的帧数,第二列是由于超过 netdev_max_backlog 而丢弃的帧数。 第三列则是在 net_rx_action 函数中处理数据包超过 netdev_budget 指定数量或运行时间超过2个时间片的次数。在检查线上服务器之后,发现第一行CPU。硬中断的中断号及统计数据可以在/proc/interrupts中看到,对于多队列网卡,当系统启动并加载NIC设备驱动程序模块时,每个RXTX队列会被初始化分配一个唯一的中断向量号,它通知中断处理程序该中断来自哪个NIC队列。在默认情况下,所有队列的硬中断都由CPU 0处理,因此对应的软中断逻辑也会在CPU 0上处理,在服务器 TOP 的输出中,也可以观察到 %si 软中断部分,CPU 0的占比比其他core高出一截。
到这里其实有存在一个疑惑,我们线上服务器的内核版本及网卡都支持NAPI,而NAPI的处理逻辑是不会走到enqueue_to_backlog 中的,enqueue_to_backlog主要是非NAPI的处理流程中使用的。对此,我们觉得可能和当前使用的Docker架构有关,事实上,我们通过net.if.dropped 指标获取到的丢包,都发生在Docker虚拟网卡上,而非宿主机物理网卡上,因此很可能是Docker虚拟网桥转发数据包之后,虚拟网卡层面产生的丢包,这里由于涉及虚拟化部分,就不进一步分析了。
驱动及内核处理过程中的几个重要函数:
(1)注册中断号及中断处理程序,根据网卡是否支持MSI/MSIX,结果为:MSIX → ixgbe_msix_clean_rings,MSI → ixgbe_intr,都不支持 → ixgbe_intr。
/**
* 文件:ixgbe_main.c
* ixgbe_request_irq - initialize interrupts
* @adapter: board private structure
*
* Attempts to configure interrupts using the best available
* capabilities of the hardware and kernel.
**/
static int ixgbe_request_irq(struct ixgbe_adapter *adapter)
{
struct net_device *netdev = adapter->netdev;
int err;
/* 支持MSIX,调用 ixgbe_request_msix_irqs 设置中断处理程序*/
if (adapter->flags & IXGBE_FLAG_MSIX_ENABLED)
err = ixgbe_request_msix_irqs(adapter);
/* 支持MSI,直接设置 ixgbe_intr 为中断处理程序 */
else if (adapter->flags & IXGBE_FLAG_MSI_ENABLED)
err = request_irq(adapter->pdev->irq, &ixgbe_intr, 0,
netdev->name, adapter);
/* 都不支持的情况,直接设置 ixgbe_intr 为中断处理程序 */
else
err = request_irq(adapter->pdev->irq, &ixgbe_intr, IRQF_SHARED,
netdev->name, adapter);
if (err)
e_err(probe, "request_irq failed, Error %d\n", err);
return err;
}
/**
* 文件:ixgbe_main.c
* ixgbe_request_msix_irqs - Initialize MSI-X interrupts
* @adapter: board private structure
*
* ixgbe_request_msix_irqs allocates MSI-X vectors and requests
* interrupts from the kernel.
**/
static int (struct ixgbe_adapter *adapter)
{
…
for (vector = 0; vector < adapter->num_q_vectors; vector++) {
struct ixgbe_q_vector *q_vector = adapter->q_vector[vector];
struct msix_entry *entry = &adapter->msix_entries[vector];
/* 设置中断处理入口函数为 ixgbe_msix_clean_rings */
err = request_irq(entry->vector, &ixgbe_msix_clean_rings, 0,
q_vector->name, q_vector);
if (err) {
e_err(probe, "request_irq failed for MSIX interrupt '%s' "
"Error: %d\n", q_vector->name, err);
goto free_queue_irqs;
}
…
}
}
(2)线上的多队列网卡均支持MSIX,中断处理程序入口为ixgbe_msix_clean_rings,里面调用了函数napi_schedule(&q_vector->napi)。
/**
* 文件:ixgbe_main.c
**/
static irqreturn_t ixgbe_msix_clean_rings(int irq, void *data)
{
struct ixgbe_q_vector *q_vector = data;
/* EIAM disabled interrupts (on this vector) for us */
if (q_vector->rx.ring || q_vector->tx.ring)
napi_schedule(&q_vector->napi);
return IRQ_HANDLED;
}(3)之后经过一些列调用,直到发起名为NET_RX_SOFTIRQ的软中断。到这里完成了硬中断部分,进入软中断部分,同时也上升到了内核层面。
/**
* 文件:include/linux/netdevice.h
* napi_schedule - schedule NAPI poll
* @n: NAPI context
*
* Schedule NAPI poll routine to be called if it is not already
* running.
*/
static inline void napi_schedule(struct napi_struct *n)
{
if (napi_schedule_prep(n))
/* 注意下面调用的这个函数名字前是两个下划线 */
__napi_schedule(n);
}
/**
* 文件:net/core/dev.c
* __napi_schedule - schedule for receive
* @n: entry to schedule
*
* The entry's receive function will be scheduled to run.
* Consider using __napi_schedule_irqoff() if hard irqs are masked.
*/
void __napi_schedule(struct napi_struct *n)
{
unsigned long flags;
/* local_irq_save用来保存中断状态,并禁止中断 */
local_irq_save(flags);
/* 注意下面调用的这个函数名字前是四个下划线,传入的 softnet_data 是当前CPU */
____napi_schedule(this_cpu_ptr(&softnet_data), n);
local_irq_restore(flags);
}
/* Called with irq disabled */
static inline void ____napi_schedule(struct softnet_data *sd,
struct napi_struct *napi)
{
/* 将 napi_struct 加入 softnet_data 的 poll_list */
list_add_tail(&napi->poll_list, &sd->poll_list);
/* 发起软中断 NET_RX_SOFTIRQ */
__raise_softirq_irqoff(NET_RX_SOFTIRQ);
}(4)NET_RX_SOFTIRQ对应的软中断处理程序接口是net_rx_action()。
/*
* 文件:net/core/dev.c
* Initialize the DEV module. At boot time this walks the device list and
* unhooks any devices that fail to initialise (normally hardware not
* present) and leaves us with a valid list of present and active devices.
*
*/
/*
* This is called single threaded during boot, so no need
* to take the rtnl semaphore.
*/
static int __init net_dev_init(void)
{
…
/* 分别注册TX和RX软中断的处理程序 */
open_softirq(NET_TX_SOFTIRQ, net_tx_action);
open_softirq(NET_RX_SOFTIRQ, net_rx_action);
…
}
(5)net_rx_action功能就是轮询调用poll方法,这里就是ixgbe_poll。一次轮询的数据包数量不能超过内核参数net.core.netdev_budget指定的数量(默认值300),并且轮询时间不能超过2个时间片。这个机制保证了单次软中断处理不会耗时太久影响被中断的程序。
/* 文件:net/core/dev.c */
static void net_rx_action(struct softirq_action *h)
{
struct softnet_data *sd = &__get_cpu_var(softnet_data);
unsigned long time_limit = jiffies + 2;
int budget = netdev_budget;
void *have;
local_irq_disable();
while (!list_empty(&sd->poll_list)) {
struct napi_struct *n;
int work, weight;
/* If softirq window is exhuasted then punt.
* Allow this to run for 2 jiffies since which will allow
* an average latency of 1.5/HZ.
*/
/* 判断处理包数是否超过 netdev_budget 及时间是否超过2个时间片 */
if (unlikely(budget <= 0 || time_after_eq(jiffies, time_limit)))
goto softnet_break;
local_irq_enable();
/* Even though interrupts have been re-enabled, this
* access is safe because interrupts can only add new
* entries to the tail of this list, and only ->poll()
* calls can remove this head entry from the list.
*/
n = list_first_entry(&sd->poll_list, struct napi_struct, poll_list);
have = netpoll_poll_lock(n);
weight = n->weight;
/* This NAPI_STATE_SCHED test is for avoiding a race
* with netpoll's poll_napi(). Only the entity which
* obtains the lock and sees NAPI_STATE_SCHED set will
* actually make the ->poll() call. Therefore we avoid
* accidentally calling ->poll() when NAPI is not scheduled.
*/
work = 0;
if (test_bit(NAPI_STATE_SCHED, &n->state)) {
work = n->poll(n, weight);
trace_napi_poll(n);
}
……
}
}
(6)ixgbe_poll之后的一系列调用就不一一详述了,有兴趣的同学可以自行研究,软中断部分有几个地方会有类似if (static_key_false(&rps_needed))这样的判断,会进入前文所述有丢包风险的enqueue_to_backlog函数。 这里的逻辑为判断是否启用了RPS机制,RPS是早期单队列网卡上将软中断负载均衡到多个CPU Core的技术,它对数据流进行hash并分配到对应的CPU Core上,发挥多核的性能。不过现在基本都是多队列网卡,不会开启这个机制,因此走不到这里,static_key_false是针对默认为false的static key 的优化判断方式。这段调用的最后,deliver_skb会将接收的数据传入一个IP层的数据结构中,至此完成二层的全部处理。
/**
* netif_receive_skb - process receive buffer from network
* @skb: buffer to process
*
* netif_receive_skb() is the main receive data processing function.
* It always succeeds. The buffer may be dropped during processing
* for congestion control or by the protocol layers.
*
* This function may only be called from softirq context and interrupts
* should be enabled.
*
* Return values (usually ignored):
* NET_RX_SUCCESS: no congestion
* NET_RX_DROP: packet was dropped
*/
int netif_receive_skb(struct sk_buff *skb)
{
int ret;
net_timestamp_check(netdev_tstamp_prequeue, skb);
if (skb_defer_rx_timestamp(skb))
return NET_RX_SUCCESS;
rcu_read_lock();
#ifdef CONFIG_RPS
/* 判断是否启用RPS机制 */
if (static_key_false(&rps_needed)) {
struct rps_dev_flow voidflow, *rflow = &voidflow;
/* 获取对应的CPU Core */
int cpu = get_rps_cpu(skb->dev, skb, &rflow);
if (cpu >= 0) {
ret = enqueue_to_backlog(skb, cpu, &rflow->last_qtail);
rcu_read_unlock();
return ret;
}
}
#endif
ret = __netif_receive_skb(skb);
rcu_read_unlock();
return ret;
}TCP/IP协议栈逐层处理,最终交给用户空间读取
数据包进到IP层之后,经过IP层、TCP层处理(校验、解析上层协议,发送给上层协议),放入socket buffer,在应用程序执行read() 系统调用时,就能从socket buffer中将新数据从内核区拷贝到用户区,完成读取。
这里的socket buffer大小即TCP接收窗口,TCP由于具备流量控制功能,能动态调整接收窗口大小,因此数据传输阶段不会出现由于socket buffer接收队列空间不足而丢包的情况(但UDP及TCP握手阶段仍会有)。涉及TCP/IP协议的部分不是此次丢包问题的研究重点,因此这里不再赘述。
网卡队列
查看网卡型号
# lspci -vvv | grep Eth
01:00.0 Ethernet controller: Intel Corporation Ethernet Controller 10-Gigabit X540-AT2 (rev 03)
Subsystem: Dell Ethernet 10G 4P X540/I350 rNDC
01:00.1 Ethernet controller: Intel Corporation Ethernet Controller 10-Gigabit X540-AT2 (rev 03)
Subsystem: Dell Ethernet 10G 4P X540/I350 rNDC
# lspci -vvv
07:00.0 Ethernet controller: Intel Corporation I350 Gigabit Network Connection (rev 01)
Subsystem: Dell Gigabit 4P X540/I350 rNDC
Control: I/O- Mem+ BusMaster+ SpecCycle- MemWINV- VGASnoop- ParErr- Stepping- SERR- FastB2B- DisINTx+
Status: Cap+ 66MHz- UDF- FastB2B- ParErr- DEVSEL=fast >TAbort- <TAbort- <MAbort- >SERR- <PERR- INTx-
Latency: 0, Cache Line Size: 128 bytes
Interrupt: pin D routed to IRQ 19
Region 0: Memory at 92380000 (32-bit, non-prefetchable) [size=512K]
Region 3: Memory at 92404000 (32-bit, non-prefetchable) [size=16K]
Expansion ROM at 92a00000 [disabled] [size=512K]
Capabilities: [40] Power Management version 3
Flags: PMEClk- DSI+ D1- D2- AuxCurrent=0mA PME(D0+,D1-,D2-,D3hot+,D3cold+)
Status: D0 NoSoftRst+ PME-Enable- DSel=0 DScale=1 PME-
Capabilities: [50] MSI: Enable- Count=1/1 Maskable+ 64bit+
Address: 0000000000000000 Data: 0000
Masking: 00000000 Pending: 00000000
Capabilities: [70] MSI-X: Enable+ Count=10 Masked-
Vector table: BAR=3 offset=00000000
PBA: BAR=3 offset=00002000
可以看出,网卡的中断机制是MSI-X,即网卡的每个队列都可以分配中断(MSI-X支持2048个中断)。
网卡队列
...
#define IXGBE_MAX_MSIX_VECTORS_82599 0x40
...
u16 ixgbe_get_pcie_msix_count_generic(struct ixgbe_hw *hw)
{
u16 msix_count;
u16 max_msix_count;
u16 pcie_offset;
switch (hw->mac.type) {
case ixgbe_mac_82598EB:
pcie_offset = IXGBE_PCIE_MSIX_82598_CAPS;
max_msix_count = IXGBE_MAX_MSIX_VECTORS_82598;
break;
case ixgbe_mac_82599EB:
case ixgbe_mac_X540:
case ixgbe_mac_X550:
case ixgbe_mac_X550EM_x:
case ixgbe_mac_x550em_a:
pcie_offset = IXGBE_PCIE_MSIX_82599_CAPS;
max_msix_count = IXGBE_MAX_MSIX_VECTORS_82599;
break;
default:
return 1;
}
...根据网卡型号确定驱动中定义的网卡队列,可以看到X540网卡驱动中定义最大支持的IRQ Vector为0x40(数值:64)。
static int ixgbe_acquire_msix_vectors(struct ixgbe_adapter *adapter)
{
struct ixgbe_hw *hw = &adapter->hw;
int i, vectors, vector_threshold;
/* We start by asking for one vector per queue pair with XDP queues
* being stacked with TX queues.
*/
vectors = max(adapter->num_rx_queues, adapter->num_tx_queues);
vectors = max(vectors, adapter->num_xdp_queues);
/* It is easy to be greedy for MSI-X vectors. However, it really
* doesn't do much good if we have a lot more vectors than CPUs. We'll
* be somewhat conservative and only ask for (roughly) the same number
* of vectors as there are CPUs.
*/
vectors = min_t(int, vectors, num_online_cpus());通过加载网卡驱动,获取网卡型号和网卡硬件的队列数;但是在初始化misx vector的时候,还会结合系统在线CPU的数量,通过Sum = Min(网卡队列,CPU Core) 来激活相应的网卡队列数量,并申请Sum个中断号。
如果CPU数量小于64,会生成CPU数量的队列,也就是每个CPU会产生一个external IRQ。
我们线上的CPU一般是48个逻辑core,就会生成48个中断号,由于我们是两块网卡做了bond,也就会生成96个中断号。
验证与复现网络丢包
通过霸爷的一篇文章,我们在测试环境做了测试,发现测试环境的中断确实有集中在CPU 0的情况,下面使用systemtap诊断测试环境软中断分布的方法:
global hard, soft, wq
probe irq_handler.entry {
hard[irq, dev_name]++;
}
probe timer.s(1) {
println("==irq number:dev_name")
foreach( [irq, dev_name] in hard- limit 5) {
printf("%d,%s->%d\n", irq, kernel_string(dev_name), hard[irq, dev_name]);
}
println("==softirq cpu:h:vec:action")
foreach( [c,h,vec,action] in soft- limit 5) {
printf("%d:%x:%x:%s->%d\n", c, h, vec, symdata(action), soft[c,h,vec,action]);
}
println("==workqueue wq_thread:work_func")
foreach( [wq_thread,work_func] in wq- limit 5) {
printf("%x:%x->%d\n", wq_thread, work_func, wq[wq_thread, work_func]);
}
println("\n")
delete hard
delete soft
delete wq
}
probe softirq.entry {
soft[cpu(), h,vec,action]++;
}
probe workqueue.execute {
wq[wq_thread, work_func]++
}
probe begin {
println("~")
}下面执行i.stap 的结果:
==irq number:dev_name
87,eth0-0->1693
90,eth0-3->1263
95,eth1-3->746
92,eth1-0->703
89,eth0-2->654
==softirq cpu:h:vec:action
0:ffffffff81a83098:ffffffff81a83080:0xffffffff81461a00->8928
0:ffffffff81a83088:ffffffff81a83080:0xffffffff81084940->626
0:ffffffff81a830c8:ffffffff81a83080:0xffffffff810ecd70->614
16:ffffffff81a83088:ffffffff81a83080:0xffffffff81084940->225
16:ffffffff81a830c8:ffffffff81a83080:0xffffffff810ecd70->224
==workqueue wq_thread:work_func
ffff88083062aae0:ffffffffa01c53d0->10
ffff88083062aae0:ffffffffa01ca8f0->10
ffff88083420a080:ffffffff81142160->2
ffff8808343fe040:ffffffff8127c9d0->2
ffff880834282ae0:ffffffff8133bd20->1下面是action对应的符号信息:
addr2line -e /usr/lib/debug/lib/modules/2.6.32-431.20.3.el6.mt20161028.x86_64/vmlinux ffffffff81461a00
/usr/src/debug/kernel-2.6.32-431.20.3.el6/linux-2.6.32-431.20.3.el6.mt20161028.x86_64/net/core/dev.c:4013打开这个文件,我们发现它是在执行 static void net_rx_action(struct softirq_action *h)这个函数,而这个函数正是前文提到的,NET_RX_SOFTIRQ 对应的软中断处理程序。因此可以确认网卡的软中断在机器上分布非常不均,而且主要集中在CPU 0上。通过/proc/interrupts能确认硬中断集中在CPU 0上,因此软中断也都由CPU 0处理,如何优化网卡的中断成为了我们关注的重点。
优化策略
CPU亲缘性
前文提到,丢包是因为队列中的数据包超过了 netdev_max_backlog 造成了丢弃,因此首先想到是临时调大netdev_max_backlog能否解决燃眉之急,事实证明,对于轻微丢包调大参数可以缓解丢包,但对于大量丢包则几乎不怎么管用,内核处理速度跟不上收包速度的问题还是客观存在,本质还是因为单核处理中断有瓶颈,即使不丢包,服务响应速度也会变慢。因此如果能同时使用多个CPU Core来处理中断,就能显著提高中断处理的效率,并且每个CPU都会实例化一个softnet_data对象,队列数也增加了。
中断亲缘性设置
通过设置中断亲缘性,可以让指定的中断向量号更倾向于发送给指定的CPU Core来处理,俗称“绑核”。命令grep eth /proc/interrupts的第一列可以获取网卡的中断号,如果是多队列网卡,那么就会有多行输出:
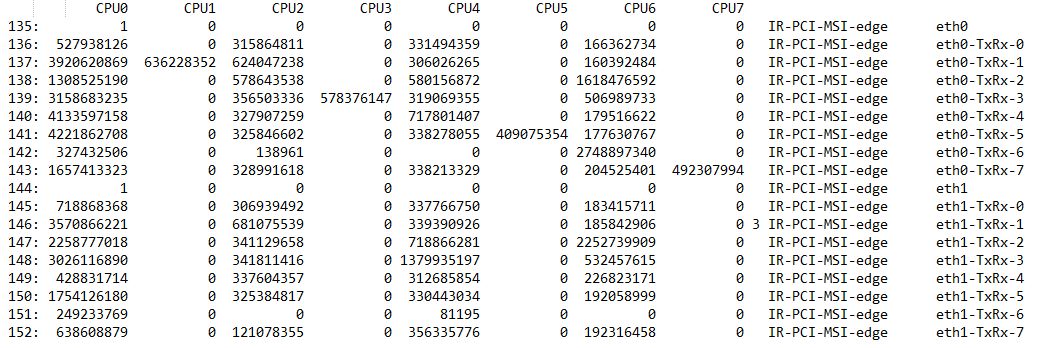
中断的亲缘性设置可以在 cat /proc/irq/${中断号}/smp_affinity 或 cat /proc/irq/${中断号}/smp_affinity_list 中确认,前者是16进制掩码形式,后者是以CPU Core序号形式。例如下图中,将16进制的400转换成2进制后,为 10000000000,“1”在第10位上,表示亲缘性是第10个CPU Core。
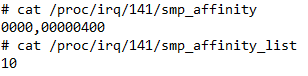
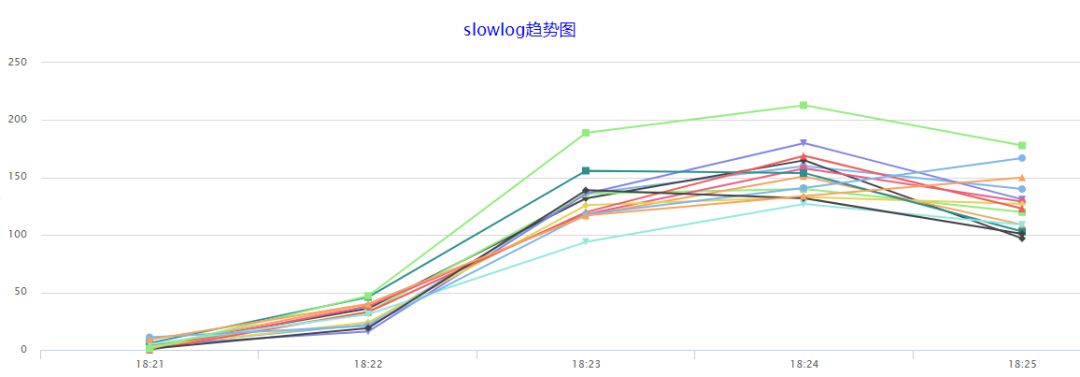
那为什么中断号只设置一个CPU Core呢?而不是为每一个中断号设置多个CPU Core平行处理。我们经过测试,发现当给中断设置了多个CPU Core后,它也仅能由设置的第一个CPU Core来处理,其他的CPU Core并不会参与中断处理,原因猜想是当CPU可以平行收包时,不同的核收取了同一个queue的数据包,但处理速度不一致,导致提交到IP层后的顺序也不一致,这就会产生乱序的问题,由同一个核来处理可以避免了乱序问题。
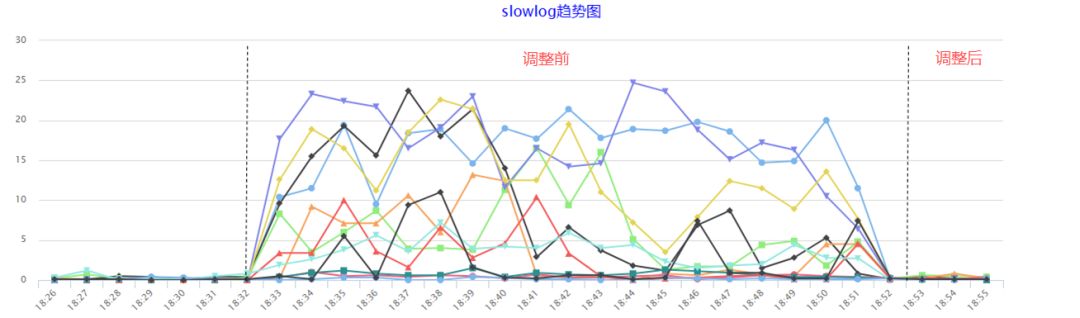
但是,当我们配置了多个Core处理中断后,发现Redis的慢查询数量有明显上升,甚至部分业务也受到了影响,慢查询增多直接导致可用性降低,因此方案仍需进一步优化。
Redis进程亲缘性设置
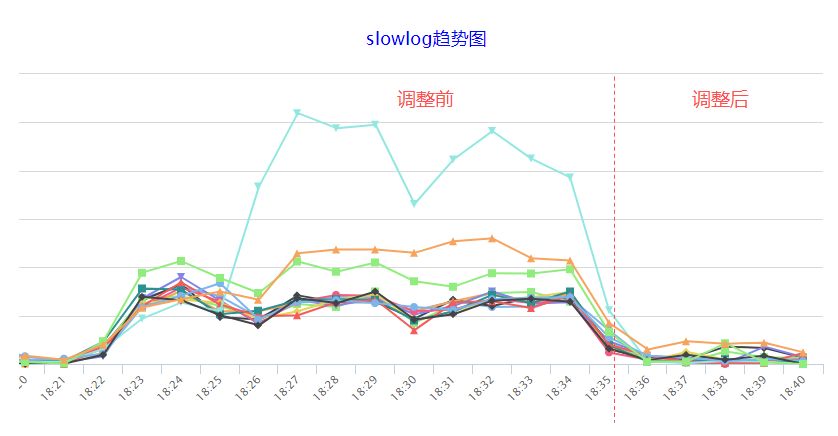
如果某个CPU Core正在处理Redis的调用,执行到一半时产生了中断,那么CPU不得不停止当前的工作转而处理中断请求,中断期间Redis也无法转交给其他core继续运行,必须等处理完中断后才能继续运行。Redis本身定位就是高速缓存,线上的平均端到端响应时间小于1ms,如果频繁被中断,那么响应时间必然受到极大影响。容易想到,由最初的CPU 0单核处理中断,改进到多核处理中断,Redis进程被中断影响的几率增大了,因此我们需要对Redis进程也设置CPU亲缘性,使其与处理中断的Core互相错开,避免受到影响。
使用命令taskset可以为进程设置CPU亲缘性,操作十分简单,一句taskset -cp cpu-list pid即可完成绑定。经过一番压测,我们发现使用8个core处理中断时,流量直至打满双万兆网卡也不会出现丢包,因此决定将中断的亲缘性设置为物理机上前8个core,Redis进程的亲缘性设置为剩下的所有core。调整后,确实有明显的效果,慢查询数量大幅优化,但对比初始情况,仍然还是高了一些些,还有没有优化空间呢?
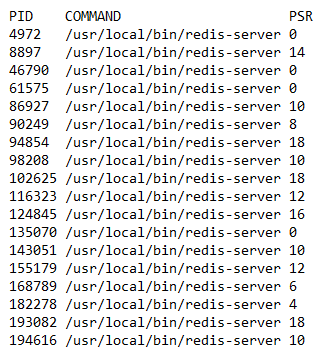
通过观察,我们发现一个有趣的现象,当只有CPU 0处理中断时,Redis进程更倾向于运行在CPU 0,以及CPU 0同一物理CPU下的其他核上。于是有了以下推测:我们设置的中断亲缘性,是直接选取了前8个核心,但这8个core却可能是来自两块物理CPU的,在/proc/cpuinfo中,通过字段processor和physical id 能确认这一点,那么响应慢是否和物理CPU有关呢?物理CPU又和NUMA架构关联,每个物理CPU对应一个NUMA node,那么接下来就要从NUMA角度进行分析。
NUMA
SMP 架构
随着单核CPU的频率在制造工艺上的瓶颈,CPU制造商的发展方向也由纵向变为横向:从CPU频率转为每瓦性能。CPU也就从单核频率时代过渡到多核性能协调。
SMP(对称多处理结构):即CPU共享所有资源,例如总线、内存、IO等。
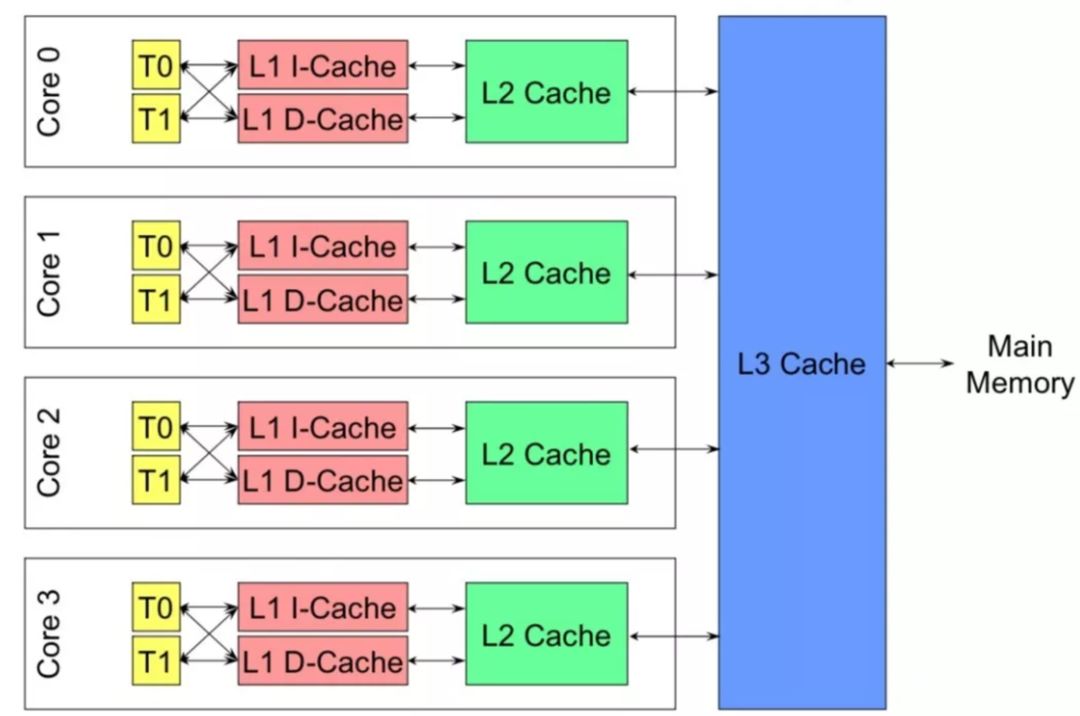
SMP 结构:一个物理CPU可以有多个物理Core,每个Core又可以有多个硬件线程。即:每个HT有一个独立的L1 cache,同一个Core下的HT共享L2 cache,同一个物理CPU下的多个core共享L3 cache。
下图(摘自内核月谈)中,一个x86 CPU有4个物理Core,每个Core有两个HT(Hyper Thread)。
NUMA 架构
在前面的FSB(前端系统总线)结构中,当CPU不断增长的情况下,共享的系统总线就会因为资源竞争(多核争抢总线资源以访问北桥上的内存)而出现扩展和性能问题。
在这样的背景下,基于SMP架构上的优化,设计出了NUMA(Non-Uniform Memory Access)—— 非均匀内存访问。
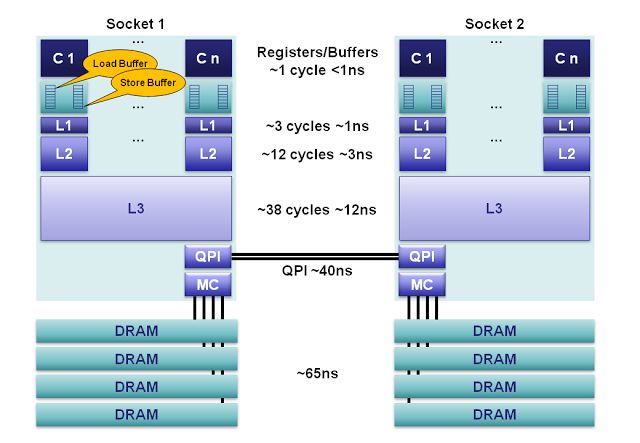
内存控制器芯片被集成到处理器内部,多个处理器通过QPI链路相连,DRAM也就有了远近之分。(如下图所示:摘自CPU Cache)
CPU 多层Cache的性能差异是很巨大的,比如:L1的访问时长1ns,L2的时长3ns…跨node的访问会有几十甚至上百倍的性能损耗。
NUMA 架构下的中断优化
这时我们再回归到中断的问题上,当两个NUMA节点处理中断时,CPU实例化的softnet_data以及驱动分配的sk_buffer都可能是跨node的,数据接收后对上层应用Redis来说,跨node访问的几率也大大提高,并且无法充分利用L2、L3 cache,增加了延时。
同时,由于Linux wake affinity 特性,如果两个进程频繁互动,调度系统会觉得它们很有可能共享同样的数据,把它们放到同一CPU核心或NUMA Node有助于提高缓存和内存的访问性能,所以当一个进程唤醒另一个的时候,被唤醒的进程可能会被放到相同的CPU core或者相同的NUMA节点上。此特性对中断唤醒进程时也起作用,在上一节所述的现象中,所有的网络中断都分配给CPU 0去处理,当中断处理完成时,由于wakeup affinity特性的作用,所唤醒的用户进程也被安排给CPU 0或其所在的numa节点上其他core。而当两个NUMA node处理中断时,这种调度特性有可能导致Redis进程在CPU core之间频繁迁移,造成性能损失。
综合上述,将中断都分配在同一NUMA Node中,中断处理函数和应用程序充分利用同NUMA下的L2、L3缓存、以及同node下的内存,结合调度系统的wake affinity特性,能够更进一步降低延迟。
参考文档
作者简介
骁雄,14年加入美团点评,主要从事MySQL、Redis数据库运维,高可用和相关运维平台建设。
春林,17年加入美团点评,毕业后一直深耕在运维线,从网络工程师到Oracle DBA再到MySQL DBA 多种岗位转变,现在美团点评主要职责Redis运维开发和优化工作。
---------------------- END ----------------------
招聘信息
美团点评DBA团队招聘各类DBA人才,Base北京上海均可。我们致力于为公司提供稳定、可靠、高效的在线存储服务,打造业界领先的数据库团队。
这里有基于Redis Cluster构建的大规模分布式缓存系统Squirrel,也有基于Tair进行大刀阔斧改进的分布式KV存储系统Cellar,还有数千各类架构的MySQL实例,每天提供万亿级的OLTP访问请求。真正的海量、分布式、高并发环境。欢迎各位朋友推荐或自荐至jinlong.cai#dianping.com。
也许你还想看:





