案例分享 | TensorFlow XLA 工作原理简介

腾讯机智机器学习平台是腾讯内部专注机器学习的基础服务平台,其核心服务已成功应用于腾讯多个垂直业务中。机智团队在 TensorFlow 内核开发领域积累了丰富经验。本文将通过一个例子简单介绍 XLA 的工作原理。
XLA 是 TensorFlow 计算图的编译器,只需添加少量代码,即可明显加速 TensorFlow ML 模型。下图是谷歌官方提供的 XLA 性能表现。

JIT-Just In Time Compilation
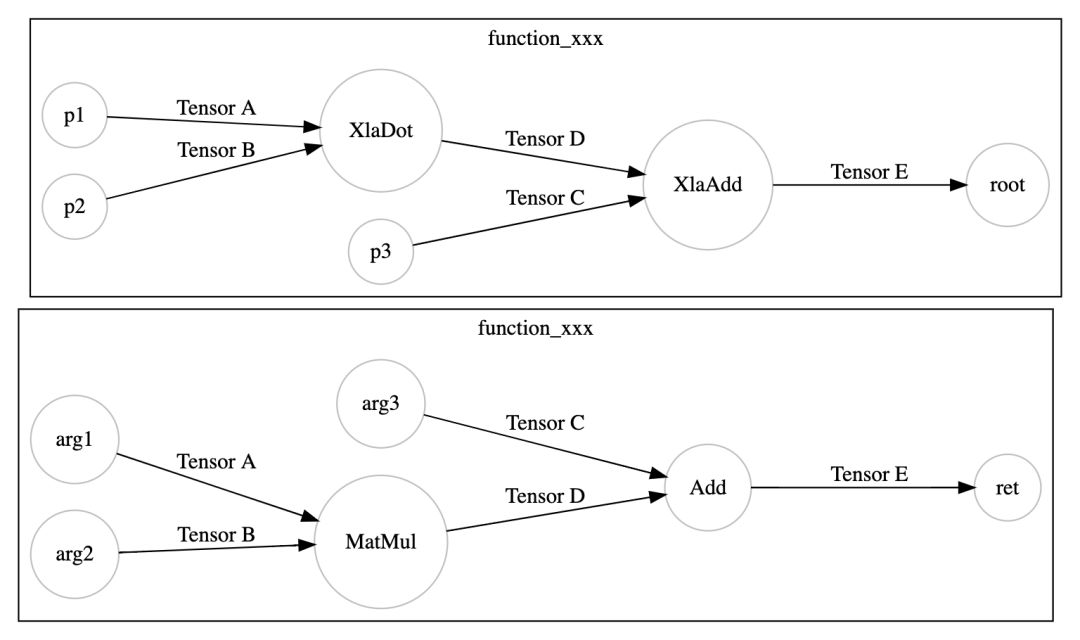
我们先来看 XLA 如何作用于 TensorFlow 的计算图,下面是一张简单的 TensorFlow 计算图。

XLA 通过一个 TensorFlow 的图优化 Pass (MarkForCompilation),在 TensorFlow 计算图中找到适合被 JIT 编译的区域。这里我们假设 XLA 仅支持 MatMul 和 Add。

TensorFlow XLA 把这个区域定义为一个 Cluster,作为一个独立的 JIT 编译单元,在 TensorFlow 计算图中通过 Node Attribute 标示。

然后另一个 TensorFlow 的图优化 Pass (EncapsulateSubgraphs),把 cluster 转化成 TensorFlow 的一个 Function 子图。在原图上用一个 Caller 节点表示这个 Function 在原图的位置。

最后调用 TensorFlow 的图优化 Pass (BuildXlaOps),把 Function 节点转化成特殊的 Xla 节点。

在 TensorFlow 运行时,运行到 XlaCompile 时,编译 Xla cluster 子图,然后把编译完的 Executable 可执行文件通过 XlaExecutableClosure 传给 XlaRun 运行。
TF2XLA
TensorFlow 运行到 XlaCompile 节点时,为了编译这个 Function,通过把 TensorFlow 子图所有的节点翻译成 XLA HLO Instruction 虚拟指令的形式表达,整个子图也由此转化成 XLA HLO Computation。

XLA-HLO
XLA 在 HLO 的图表达上进行图优化。聚合可在同一个 GPU Kernel 中执行的 HLO 指令。

HLO 图优化前

HLO 图优化后
代码生成
首先根据虚拟指令分配 GPU Stream 和显存。
然后 IrEmitter 把 HLO Graph 转化成由编译器的中间表达 LLVM IR 表示的 GPU Kernel。LLVM IR 如下所示:
; ModuleID = 'cluster_36__XlaCompiledKernel_true__XlaNumConstantArgs_1__XlaNumResourceArgs_0_.36'
source_filename = "cluster_36__XlaCompiledKernel_true__XlaNumConstantArgs_1__XlaNumResourceArgs_0_.36"
target datalayout = "e-i64:64-i128:128-v16:16-v32:32-n16:32:64"
target triple = "nvptx64-nvidia-cuda"
@0 = private unnamed_addr constant [4 x i8] zeroinitializer
@1 = private unnamed_addr constant [4 x i8] zeroinitializer
@2 = private unnamed_addr constant [4 x i8] zeroinitializer
@3 = private unnamed_addr constant [4 x i8] zeroinitializer
@4 = private unnamed_addr constant [4 x i8] zeroinitializer
@5 = private unnamed_addr constant [4 x i8] zeroinitializer
@6 = private unnamed_addr constant [4 x i8] zeroinitializer
define void @fusion_1(i8* align 16 dereferenceable(3564544) %alloc2, i8* align 64 dereferenceable(3776) %temp_buf) {
entry:
%output.invar_address = alloca i64
%output_y.invar_address = alloca i64
%arg0.1.raw = getelementptr inbounds i8, i8* %alloc2, i64 0
%arg0.1.typed = bitcast i8* %arg0.1.raw to [944 x [944 x float]]*
%fusion.1.raw = getelementptr inbounds i8, i8* %temp_buf, i64 0
%fusion.1.typed = bitcast i8* %fusion.1.raw to [944 x float]*
%0 = call i32 @llvm.nvvm.read.ptx.sreg.tid.x(), !range !4
%thread.id.x = sext i32 %0 to i64
%thread.x = urem i64 %thread.id.x, 944
%thread.y = udiv i64 %thread.id.x, 944
%1 = alloca float
%partial_reduction_result.0 = alloca float
%2 = load float, float* bitcast ([4 x i8]* @0 to float*)
%3 = getelementptr inbounds float, float* %partial_reduction_result.0, i32 0
store float %2, float* %3
%current_output_linear_index_address = alloca i64
%4 = alloca i1
store i1 false, i1* %4
%5 = call i32 @llvm.nvvm.read.ptx.sreg.ctaid.x(), !range !5
%block.id.x = sext i32 %5 to i64
%6 = udiv i64 %block.id.x, 1
%7 = urem i64 %6, 1
%8 = udiv i64 %block.id.x, 1
%9 = urem i64 %8, 8
%10 = udiv i64 %block.id.x, 8
%block_origin.0 = mul i64 %10, 1
%block_origin.1 = mul i64 %9, 1
...
由 LLVM 生成 nvPTX(Nvidia 定义的虚拟底层指令表达形式)表达,进而由 NVCC 生成 CuBin 可执行代码。PTX 如下所示:
//
// Generated by LLVM NVPTX Back-End
//
.version 6.0
.target sm_70
.address_size 64
// .globl fusion_1
.visible .entry fusion_1(
.param .u64 fusion_1_param_0,
.param .u64 fusion_1_param_1
)
.reqntid 944, 1, 1
{
.reg .pred %p<9>;
.reg .f32 %f<25>;
.reg .b32 %r<31>;
.reg .b64 %rd<61>;
ld.param.u64 %rd27, [fusion_1_param_0];
ld.param.u64 %rd28, [fusion_1_param_1];
cvta.to.global.u64 %rd29, %rd28;
cvta.to.global.u64 %rd1, %rd27;
cvta.global.u64 %rd2, %rd29;
mov.u32 %r3, %tid.x;
cvt.u64.u32 %rd3, %r3;
mov.u32 %r1, %ctaid.x;
setp.eq.s32 %p1, %r1, 7;
@%p1 bra LBB0_4;
bra.uni LBB0_1;
LBB0_4:
selp.b64 %rd4, 48, 128, %p1;
cvt.u32.u64 %r26, %rd3;
shl.b64 %rd47, %rd3, 2;
add.s64 %rd48, %rd47, %rd1;
add.s64 %rd59, %rd48, 3383296;
or.b32 %r27, %r26, 845824;
mul.wide.u32 %rd49, %r27, 582368447;
shr.u64 %rd50, %rd49, 39;
cvt.u32.u64 %r28, %rd50;
mul.lo.s32 %r29, %r28, 945;
sub.s32 %r2, %r27, %r29;
mov.f32 %f23, 0f00000000;
...
代码执行
当 TensorFlow 运行到 XlaRun 时运行由 XlaCompile 编译得到的 GPU 可执行代码(Cubin 或 PTX)。

想加入案例分享?点击 “阅读原文”,填写相关信息,我们会尽快与你联系。
更多相关案例:



