CVPR 2020 | 旷视研究院16篇(含6篇Oral)收录论文亮点集锦

IEEE国际计算机视觉与模式识别会议 CVPR 2020 (IEEE Conference on Computer Vision and Pattern Recognition) 大会官方论文结果公布,旷视研究院 16 篇论文被收录(其中含 6篇 Oral 论文),研究领域涵盖物体检测与行人再识别(尤其是遮挡场景),人脸识别,文字检测与识别,实时视频感知与推理,小样本学习,迁移学习,3D感知,GAN与图像生成,计算机图形学,语义分割,细粒度图像,对抗样本攻击等众多领域,取得多项领先的技术研究成果,这与已开放/开源的旷视AI生产力平台Brain++密不可分。本文把 16 篇论文汇在一起,逐篇做了亮点集锦式的抢先解读。
IEEE国际计算机视觉与模式识别会议 CVPR 2020 (IEEE Conference on Computer Vision and Pattern Recognition) 大会官方论文结果公布,旷视研究院 16 篇论文被收录(其中含 6篇 Oral 论文),研究领域涵盖物体检测与行人再识别(尤其是遮挡场景),人脸识别,文字检测与识别,实时视频感知与推理,小样本学习,迁移学习,3D感知,GAN与图像生成,计算机图形学,语义分割,细粒度图像,对抗样本攻击等众多领域,取得多项领先的技术研究成果,这与已开放/开源的旷视AI生产力平台Brain++密不可分。本文把 16 篇论文汇在一起,逐篇做了亮点集锦式的抢先解读。
01
论文名称:DPGN: Distribution Propagation Graph Network for Few-shot Learning
论文链接:https://arxiv.org/abs/2003.14247
关键词:小样本学习,图网络
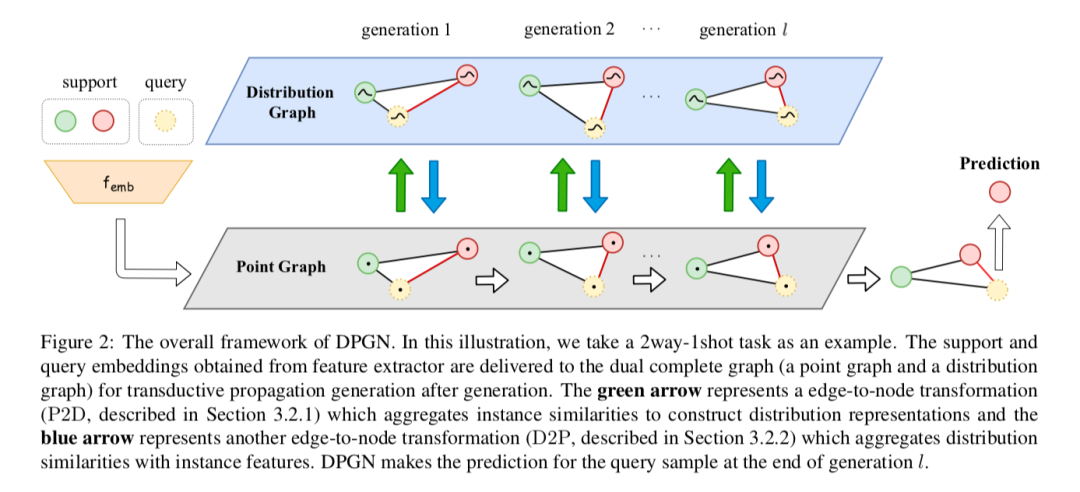
现有大部分基于图网络的元学习方法通常是在建模样本层面之间的单点关系,本文做进一步扩展,以1-vs-N的方式,显式地建模从一个样本到所有其他样本在分布层面的关系,提出一个针对小样本学习的全新方法—— DPGN(Distribution Propagation Graph Network),可在每个小样本学习任务中同时传递单点和分布层面的关系。
为把这两种关系在所有样本中结合,本文提出双层完全图结构,它包含一个点图和一个分布图,其中每个节点代表一个样本。借助这种双层图结构,DPGN经过若干层更新迭代,可使信息在标签样本和无标签样本中传递。实验表明,在小样本学习的常用公开测试集上,DPGN的性能大幅超越当前的最佳结果,在监督学习场景下超出5%~12%,在半监督学习场景下超出7%~13%。
02
论文名称:High-Order Information Matters: Learning Relation and Topology for Occluded Person Re-Identification
论文链接:https://arxiv.org/abs/2003.08177
论文解读:CVPR 2020 | 旷视研究院提出新方法,优化解决遮挡行人重识别问题
关键词:遮挡,行人再识别
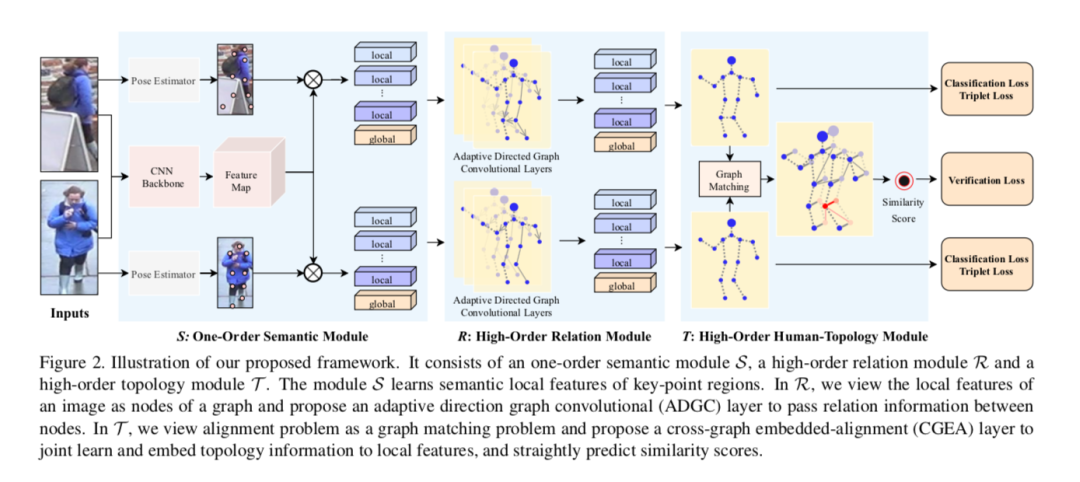
遮挡行人重识别(Occluded ReID)旨在匹配一个被遮挡的行人图像与其跨摄像头图像。本文提出一个新框架,通过学习高阶关系和拓扑信息,提高特征的判别力和对齐的鲁棒性。首先,使用一个卷积神经网络学习输入图像的特征图,并使用关键点模型提取局部语义特征(比如头、身体、腿)。其次,把一张图像的许多局部特征视作一个图网络的多个节点,并提出一个方向自适应的图卷积层(ADGC)传递节点之间的信息;ADGC可通过动态学习边的连接和方向,自动抑制无意义的局部特征的信息传递。
对齐是遮挡行人重识别中的重要一步,当对齐两张图像的两组局部特征时,本文将其视为一个图匹配,提出跨图嵌入对齐层(CGEA)同时学习和嵌入拓扑信息,直接预测相似度得分。CGEA不仅充分利用图匹配所习得的对齐信息,还通过一个鲁棒的软对齐代替敏感的硬对齐。最后,本文在遮挡、半身行人数据集上均取得SOTA性能,验证了该方法的有效性。
03
Oral论文:Learning Dynamic Routing for Semantic Segmentation
论文链接:https://arxiv.org/abs/2003.10401
论文代码:https://github.com/yanwei-li/DynamicRouting
论文解读:CVPR2020 Oral | 旷视研究院提出针对语义分割的动态路径选择网络
关键词:语义分割,动态路径
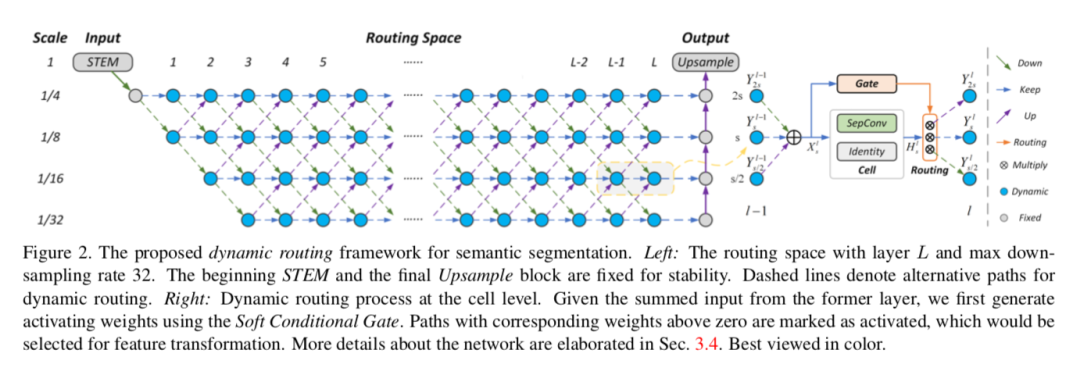
近期,大量人工设计和基于搜索的神经网络已应用于语义分割,但是先前方法(比如FCN、U-Net和DeepLab系列)均在预定义的静态结构中处理不同尺寸分布的输入。本文针对语义分割提出一个全新的概念,称之为动态路径选择(Dynamic Routing),以缓解语义表示的尺寸变化问题。本文提出的方法根据输入图像动态地生成前向推断路径,以匹配每张图像的尺寸分布;并为此提出一种可微分门控函数,称之为软条件门控,以动态选择尺寸变换路径。
此外,根据所给出的计算资源预算的不同,网络在保持较佳性能的前提下可动态调整路径以满足相应要求。本文进一步拓宽网络层面的路径选择空间,支持多路径传播和跳跃连接,这带来了可观的网络容量。为证明这种动态结构的优越性,本文与若干个静态网络做对比,它们可被建模为路径空间中的特例。Cityscapes和PASCAL VOC 2012数据集上的大量实验也证明所提出动态框架的有效性。本文已入选CVPR2020 Oral论文。
04
论文名称:State-Aware Tracker for Real-Time Video Object Segmentation
论文链接:https://arxiv.org/abs/2003.00482
论文代码:https://github.com/MegviiDetection/video_analyst
论文解读:CVPR 2020 | 旷视研究院提出SAT:优化解决半监督视频物体分割问题
关键词:实时,视频感知,物体分割
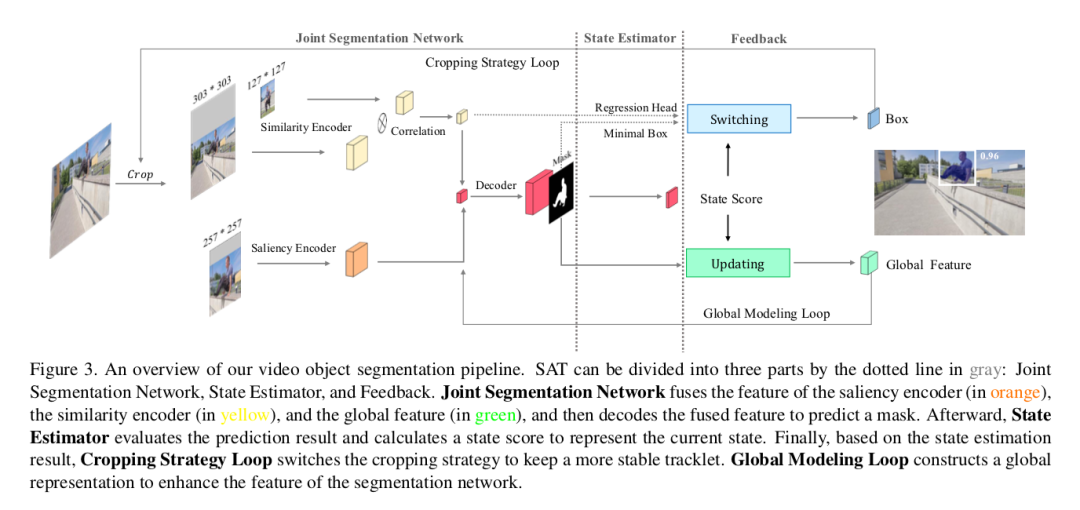
本文探索半监督条件下如何高效利用视频时空特性解决视频物体分割(VOS)的问题,并提出一个全新的Pipeline,称之为状态感知跟踪器(State-Aware Tracker/SAT),它可在高精确的结果下同时实现实时分割。速度方面,SAT利用时空平滑一致性,把目标作为一个tracklet时空整体对待。精度方面,SAT通过两个反馈回路实现分割状态的感知与自适应,一个反馈通过状态估计得到稳定的tracklet序列,另一个通过状态更新全局特征构建更鲁棒的全局表达。SAT在DAVIS2017验证集上取得优异表现,39 FPS J&F平均值达到0.723,效率和精度之间实现极佳的均衡。
05
论文名称:Exploring Categorical Regularization for Domain Adaptive Object Detection
论文链接:https://arxiv.org/abs/2003.09152
论文代码:https://github.com/Megvii-Nanjing/CR-DA-DET
关键词:物体检测,迁移学习,域适应
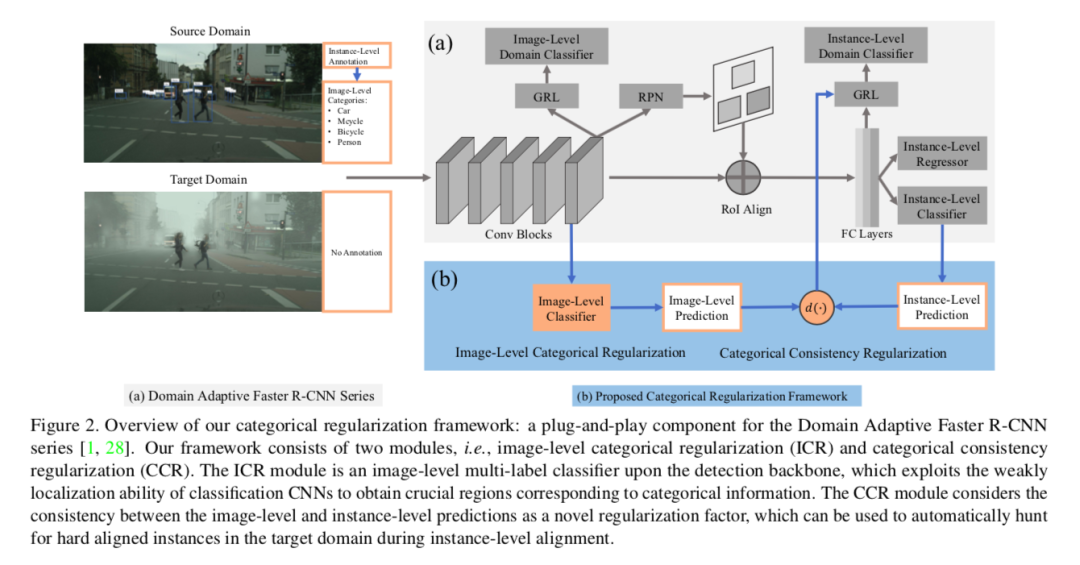
本文研究的是物体检测的域自适应(Domain Adaptive)问题,其主要挑战来自源域和目标域之间的巨大差异。先前工作主要是明确对齐了图像层面和实例层面的迁移,以最终最小化域差异,但是依然忽略了跨域匹配关键的图像区域和重要的实例,以至于严重影响了域迁移的缓解。本文提出一个简单且有效的类正则化框架以缓解这一问题,它可以作为一个即插即用的组件应用于一系列域自适应Faster R-CNN方法上,这些方法对处理域自适应检测非常重要。
具体而言,通过整合检测backbone上的一个图像层面的多标签分类器,本文可以通过分类方式的弱定位能力,获得对应于类信息的稀疏且关键的图像区域。同时,在实例层面,本文把图像预测和实例预测之间的类一致性作为一个正则化因子,以自动搜索目标域的硬对齐实例。大量不同域迁移方案的实验表明,相较原始的域自适应Faster R-CNN检测器,本文方法取得显著的性能提升。此外,定性的可视化和分析表明,本文方法可应用于针对域适应的关键区域/实例。
06
Oral论文:BBN: Bilateral-Branch Network with Cumulative Learning for Long-Tailed Visual Recognition
论文链接:https://arxiv.org/abs/1912.02413
论文代码:https://github.com/Megvii-Nanjing/BBN
论文解读:CVPR2020 Oral | 旷视研究院提出双边分支网络BBN:攻坚长尾分布的现实世界任务
关键词:深度视觉识别,长尾数据,分布式学习
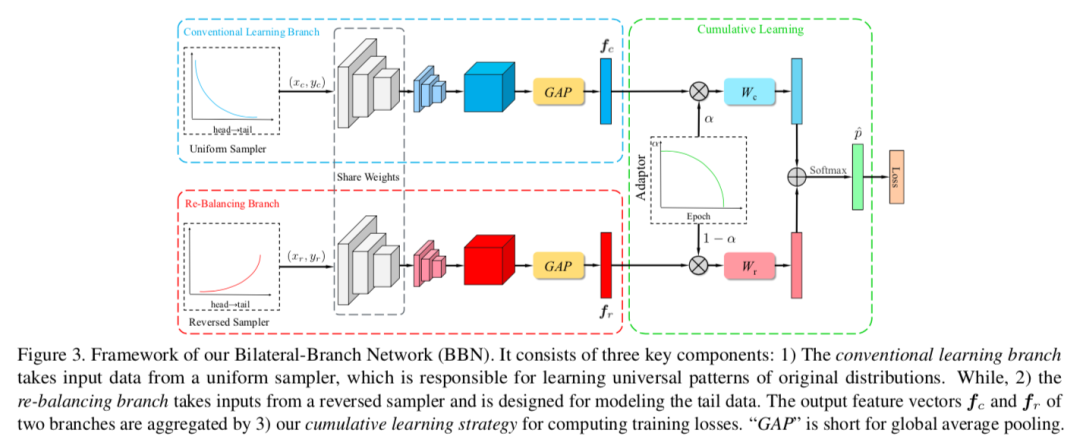
自然视觉识别任务的数据分布呈现长尾模式,即大部分数据属于少量类别,而大部分类别又只有很少的样本。先前的类别再平衡策略(比如再加权、再采样)可显著缓解长尾任务的极端不平衡问题。但在本文中,首先发现这些再平衡方法可实现满意的识别准度,因为这些方法可显著提升深度网络分类器的学习能力;同时又发现,这些方法会在一定程度上出人意料地损害习得的深度特征的表示能力。
本文为此提出一种统一的双边分支网络(BBN),可同时顾及表征学习和分类器学习,其中每个分支各自独立执行任务。尤其值得一提,BBN还进一步配备了一种全新的累积学习策略:首先学习通用模式,然后再逐渐关注尾部数据。本文在4个基准数据集(包括iNaturalist)上进行了广泛实验,结果表明BBN显著优于当前最佳方法。此外,验证实验还表明了上述发现的正确性,而且BBN可以有效解决长尾问题。本文方法获得iNaturalist 2019大规模物种分类竞赛冠军。本文已入选CVPR2020 Oral论文。
07
论文名称:Data Uncertainty Learning in Face Recognition
论文链接:https://arxiv.org/abs/2003.11339
关键词:人脸识别,不确定性估计
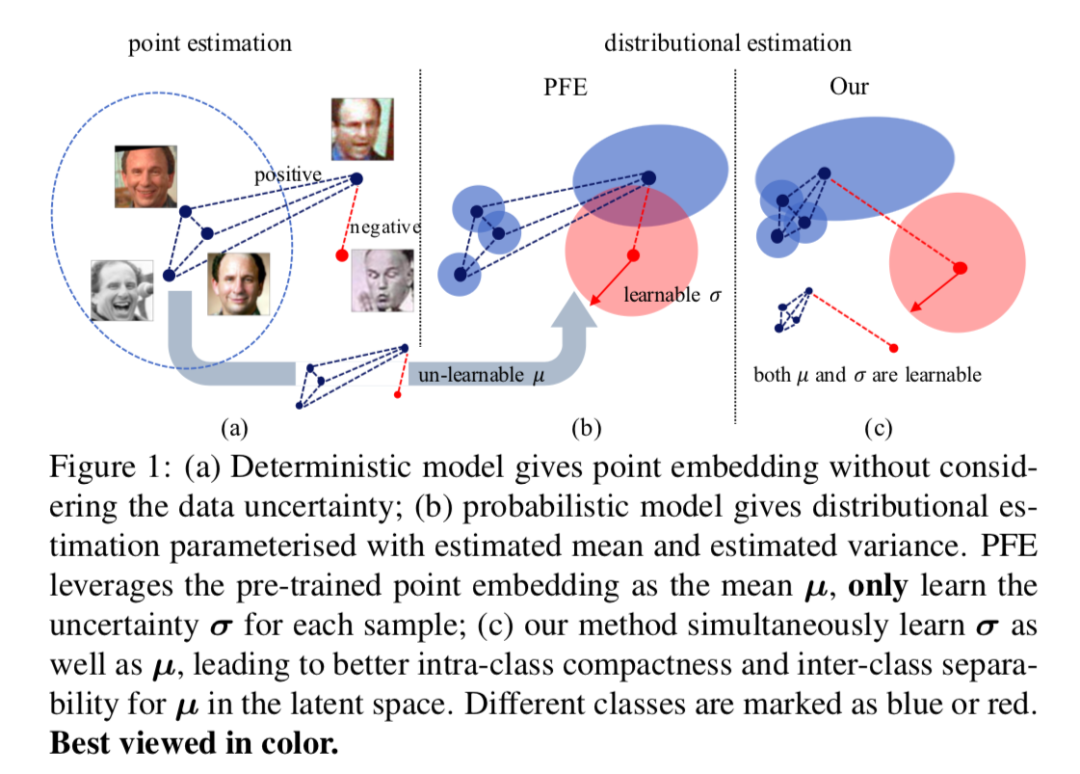
本文提出把数据不确定性估计理论应用于人脸识别领域的Data Uncertainty Learning(DUL)算法。DUL算法的两种训练模式可与各种主流人脸识别方法的损失函数有效结合使用,进一步提升模型在低质量人脸验证和人脸检索任务中的表现。其次,DUL算法对训练集中的噪声数据具有一定的鲁棒性,可有效缓解脏样本对模型训练产生的不利影响;最后,DUL算法针对每张图像所预测的方差,与该张图像的质量呈明显正相关,未来有利于无监督学习范式下的视频帧质量推图,人脸高风险验证预警等具体应用方向。
传统的人脸识别算法利用Point Embedding表示人脸特征,DUL提出利用Probabilistic Embedding代替Point Embedding。DUL利用高斯概率分布建模人脸特征,同时预测均值特征和方差特征,提出了基于分类和基于回归的两种训练模式。DUL算法所估计的不确定度(Variance)可有助于原始特征的学习。实验证明,DUL算法可极大提高低质量图像1v1情形下的TPR@FPR 指标。
08
论文名称:PVN3D: A Deep Point-wise 3D Keypoints Voting Network for 6DoF Pose Estimation
论文链接:https://arxiv.org/abs/1911.04231
论文代码:https://github.com/ethnhe/PVN3D.git
论文解读:CVPR 2020 | 旷视研究院提出PVN3D:基于3D关键点投票网络的单目6DoF位姿估计算法
关键词:3D感知,3D关键点,6D位姿估计
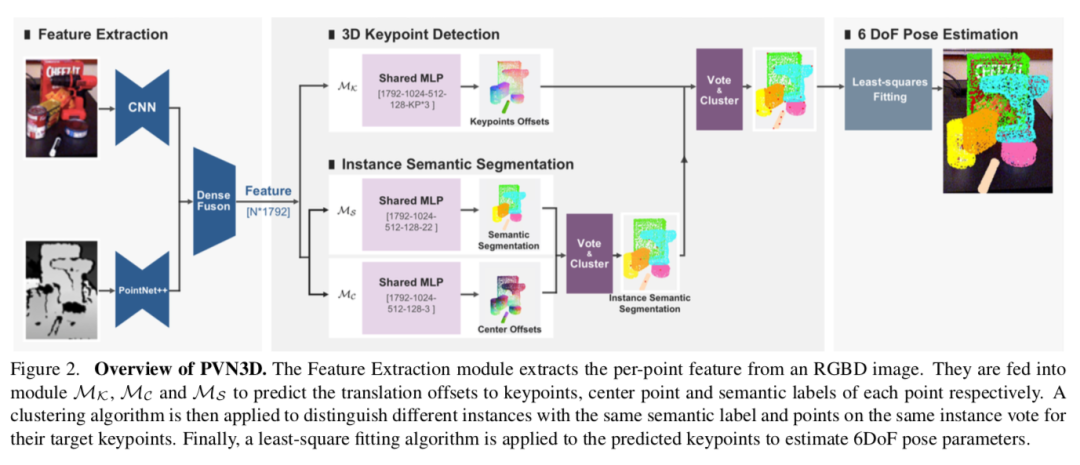
本文提出一种全新的基于单张RGBD图像的物体6D位姿估计算法。不同于现有的直接回归位姿参数的方法,本文开创性提出用3D关键点解决单目6D位姿估计问题。具体而言,本文首先提出一个深度霍夫投票网络,以检测目标物体的3D关键点,接着用最小二乘法拟合物体的6D位姿参数。
关键点的想法借鉴了2D关键点在RGB图像位姿估计问题的成功案例,而本文3D关键点方法可更充分利用深度图像中刚性物体的几何约束信息,从而更精准地预测物体的6D位姿;并且这种范式更易于的深度神经网络的学习和优化。大量分析实验证明了基于3D关键点检测的算法在物体6D位姿估计问题上的有效性,并在两个公开数据集大幅超越现有算法。本文相信基于3D关键点的物体位姿估计算法是一个极具潜力的研究方向。
09
Oral论文:Circle Loss: a Unified Perspective of Pair Similarity Optimization
论文链接:https://arxiv.org/abs/2002.10857
论文解读:CVPR2020 Oral | 旷视研究院提出Circle Loss,革新深度特征学习范式
关键词:人脸识别,行人再识别, 深度特征学习,细粒度图像检索
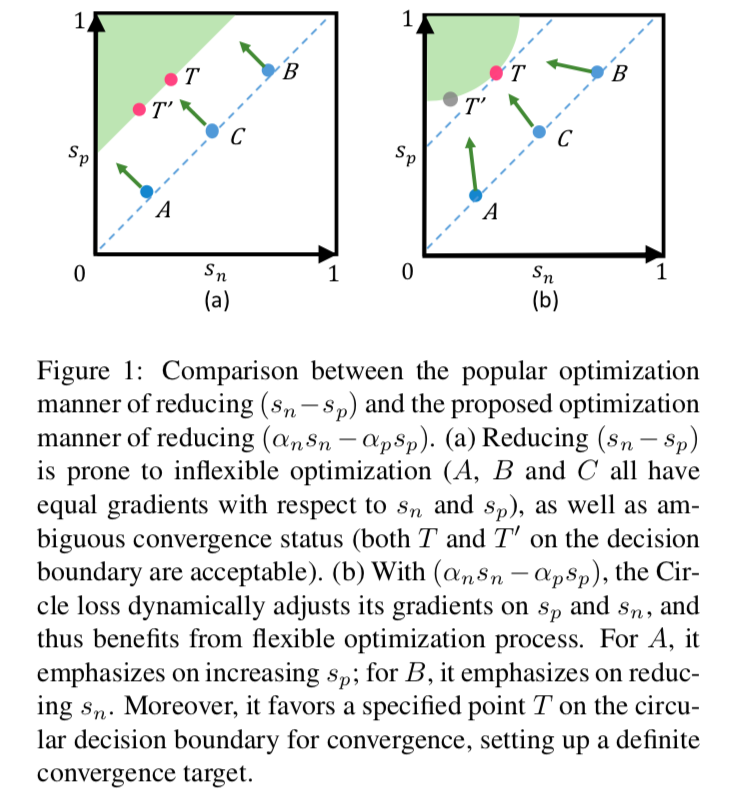
本文提出用于深度特征学习的Circle Loss,从相似性对优化角度正式统一了两种基本学习范式(分类学习和样本对学习)下的损失函数。通过进一步泛化,Circle Loss获得了更灵活的优化途径及更明确的收敛目标,从而提高所学特征的鉴别能力;它使用同一个公式,在两种基本学习范式,三项特征学习任务(人脸识别,行人再识别,细粒度图像检索),十个数据集上取得了极具竞争力的表现。Circle Loss 非常简单,而它对深度特征学习的意义却非常本质,表现为以下三个方面:1)统一的(广义)损失函数,2)灵活的优化方式,3)明确的收敛状态。本文已入选CVPR2020 Oral论文。
10
论文名称:SQE: a Self Quality Evaluation Metric for Parameters Optimization in Multi-Object Tracking
关键词:多目标跟踪,自评测,高斯混合模型
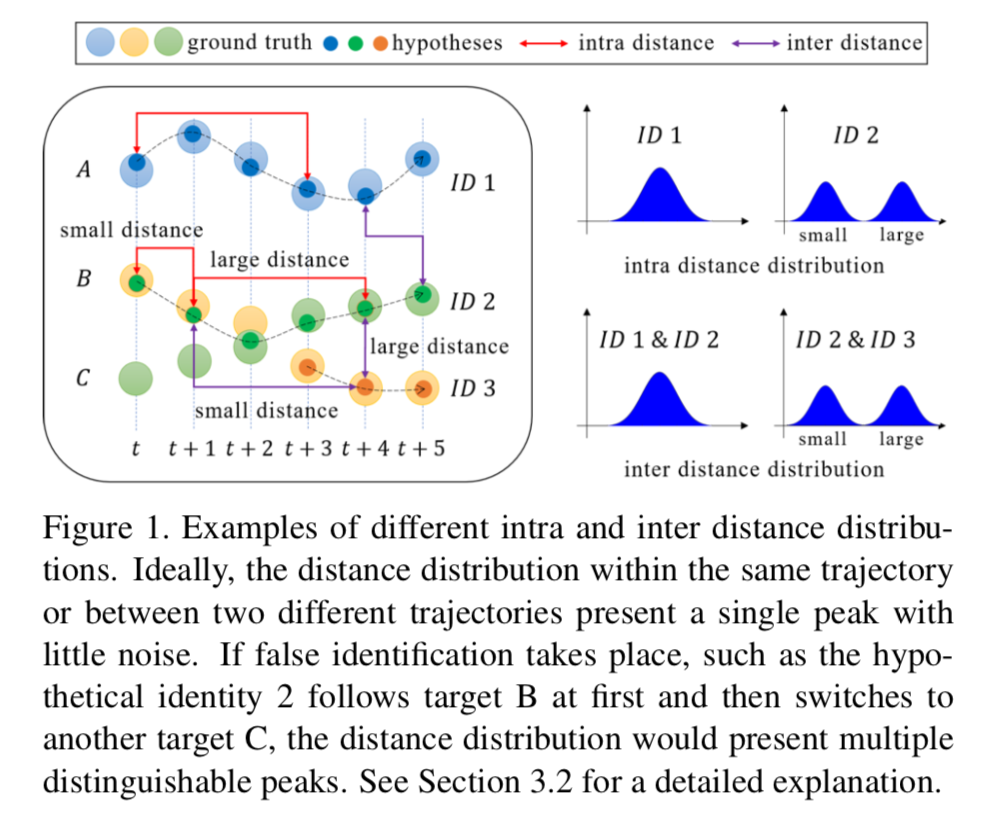
多目标跟踪旨在同时跟踪一段视频中的多个目标,主要应用场景为城市安全和自动驾驶等。由于任务本身的复杂性,该技术当前的评估指标呈多样化,但无一例外需要ground truth作为参考,如果缺少标注的测试环境和实际场景,则无法进一步优化参数。为此,本文首次研究了在没有ground truth的情况下如何自优化跟踪算法的参数,并提出一种新颖的自我质量评估指标SQE,它反映了假设轨迹的内部特征,可以不依赖于ground truth测量跟踪性能。
本文证明具有不同质量的轨迹在特征距离分布上表现出不同的单峰或多峰形态,并受此启发设计了一种简单而有效的方法,即用两类高斯混合模型评估轨迹的质量。MOT16数据集上的实验证明本文方法与现有指标存在正相关关系,并可有效进行参数自优化,以提升跟踪性能。本文认为,这一结论和方法对于实际中的多目标跟踪研究具有指导意义。
11
Oral论文:Detection in Crowded Scenes: One Proposal, Multiple Predictions
论文链接:https://arxiv.org/abs/2003.09163
关键词:物体检测,遮挡
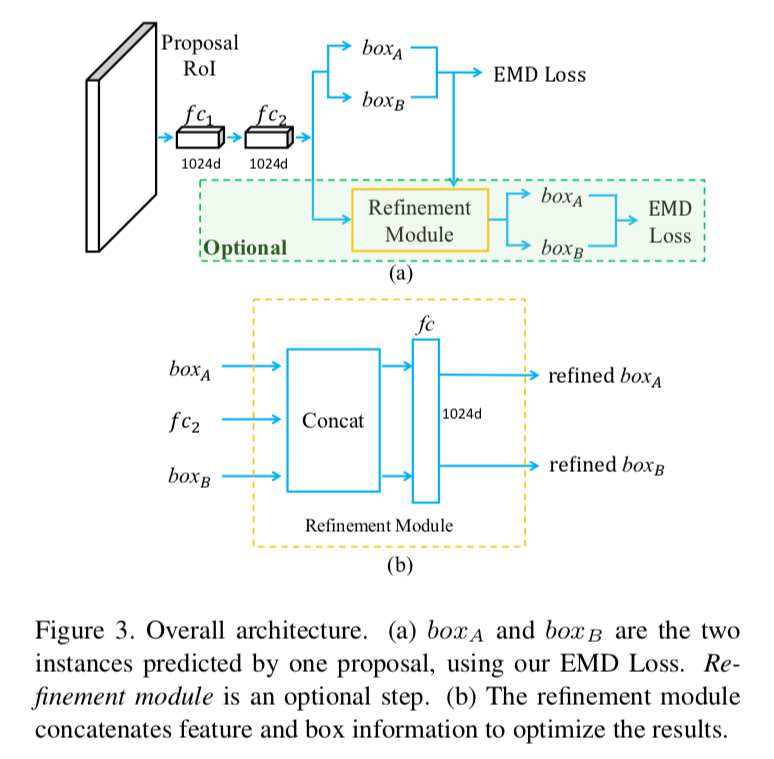
本文提出一种简单而有效的基于候选框的物体检测方法,尤其适用于密集物体检测。相较先前一个候选框预测一个结果,本文方法一个候选框可预测多个结果。设计损失函数时,鉴于同一候选框的预测无关于输出顺序,因此网络需要保证排列不变性,本文设计了EMD Loss以保证网络的排列不变性。后处理阶段类似于NMS:如果两个预测框来自同一候选框,则预测框皆保留;如果两个预测框重叠高于一定阈值,则移除置信度较低的预测框。本文使用mAP、mMR、mJI作为评价指标,并在CrowdHuman数据集上相较于基准方法分别涨点4.9%、1.5%、2.5;同时在Citypersons和稀疏数据集COCO上,本文方法均有1%的性能提升。本文已入选CVPR2020 Oral论文。
12
Oral论文:Attentive Normalization for Conditional Image Generation
论文链接:https://arxiv.org/abs/2004.03828
关键词:GAN,图像生成
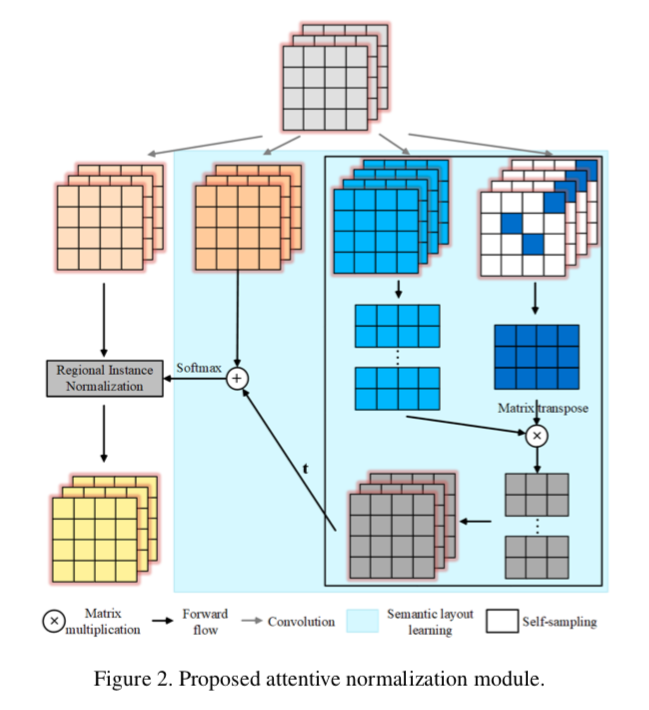
传统基于卷积的生成对抗网络通过层次性的局部操作合成图像,即使用马尔可夫链建模长程依赖关系。本文认为这种方式不足以用于生成具有复杂结构的图像类别。本文基于实例归一化进行扩展,通过注意力归一化(Attentive Normalization)描述长程依赖。
具体而言,根据输入特征图的内部语义相似度把其软划分为若干区域,并分别归一化不同区域。该操作增强了具有语义对应关系的遥远区域之间的一致性。相较自注意力生成对抗网络(Self-Attention GAN),本文的注意力归一化无需测量所有位置的相关性,从而可直接应用于大尺度特征图而没有太大计算负担。本文根据语义标签的条件图像生成和图像修复的大量实验,证明本文提出的模块在客观和视觉评估方面的有效性。本文已入选CVPR2020 Oral论文。
13
论文名称:Learning Human-Object Interaction Detection using Interaction Points
论文链接:https://arxiv.org/abs/2003.14023
关键词:视觉推理,场景解析,人-物交互检测
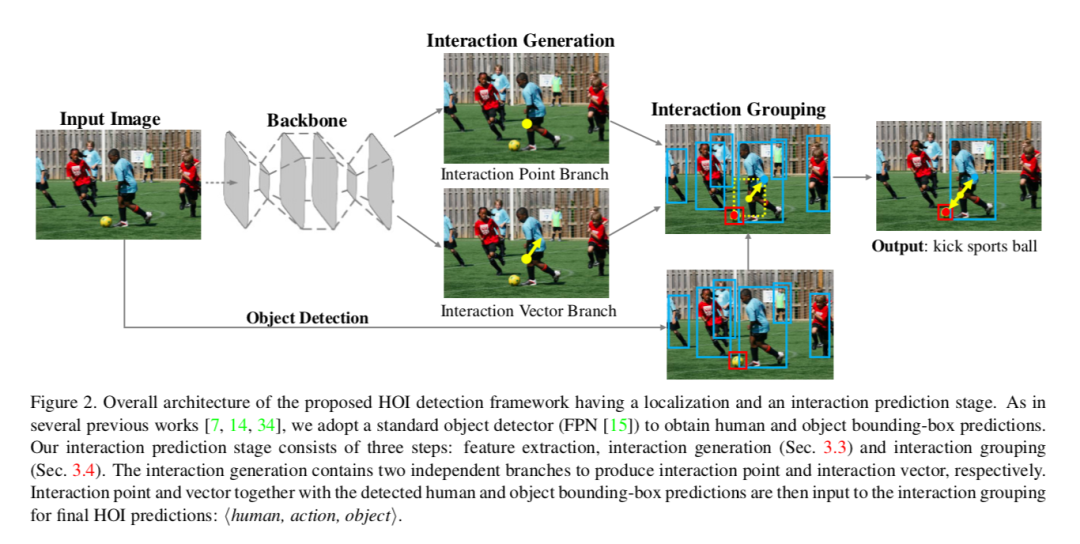
理解人-物交互关系是视觉分类的基础问题,也是深入场景理解的重要一步。人-物交互检测需要定位场景之中的人和物体,并检测人-物之间复杂的交互关系。大多数现有方法以实例为中心,人-物的交互关系仅依靠人和物体的外观特征和粗糙的空间关系进行推理。
本文认为这样不够充分,无法应对复杂的人-物交互检测,并提出一种新型人-物交互检测算法,可直接把人-物交互关系检测为一系列的交互点,进一步预测朝向人和物体中心的交互向量;接着,这些交互点可以配对组合人与物体的检测结果,以生成最终的交互预测。据知,本文首次提出了把人-物交互检测拆分为关键点检测和组合问题,该方法在两大流行数据集V-COCO和HICO-DET做了全面实验,均取得先进的性能。
14
论文名称:UnrealText: Towards Stronger Scene Text Detector By Synthesizing Images from 3D Virtual World
论文链接:https://arxiv.org/abs/2003.10608
论文代码:https://jyouhou.github.io/UnrealText/
关键词:文字图像合成,文字检测识别,3D引擎,计算机图形学

对于自然场景之下的文字检测/识别模型的训练来讲,合成数据是一个关键工具。一方面,相较于真实图像,合成的字词图像是成功训练场景文字识别器的一个的替代品;另一方面,场景文字检测器依然严重依赖于大量手工标注、成本高昂的真实图像。
本文引入一种高效的图像合成方法——UnrealText,它可以通过3D图形引擎,渲染出逼真的图像。3D合成引擎把场景和文字作为一个整体进行渲染,以实现逼真的外观,并且借助精确的场景信息(比如,法向量甚至是物体网格)实现更优的文字区域候选。实验结果证明本文方法在文字检测和识别方面的有效性。本文也提供了多语言版本,以供未来对多语言场景文字检测和识别进行研究。
15
论文名称:On Vocabulary Reliance in Scene Text Recognition
关键词:文字识别,词表依赖性
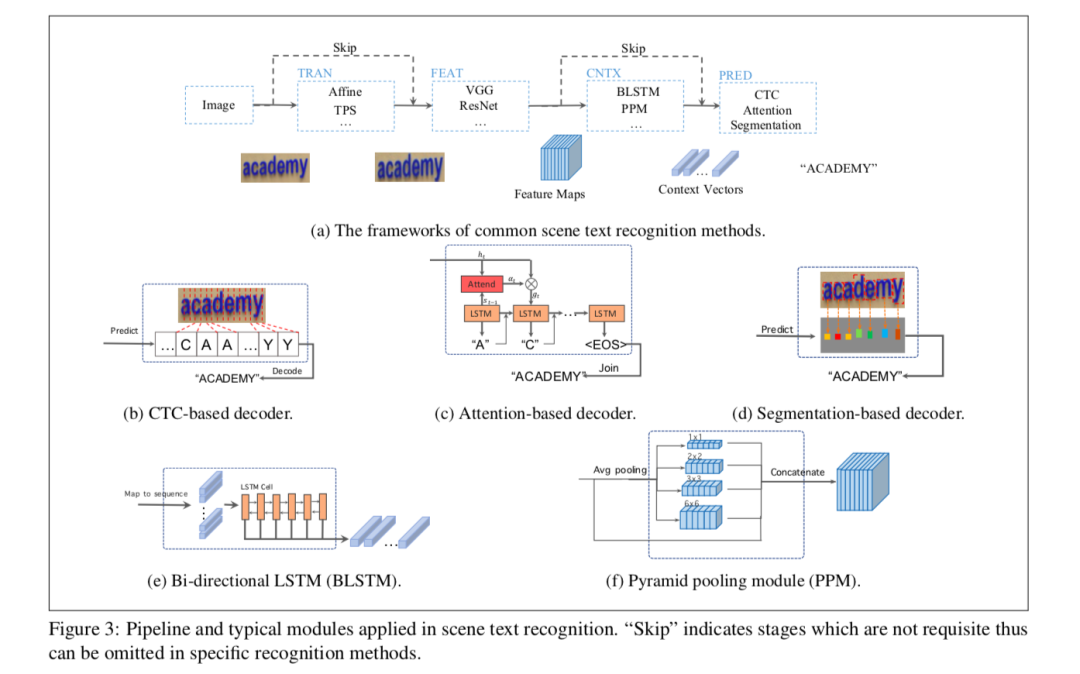
追求公开基准上的高性能是场景文字识别研究的驱动力。虽然这一研究已取得可观进展,但是,一项严格的调查揭示出一个震惊的事实:当前方法对于图像上在词汇之内的字词表现良好,但是对于词汇之外的字词泛化较差。本文把这一现象称之为“词汇依赖”,并建立一个分析框架,以深入研究场景文字识别的“词汇依赖”问题,重要发现如下:
词汇依赖普遍存在,即所有现有的算法或多或少都有这一特征;
基于注意力的解码器在泛化至词汇之外的字词时表现较差,基于分割的解码器在利用可见特征方面表现良好;
语境建模与预测层高度耦合。
这些发现带来了新见解,有利于场景文字识别的进一步研究;本文还给出一个简单而有效的互学习策略,允许上述两种模型协同学习。这一纠正方法缓解了词汇依赖的问题,提升了场景文字识别的整体性能。
16
Oral论文:DaST: Data-free Substitute Training for Adversarial Attacks
论文链接:https://arxiv.org/abs/2003.12703
论文代码:https://github.com/zhoumingyi/Adversarial-Imitation-attacks
关键词:GAN,对抗样本攻击
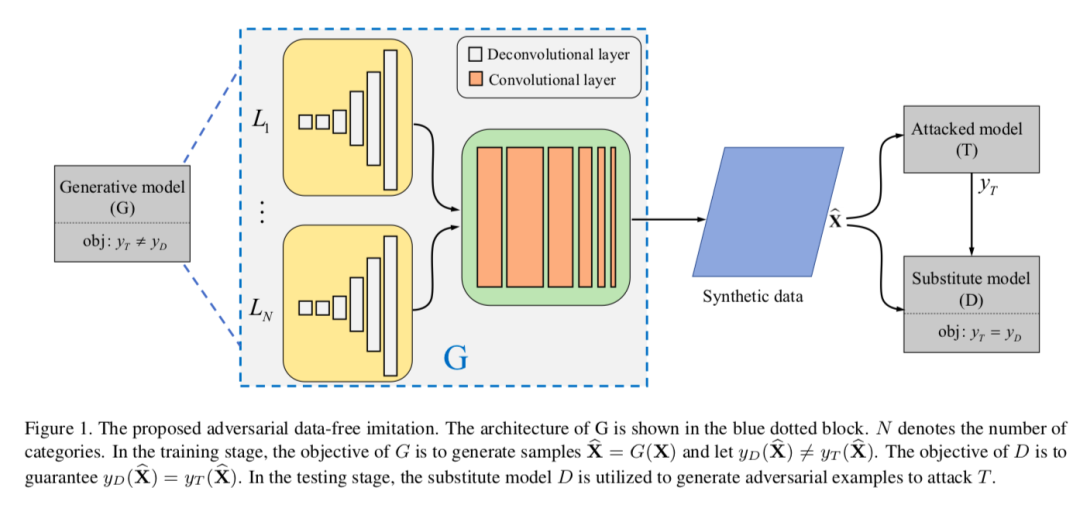
机器学习模型存在对抗性样本攻击的可能性。黑盒攻击模式下,当前的替身攻击(Substitute Attacks)需要使用预训练模型生成对抗性样本,再通过样本迁移性攻击目标模型。但是实际任务中,获得这样的预训练模型很困难。本文提出一种替身模型训练方法——DaST,无需任何真实数据即可获得对抗性黑盒攻击的替身模型。
DaST利用专门设计的生成对抗网络(GAN)训练替身模型,并且针对生成模型设计多分支架构和标签控制损失,以处理GAN生成数据分布不匀的问题。然后,使用GAN生成器生成的样本训练分类器(即替身模型),样本的标签为目标模型的输出。
实验表明,相较基准替身模型,DaST生产的替身模型可实现具有竞争力的性能。此外,为评估所该方法的实用性,本文在Microsoft Azure平台上攻击了在线机器学习模型,在线模型错误地分类了本文方法生成的98.35%的对抗性样本。据知,这是首无需任何真实数据即可生成替身模型并用来产生对抗攻击的工作。本文已入选CVPR2020 Oral论文。
线上交流群

关注 ↑ 旷视研究院小助手加入线上交流群
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。





