UCL等三强联手提出完全可微自适应神经树:神经网络与决策树完美结合

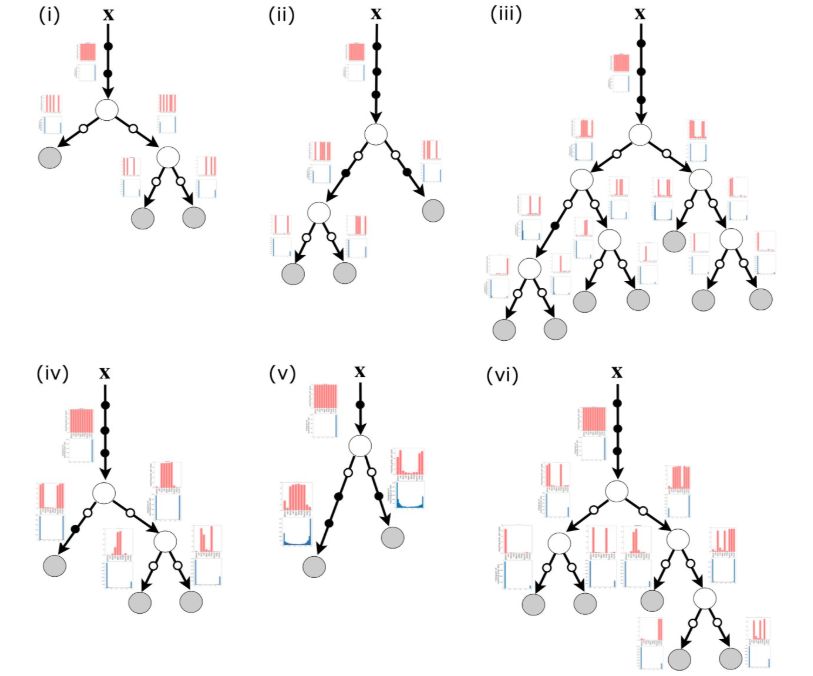
将神经网络和决策树结合在一起的自适应神经树
新智元报道
来源:arXiv
作者:Ryutaro Tanno,Kai Arulkumaran等
作者:三石,闻菲
【新智元导读】UCL、帝国理工和微软的研究人员合作,将神经网络与决策树结合在一起,提出了一种新的自适应神经树模型ANT,打破往局限,可以基于BP算法做训练,在MNIST和CIFAR-10数据集上的准确率高达到99%和90%。

神经网络的成功关键在于其表示学习的能力。但是随着网络深度的增加,模型的容量和复杂度也不断提高,训练和调参耗时耗力。
另一方面,决策树模型通过学习数据的分层结构,可以根据数据集的性质调整模型的复杂度。决策树的可解释性更高,无论是大数据还是小数据表现都很好。
如何借鉴两者的优缺点,设计新的深度学习模型,是目前学术界关心的课题之一。
举例来说,去年南大周志华教授等人提出“深度森林”,最初采用多层级联决策树结构(gcForest),探索深度神经网络以外的深度模型。如今,深度深林系列已经发表了三篇论文,第三篇提出了可做表示学习的多层GBDT森林(mGBDT),在很多神经网络不适合的应用领域中具有巨大的潜力。
日前,UCL、帝国理工和微软的研究人员合作,提出了另一种新的思路,他们将决策树和神经网络结合到一起,生成了一种完全可微分的决策树(由transformer、router和solver组成)。
他们将这种新的模型称为“自适应神经树”(Adaptive Neural Trees,ANT),这种新模型能够根据验证误差,或者加深或者分叉。在推断过程中,整个模型都可以作为一种较慢的分层混合专家系统,也可以是快速的决策树模型。
自适应神经树结合了神经网络和决策树的优点,尤其在处理分层数据结构方面,在CIFAR-10数据集上分类取得了99%的准确率。
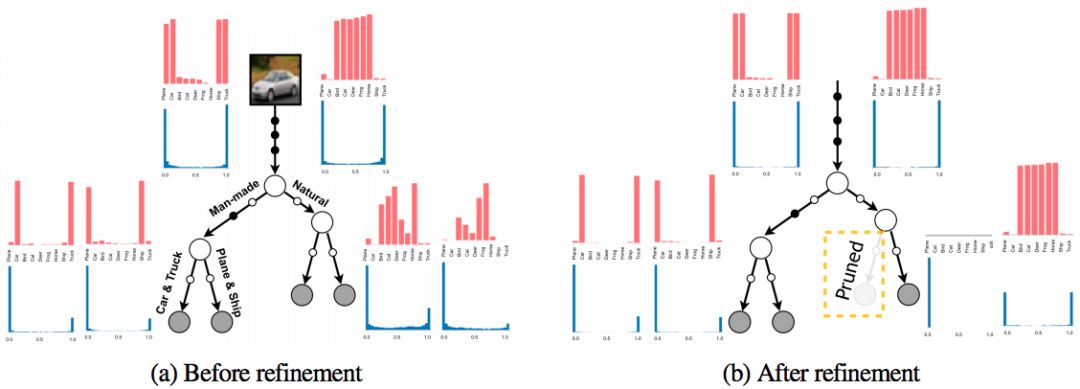
在 refinement 之前(a)和之后(b),ANT各个节点处的类别分布(红色)和路径概率(蓝色)。(a)表明学习模型学会了可解释的层次结构,在同一分支上对语义相似的图像进行分组。(b)表明 refinement 阶段极化路径概率,修剪分支。来源:研究论文
论文共同第一作者、帝国理工学院博士生Kai Arulkumaran表示,更宽泛地看,ANT也属于自适应计算(adaptive computation paradigm)的一种。由于数据的性质是各不相同的,因此我们在处理这些数据时,也要考虑不同的方式。
新智元亦采访了“深度森林”系列研究的参与者之一、南京大学博士生冯霁。冯霁表示,这篇工作这是基于软决策树(可微分决策树)这条路的一个最新探索。具体而言,将神经网络同时嵌入到决策路径和节点中,以提升单颗决策树的能力。由于该模型可微分,整个系统可通过BP算法进行训练。
“ANT的出发点与mGBDT类似,都是期望将神经网络的表示学习和决策树的特点做一个结合,不过,ANT依旧依赖神经网络BP算法进行的实现,”冯霁说:“而深度森林(gcForest/mGBDT)的目的是探索构建多层不可微分系统的能力,换言之,没有放弃树模型非参/不可微这个特性,二者的动机和目标有所不同。”
ANT论文的其中一位作者、微软研究院的Antonio Criminisi,在2011年与人合著了一本专著《决策森林:分类、回归、密度估计、流形学习和半监督学习的统一框架》,可以称得上领域大牛。
神经网络(NN)和决策树(DT)都是强大的机器学习模型,在学术和商业应用上都取得了一定的成功。然而,这两种方法通常具有互斥的优点和局限性。
NN的特点是通过非线性变换的组合来学习数据的层次表示(hierarchical representation),与其他机器学习模型相比,一定程度上减轻了对特征工程的需求。此外,NN还使用随机优化器(如随机梯度下降)进行训练,使训练能够扩展到大型数据集。因此,借助现代硬件,可以在大型数据集中训练多层NN,以前所未有的精确度解决目标检测、语音识别等众多问题。然而,它们的结构通常需要手动设计并且对每个任务和数据集都要进行修整。对于大型模型来说,由于每个样本都会涉及网络中的每一部分,因此推理(reasoning)也是很重要的,例如容量(capacity)的增加会导致计算比例的增加。
DT的特点是通过数据驱动的体系结构,在预先指定的特征上学习层次结构。一颗决策树会学习如何分割输入空间,以便每个子集中的线性模型可以对数据做出解释。与标准的NN相比,DT的结构是基于训练数据进行优化的,因此在数据稀缺的情况下是十分有帮助的。由于每个输入样本只使用树中的一个根到叶(root-to-leaf)的路径,因此DT是享有轻量级推理(lightweight inference)的。然而,在使用DT的成功应用中,往往需要手动设计好的数据特征。由于DT通常使用简单的路径函数,它在表达能力(expressivity)方面是具有局限性的,例如轴对齐(axis-aligned)特征的拆分。用于优化硬分区(hard partitioning)的损失函数是不可微的,这就阻碍了基于梯度下降优化策略的使用,从而导致分割函数变得更加复杂。目前增加容量的技术主要是一些集成方法,例如随机森林(RF)和梯度提升树(GBT)等。
为结合NN和DT的优点,提出一种叫自适应神经树(ANT)的方法,主要包括两个关键创新点:
一种新颖的DT形式:计算路径(computational path)和路由决策(routing decision)由NN来表示;
基于反向传播的训练算法:从简单的模块开始对结构进行扩展。ANT还解决了过去一些方法的局限性,如下图所示:
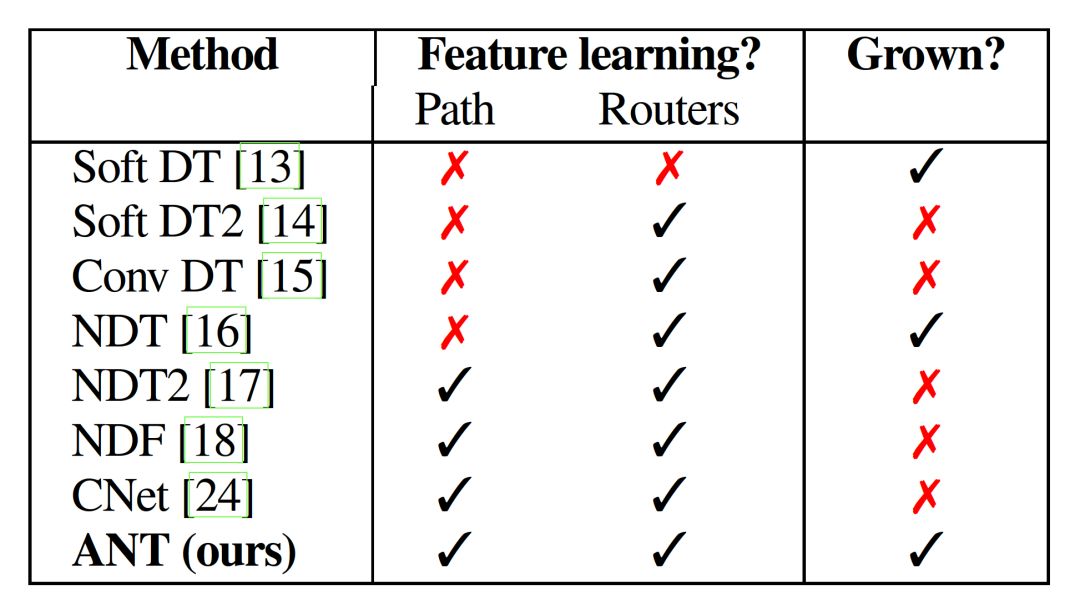
ANT从DT和NN中继承了如下属性:
表示学习 (Representation learning):由于ANT中的每个根到叶(root-to-leaf)路径都是NN,因此可以通过基于梯度的优化来端到端(end-to-end)地学习特征。训练算法也适用于SGD。
结构学习 (Architecture learning):通过逐步增长的ANT,结构可以适应数据的可用性和复杂性。增长过程可以看作是神经结构搜索的一种形式。
轻量级推理 (Lightweight Inference):在推理时,ANT执行条件计算(conditional computation),基于每个样本,在树中选择一个根到叶(root-to-leaf)的路径,且只激活模型的一个子集。
自适应神经树(ANT)定义:用深度卷积表示(representation)来增强DT的一种形式。该方法旨在从一组被标签的样本N(训练数据)(x(1),y(1)),...(x(n),y(n))∈X ×Y 学习条件分p(x|y)。值得注意的是,ANT也可以扩展到其它需要机器学习的任务中。
模型拓展与操作
简而言之,ANT是一个树形结构模型,其特点是输入空间X拥有一组分层分区(hierarchical partition)、一系列非线性转换以及在各个分量区域中有独立的预测模型。更正式地说,ANT可以定义为一对(T,O),其中T表示模型拓扑,O表示操作集。
将T约束为二叉树的实例,并定义为一组有限图(finite graph),其中,每个节点要么是内部节点,要么是叶子节点,并且是一个父节点的子节点(除了无父节点外)。将树的拓扑定义为T:={N,ε},其中N是所有节点的集合,ε是边的集合。没有孩子的节点是叶子节Nleaf,其它所有节点都是内部节Nint。每个内部节点都有两个孩子节点,表示leftj和rightj。与标准树不同,ε包含一条能够将输入数据X与根节点连接起来的边。如下图所示:
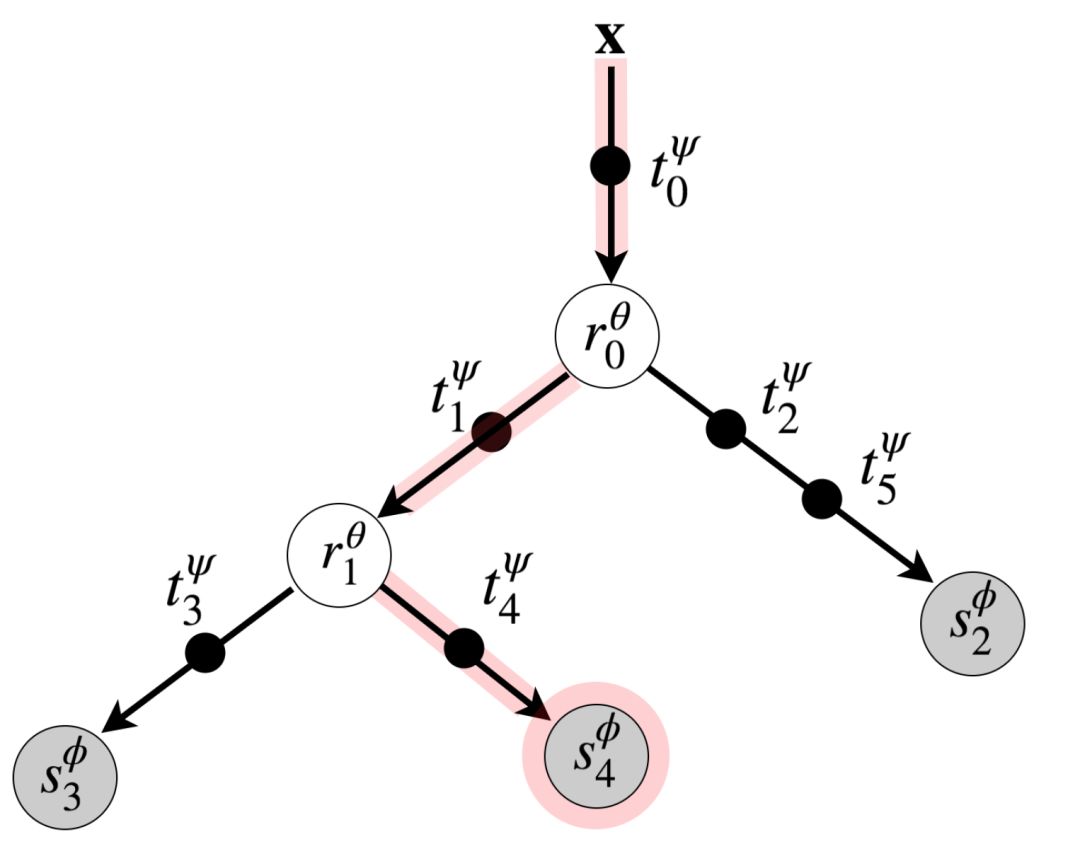
一个ANT是基于下面三个可微操作的基本模块构建的:
路由器(Router),R:每个内部节点j∈Nint都有一个路由模块,将来自传入边(incomming edge)的样本发送到左子节点或右子节点。
转换器(transformer),T:树中的每条边e∈ε都有一个或一组多转换模块( multiple transformer module)。每个转换teψ∈T都是一个非线性函数,将前一个模块中的样本进行转换并传递给下一个模块。
求解器(Solver),S:每个求解器模块分配一个叶子节点,该求解器模块对变换的输入数据进行操作并输出对条件分布p(y|x)的估计。
概率模型和推理
ANT对条件分布p(y|x)进行建模并作为层次混合专家网络(HME),每个HME被定义为一个NN并对应于树中特定的根到叶(root-to-leaf)路径。假设我们有L个叶子节点,则完整的预测分布为:
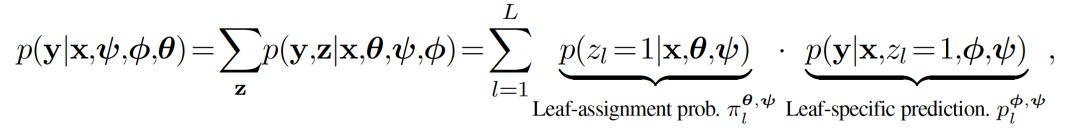
其中,
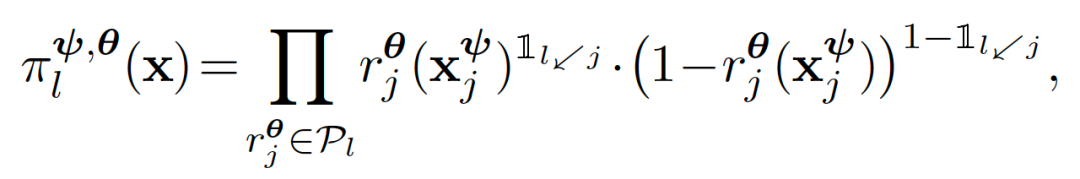

实验结果:
其中,列“Error (Full)” 和 “Error (Path)”表示基于全分布和单路径推断(single-pathinference)的预测分类错误。列“Params(Full)”和“Params(Path)”分别表示模型中的参数总数和单路径推断的参数平均值。“Ensemble Size”表示集成的规模。“-”表示空值,“+”表示与ANT在相同的实验设备进行训练的方法, “*”表示参数是使用预先训练的CNN初始化的。
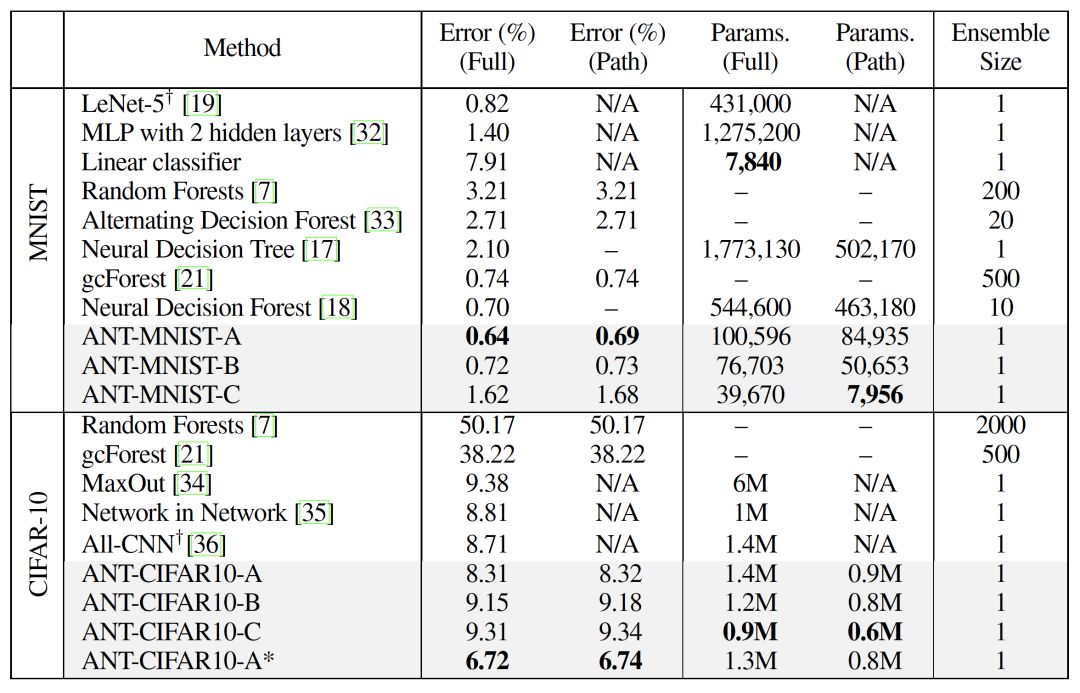
不同模型在MNIST和CIFAR-10上性能的比较

摘要
深度神经网络和决策树很大程度上是相互独立的。通常,前者是用预先指定的体系结构来进行表示学习(representation learning),而后者的特点是通过数据驱动的体系结构,在预先指定的特征上学习层次结构。通过自适应神经树(Adaptive Neural Trees,ANT),一种将表示学习嵌入到决策树的边、路径函数以及叶节点的模型,以及基于反向传播的训练算法(可自适应地从类似卷积层这样的原始模块对结构进行扩展)将两者进行结合。在MNIST和CIFAR-10数据集上的准确率分别达到了99%和90%。ANT的优势在于(i)可通过条件计算(conditional computation)进行更快的推断;(ii)可通过分层聚类(hierarchical clustering)提高可解释性;(iii)有一个可以适应训练数据集规模和复杂性的机制。
原文献地址如下:
https://arxiv.org/pdf/1807.06699.pdf
新智元AI WORLD 2018大会【早鸟票】开售!
新智元将于9月20日在北京国家会议中心举办AI WORLD 2018 大会,邀请迈克思·泰格马克、周志华、陶大程、陈怡然等AI领袖一起关注机器智能与人类命运。
大会官网:
http://www.aiworld2018.com/
即日起到8月19日,新智元限量发售若干早鸟票,点击阅读原文购票,与全球AI领袖近距离交流,见证全球人工智能产业跨越发展。

活动行购票链接:
http://www.huodongxing.com/event/6449053775000
活动行购票二维码:



