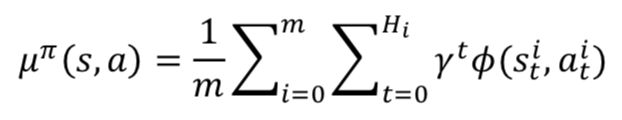用户模拟器基础
近几年来,强化学习在任务导向型对话系统中得到了广泛的应用,对话系统通常被统计建模成为一个马尔科夫决策过程(Markov Decision Process)模型,通过随机优化的方法来学习对话策略。
任务导向型对话系统用于帮助用户完成某个任务如查电影、找餐馆等,它一般由四个模块组成:自然语言理解模块(Natural Language Understanding, NLU)、对话状态跟踪模块(Dialog State Tracking, DST)、对话策略模块(Dialog Policy, DP)和自然语言生成模块(Natural language Generation, NLG),其中 DST 和 DP 合称为对话管理模块。
在和用户的每轮交互过程中,对话系统利用 NLU 将用户的语句解析成为机器可理解的语义标签,并通过 DST 维护一个内部的对话状态作为整个对话历史的紧凑表示,根据此状态使用 DP 选择合适的对话动作,最后通过 NLG 将对话动作转成自然语言回复。对话系统通过和用户进行交互得到的对话数据和使用得分则可用于进行模型的强化学习训练。
然而在实际中,和真实用户的交互成本昂贵,数据回流周期慢,不足以支持模型的快速迭代,因此研究者们通常会构建一个用户模拟器(User Simulator, US)作为对话系统的交互环境来进行闭环训练。有了用户模拟器产生任意多的数据,对话系统可以对状态空间和动作空间进行充分地探索以寻找最优策略。
一个效果良好的用户模拟器,我们期望它具备以下 3 个特征:
-
有一个总体的对话目标,能够生成上下文连贯的用户动作;
-
有足够的泛化能力,在语料中未出现的对话情形里也能生成合理的行为;
-
为了实现以上目标,学术界做了大量的研究工作,从最基础的 bi-gram 模型 [4],到经典实用的 Agenda-based的方法 [2],再到最近基于深度学习的用户模型 [9, 10],用户模拟器的效果得到了显著提升,也为对话模型的训练提供了有效的方法。
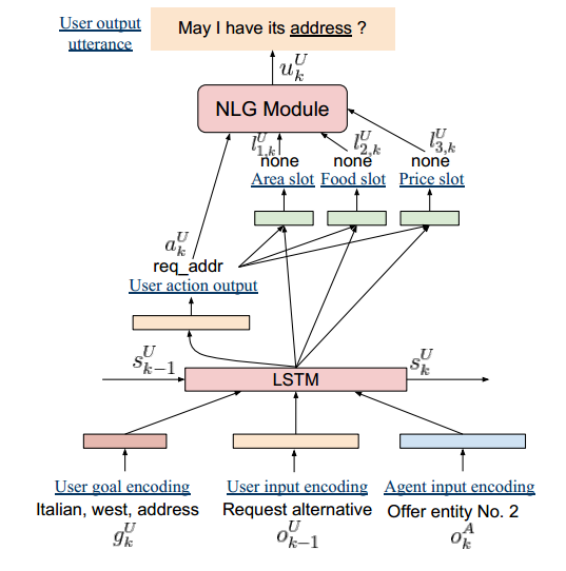
图 1 是一个比较典型的用户模拟器 [1],对话开始时用户模拟器基于 User Goal(用户目标)发出一个话术:“Are there any action movies to see this weekend?”(这个周末有什么动作片可以看的吗?),这句话进到对话系统的自然语言理解模块和对话管理模块后,生成一句系统动作:“request_location”(询问地点)。
简便起见,这里省略掉系统的 NLG 模块,系统回复直接送到用户模拟器的用户模型(User Model),通过用户状态更新和行为策略选择,生成用户对话行为:“inform(location=San Francisco)”(告知地点为旧金山),接下来经过 Error Model(可选)和 NLG 模块,生成对应的自然语言,比如:“San Francisco, please.”(帮我订旧金山的)。以此往复,用户模拟器和对话系统持续多轮交互,直到对话结束。
▲ 图1. 用户模拟器(蓝色部分)和对话系统(红色部分)
从上面的过程我们可以看到,典型的用户模拟器和对话系统的结构比较相似,包含以下 4 个基本组成部分:
1. 用户目标(User Goal):用户模拟的第一步就是生成一个用户对话的目标,对话系统对此是不可知的,但它需要通过多轮对话交互来帮助用户完成该目标。一般来说,用户目标的定义和两种槽位相关: 可告知槽(informable slots)和可问询槽(requestable slots),前者形如“槽=值”是用户用于查询的约束条件,后者则是用户希望向系统问询的属性。
例如:用户目标是 “inform(type=movie, genre=action, location=San Francisco, date=this weekend),request(price)”表达的是用户的目标是想要找一部本周在 San Francisco 上映的动作片,找到电影后再进一步问询电影票的价格属性。有了明确的对用户目标的建模,我们就可以保证用户的回复具有一定的任务导向,而不是闲聊。
2. 用户模型(User Model):用户模型对应着对话系统的对话管理模块,它的任务是根据对话历史生成当前的用户动作。用户动作是预先定义好的语义标签,例如“inform, request, greet, bye”等等。用户动作的选择应当合理且多样,能够模拟出真实用户的行为。用户模型是用户模拟器的核心组成部分,在接下来的章节里我们将会详细介绍各种具体模型和方法。
3. 误差模型(Error Model):它接在 User Model 下游,负责模拟噪声,对用户行为进行扰动以模拟真实交互环境下不确定性。简单的方式有:随机用不正确的意图替换正确的意图、随机替换为不正确的槽位、随机替换为不正确的槽值等;复杂的方式有模拟基于 ASR 或 NLU 混淆的错误。
4. 自然语言生成(NLG):如果用户模拟器需要输出自然语言回复,就需要 NLG 模型将用户动作转换成自然语言表述。例如用户动作标签“inform(type=movie, genre=action, date=this weekend)” 进行 NLG 模块后生成自然语句“Are there any action movies to see this weekend?”。
用户模拟器的实现方法
我们将用户模拟器的实现方法大致分成两类:基于规则的方法和基于模型学习的方法。我们将介绍这些方法中各自具有代表性的论文。
基于规则的方法需要专家手动构建,它的优点是可以冷启动,用户行为完全可控;缺点是代价大,覆盖度不够,在对话行为灵活性和多样性上比较不足,适用于话术简单清晰的填槽式对话任务。
基于规则的方法中使用最为广泛的是基于议程(Agenda-based)的方法 [2, 3],该方法对用户状态表示、状态转移、Agenda 更新、Goal 更新进行了精细建模,逻辑清晰,可落地性强,业界很多工作 [1, 15] 都基于该方法进行扩展和优化。
基于议程的方法通过一个栈的结构把对话的议程定下来,对话的过程就变成进栈和出栈的动作,上下文关联性很强,保证了用户动作生成的一致性,一般不会出现异常用户行为。但是,该方法在对话行为灵活性和多样性比较欠缺,在实操层面可以通过引入一些随机性提升灵活度。
代表论文:The Hidden Agenda User Simulation Model
论文链接:https://ieeexplore.ieee.org/document/4806280/?arnumber=4806280
![]()
首先,作者认为人机对话可以形式化为一系列状态转换和对话行为序列。在任意时刻 t ,用户在状态 S,采取动作![]() ,过渡到中间状态 S',收到对话系统回复的动作
,过渡到中间状态 S',收到对话系统回复的动作![]() ,然后转换到下一个状态 S'',然后以此往复,循环下去。
,然后转换到下一个状态 S'',然后以此往复,循环下去。
根据马尔科夫假设,用户行为可以分解为三个模型:![]() 用于建模用户动作选择,
用于建模用户动作选择,![]() 用于建模发出用户动作
用于建模发出用户动作
![]() 后用户状态转移到 S' 的概率,
后用户状态转移到 S' 的概率,![]() 用于建模接收到系统动作
用于建模接收到系统动作
![]() 后用户状态转移到 S'' 的概率。
后用户状态转移到 S'' 的概率。
用户状态 S 被分为 2 部分表示:Agenda 的内容 A 和用户目标 G。
G 由约束条件 C 和问询内容 R 组成。在对话的过程中,G 能保证用户行为是一致的且是任务导向的。
用户 Agenda 是一个类似堆栈的结构,它存储着待执行的用户对话行为(user dialogue act)。在对话开始时,使用系统数据库随机生成新的用户目标,然后会将用户目标中所有目标约束转换为告知行为(inform acts),所有的目标问询转换为问询行为(request acts)填充到用户 Agenda。在 Agenda 的底部,会添加一个 bye act 用于结束对话。
随着对话的进行,Agenda 和 Goal 会动态更新,并从 Agenda 的顶部弹出用户对话行为以形成本轮用户动作![]() 。在接收到系统回复
。在接收到系统回复![]() 后,根据写好的规则新的用户动作会被压入到 Agenda 的栈顶,不相关的用户动作会被删除。当需要考虑动作的优先级时,栈顶的用户动作也可以临时被缓存起来先执行优先级高的动作,从而为模拟器提供简单的用户记忆模型。图 2 给出了用户目标和 Agenda 变化的示例。
后,根据写好的规则新的用户动作会被压入到 Agenda 的栈顶,不相关的用户动作会被删除。当需要考虑动作的优先级时,栈顶的用户动作也可以临时被缓存起来先执行优先级高的动作,从而为模拟器提供简单的用户记忆模型。图 2 给出了用户目标和 Agenda 变化的示例。
 ▲ 图2. 表示用户目标和agenda的状态变化的示例
用户动作选择模型
▲ 图2. 表示用户目标和agenda的状态变化的示例
用户动作选择模型![]() ,其中 δ 为狄拉克函数,A[N] 代表栈顶的元素, A[1] 代表栈底的元素, A[N-n+1..N] 代表在 Agenda 栈顶的 top-n 的用户动作 acts,该模型的直观理解是如果
,其中 δ 为狄拉克函数,A[N] 代表栈顶的元素, A[1] 代表栈底的元素, A[N-n+1..N] 代表在 Agenda 栈顶的 top-n 的用户动作 acts,该模型的直观理解是如果
![]() 在 top-n 的 acts 里,那么 P 趋于 1,此时
在 top-n 的 acts 里,那么 P 趋于 1,此时
![]() 将会被选中并发出。top-n 的 n 的选取体现了用户模拟器的主动性程度,它可以从对话语料中统计得出,也可以根据经验指定一个小的数值。
状态更新模型
将会被选中并发出。top-n 的 n 的选取体现了用户模拟器的主动性程度,它可以从对话语料中统计得出,也可以根据经验指定一个小的数值。
状态更新模型![]() ,其中 A' 代表选择
,其中 A' 代表选择![]() 后的 Agenda,N'=N-n 代表 A' 的大小,为了使 P 概率最大,则要求 A' 等于对 A 进行出栈操作后的结果 A[1..N'],G 保持不变。
已知 S=(A,G),根据概率的链式法则和条件独立性假设,在用户模拟器接收到
后的 Agenda,N'=N-n 代表 A' 的大小,为了使 P 概率最大,则要求 A' 等于对 A 进行出栈操作后的结果 A[1..N'],G 保持不变。
已知 S=(A,G),根据概率的链式法则和条件独立性假设,在用户模拟器接收到![]() 后,可以将状态转移模型
后,可以将状态转移模型![]() 分解成 Agenda 更新模型和 Goal 更新模型。
如果不对 A'' 和 G'' 做限制,模型可能的状态转移空间太大,参数太多而不能直接人工指定,甚至通过大量的训练数据都不能获得一个可靠的参数估计。但如果假设 A'' 是从 A' 推导出来的,G'' 是从 G' 推导出来的,那么在每种情况下,仅需要有限个数的原子操作就能描述这个状态转移过程。
分解成 Agenda 更新模型和 Goal 更新模型。
如果不对 A'' 和 G'' 做限制,模型可能的状态转移空间太大,参数太多而不能直接人工指定,甚至通过大量的训练数据都不能获得一个可靠的参数估计。但如果假设 A'' 是从 A' 推导出来的,G'' 是从 G' 推导出来的,那么在每种情况下,仅需要有限个数的原子操作就能描述这个状态转移过程。
接下来,我们详细分析 Agenda 更新模型。Agenda 从 A' 转移 A'' 的过程可以看做一系列入栈操作,将用户 dialogue acts 添加到栈的顶部。接下来会进行“清理”工作,比如:删除冗余的 dialogue acts,null() acts 以及 Goal 中那些已经被填充的 request slots 关联的 request() acts。
为了简化起见,只考虑入栈操作,栈底部 1 到 N' 的元素是保持不变的,那么 Agenda 更新模型可以改写为以下公式:
该公式表示 A'' 新增 N''-N' 个元素,而栈底元素不变。作者假设在![]() 中的每一个系统 act 只会触发一个入栈操作,令 N''=N'+M,可得:
上式表示的是每一个系统 act 会触发一个入栈操作,同时该操作还和 Goal 有关。此时,模型已经足够简单,都可以通过编写人工规则来实现当接收到系统 act 后的逻辑,比如:当
中的每一个系统 act 只会触发一个入栈操作,令 N''=N'+M,可得:
上式表示的是每一个系统 act 会触发一个入栈操作,同时该操作还和 Goal 有关。此时,模型已经足够简单,都可以通过编写人工规则来实现当接收到系统 act 后的逻辑,比如:当 ![]() [i] 中的元素 x=y 和 G'' 里的约束条件冲突时,可以将以下任意一个用户 act 压入栈 A'':negate(),inform(x=z),deny(x=y, x=z) 等。
Goal 更新模型
[i] 中的元素 x=y 和 G'' 里的约束条件冲突时,可以将以下任意一个用户 act 压入栈 A'':negate(),inform(x=z),deny(x=y, x=z) 等。
Goal 更新模型![]() 描述的是当给定
描述的是当给定
![]() 的情形下,约束条件 C' 和问询内容是如何变化的。假定当给定 C'' 的情形下,R'' 是条件独立于 C'' 的,那么可以得到:
的情形下,约束条件 C' 和问询内容是如何变化的。假定当给定 C'' 的情形下,R'' 是条件独立于 C'' 的,那么可以得到:
为了控制 R' 转移到 R'' 的空间大小,可以假设问询的槽位是相互独立的,并且每个槽只能利用 ![]() 的信息来更新,或者保持不变。利用 R[k] 表示第 k 个可问询槽,M(
的信息来更新,或者保持不变。利用 R[k] 表示第 k 个可问询槽,M(![]() ,C'') 表示
,C'') 表示 ![]() 中的槽信息与 Goal 约束条件的匹配情况。
中的槽信息与 Goal 约束条件的匹配情况。
为了简化 P(C''|![]() ,R',C'),作者假设 C'' 是通过添加新约束条件,改变约束条件的槽值或者什么都不改变得到的。转移过程也不用考虑所有的情形,可以简化为只考虑
,R',C'),作者假设 C'' 是通过添加新约束条件,改变约束条件的槽值或者什么都不改变得到的。转移过程也不用考虑所有的情形,可以简化为只考虑 ![]() 的一些二值标识,比如:“
的一些二值标识,比如:“![]() 是否在请求约束条件的槽?”,“
是否在请求约束条件的槽?”,“![]() 是否在告知没有找到满足约束条件的元素?”等。这样模型可以简化到可以通过人工编写规则实现,落地性很强。
通过人工编写规则尽管落地性强,精准率高,但是成本很高,因此寻求数据驱动的模型化方法是一个很好的途径。利用对话语料进行端到端训练的效果优于基于议程的规则方法,它的优点是数据驱动,节省人力;但缺点是复杂对话建模困难,对数据数量要求很高,因此对于一些对话语料稀缺的领域效果很差。
是否在告知没有找到满足约束条件的元素?”等。这样模型可以简化到可以通过人工编写规则实现,落地性很强。
通过人工编写规则尽管落地性强,精准率高,但是成本很高,因此寻求数据驱动的模型化方法是一个很好的途径。利用对话语料进行端到端训练的效果优于基于议程的规则方法,它的优点是数据驱动,节省人力;但缺点是复杂对话建模困难,对数据数量要求很高,因此对于一些对话语料稀缺的领域效果很差。
论文 [4] 最早提出了 bi-gram 模型,通过给定系统动作![]() 预测用户动作
预测用户动作![]() ,
,![]() , 从而对用户模型进行概率建模。尽管 bi-gram 模型简单可用,但是由于没有对整个对话历史和用户目标进行有效建模,模拟出来用户行为通常过于随机不够真实。随后提出的 Levin model [5],Schefller model [6], Pietquin Model [7] 均在 bi-gram 模型上进行了一定改进,使得用户动作的生成有一定的约束。
在用户模型的序列建模上,论文 [16] 利用隐马尔科夫模型来推断每一轮的用户动作。论文
[8] 则研究了基于概率图的用户模型,如图 3 所示,g 是用户目标, 分别是系统动作、用户隐动作,对话历史和用户观测动作,通过 EM 算法优化模型参数。
, 从而对用户模型进行概率建模。尽管 bi-gram 模型简单可用,但是由于没有对整个对话历史和用户目标进行有效建模,模拟出来用户行为通常过于随机不够真实。随后提出的 Levin model [5],Schefller model [6], Pietquin Model [7] 均在 bi-gram 模型上进行了一定改进,使得用户动作的生成有一定的约束。
在用户模型的序列建模上,论文 [16] 利用隐马尔科夫模型来推断每一轮的用户动作。论文
[8] 则研究了基于概率图的用户模型,如图 3 所示,g 是用户目标, 分别是系统动作、用户隐动作,对话历史和用户观测动作,通过 EM 算法优化模型参数。
以上都是比较早期的统计建模方法,我们不再赘述。本文主要想从学习范式的角度对近几年涌现的一些优秀论文进行介绍,包括:端到端有监督学习 [9, 10]、联合策略优化 [13]、逆强化学习 [11] 和协同过滤方法
[12]。
代表论文1:A Sequence-to-Sequence Model for User Simulation in Spoken Dialogue Systems
论文链接:https://arxiv.org/abs/1607.00070
![]()
用户模拟器的一个重要特征是它鼓励整个对话中的连贯行为,而由于之前的概率模型从易于实现的角度,基本不考虑很长的对话历史和单句多意图的情况,导致了整个对话效率比较低下。基于此作者提出了一种 Sequence-to-sequence 的用户模拟器模型(如图 4 所示),它将对话上下文序列![]() 作为输入,然后输出用户动作序列
作为输入,然后输出用户动作序列![]() 。
。
在每次对话开始之前,统一的构建出一个 Goal G=(C,R),对于餐馆查询任务而言,约束条件通常指的是菜品口味、菜品价格以及餐馆所在方位,问询内容为以下槽位:餐馆名称、餐馆地址、餐馆电话等。
在第 t 轮对话,一个上下文![]() 包含以下 4 部分:1)上一轮的系统动作
包含以下 4 部分:1)上一轮的系统动作![]() ;2)上一轮系统回复的信息与 User Goal 不一致的部分
;2)上一轮系统回复的信息与 User Goal 不一致的部分![]() ;3)约束条件的状态
;3)约束条件的状态![]() (告知与否);4)问询内容的状态
(告知与否);4)问询内容的状态![]() (被告知与否)。
在每次对话的过程中,会根据 dialogue acts 的个数以及 Goal 的状态,对以上 4 部分进行 one-hot 编码,从而得到对话上下文的向量化表示。如下表所示:
(被告知与否)。
在每次对话的过程中,会根据 dialogue acts 的个数以及 Goal 的状态,对以上 4 部分进行 one-hot 编码,从而得到对话上下文的向量化表示。如下表所示:
在 t 时刻,将上下文序列![]() 输入到一个 encoder LSTM 网络,得到一个向量
输入到一个 encoder LSTM 网络,得到一个向量![]() 作为对话历史的内部表示。其中,
作为对话历史的内部表示。其中,![]() ,⊙ 代表拼接操作。
然后再将向量
,⊙ 代表拼接操作。
然后再将向量
![]() 输入到 decoder LSTM 网络,输出 dialogue acts 序列,比如 (inform, request)。接下来需要通过启发式规则将 dialogue acts 映射为带槽的用户行为,比如 inform(food=Chinese), request(price_range)。
作者也提到可以训练一个模型,让它直接输出最终的行为,比如 request_area,inform_pricerange。这种方式的优点是不需要写启发式规则,可以做到更细粒度的建模,这也是作者推荐的方式。最后实验结果证明效果优于基于议程的方法。
输入到 decoder LSTM 网络,输出 dialogue acts 序列,比如 (inform, request)。接下来需要通过启发式规则将 dialogue acts 映射为带槽的用户行为,比如 inform(food=Chinese), request(price_range)。
作者也提到可以训练一个模型,让它直接输出最终的行为,比如 request_area,inform_pricerange。这种方式的优点是不需要写启发式规则,可以做到更细粒度的建模,这也是作者推荐的方式。最后实验结果证明效果优于基于议程的方法。
代表论文2:Neural User Simulation for Corpus-based Policy Optimization for Spoken Dialogue Systems
论文链接:
https://aclweb.org/anthology/papers/W/W18/W18-5007/
![]()
上一篇论文中的一些端到端系统虽然对整个对话历史都进行了跟踪,并且用户的行为是从数据中学习得到的,但是依旧存在两个问题:1)没有对用户的目标改变(goal change)进行建模;2)只在语义层面进行用户模拟,需要耗费人力标注出每轮用户语句的语义标签进行模型训练,而不是直接利用自然语句进行训练。
因此该论文提出了基于 RNN 的 Neural User Simulator (NUS) 模型。首先 NUS 通过用户目标生成器,对原对话数据中的对话状态标签进行预处理,得到一个完整对话中每一轮的具体用户目标,这样就相当于对用户目标改变进行了某种程度上的建模,如下表所示:
表中显示某个对话一共有四轮,其中 第 2、3 轮之间出现了对 food 这个槽位的 goal change, 因此右边处理之后得到了用户目标也出现了变化。这样的用户目标不再是一成不变,而是充分根据对话数据给出了动态的用户目标,更加贴近实际。
有了每轮的用户目标,NUS 通过 RNN 来生成用户语句, 如图 5 所示:
 ▲ 图5. 神经用户模拟器的端到端模型
▲ 图5. 神经用户模拟器的端到端模型
图中![]() 是每一轮提取出来的特征,它一共包含四个向量
是每一轮提取出来的特征,它一共包含四个向量![]() :其中
:其中![]() 是系统动作向量,包含
是系统动作向量,包含![]() ,
,![]() 是一个长度等于所有可能的系统动作的二进制向量,
是一个长度等于所有可能的系统动作的二进制向量,![]() 是一个长度为可告知槽(informable slots)总个数 4 倍的二进制向量,用来表示本轮系统动作是否出现了 request、select、inform 和 expl-conf 这四个以可告知槽为参数的动作。
例如出现了 request(area) 则将
是一个长度为可告知槽(informable slots)总个数 4 倍的二进制向量,用来表示本轮系统动作是否出现了 request、select、inform 和 expl-conf 这四个以可告知槽为参数的动作。
例如出现了 request(area) 则将![]() 中对应位置处元素置 1;
中对应位置处元素置 1;![]() 称作问询向量,是一个长度和可问询槽(requestable slots)总个数相等的二进制向量,用来标记哪些用户目标中需要问询的可问询槽还没有被用户向系统提问;
称作问询向量,是一个长度和可问询槽(requestable slots)总个数相等的二进制向量,用来标记哪些用户目标中需要问询的可问询槽还没有被用户向系统提问;![]() 称作不一致向量(inconsistency vector), 长度等于可告知槽总个数,一旦系统动作中对某个槽出现了和本轮用户目标不一致的情况,对应的位置处元素置 1。
称作不一致向量(inconsistency vector), 长度等于可告知槽总个数,一旦系统动作中对某个槽出现了和本轮用户目标不一致的情况,对应的位置处元素置 1。
![]() 是用户目标约束向量,长度等于可告知槽总个数,用来表示本轮用户目标中出现了哪些可告知槽。
NUS 生成的回复是去词汇化的自然语句,经过后处理则得到了用户的自然语言回复。论文为了论证 NUS 效果优异 Agenda-based User Simulator (ABUS), 提出了一个交叉模型评估的方法,即在一个 User Simulator 上训练一个 agent,在其他 User Simulator 上测试该 agent,如果 agent 效果依旧很好,说明用于训练的 User Simulator 是更加贴近真实用户。
最终实验结果证明,在 NUS 上训练得到了的 agent,在 ABUS 和真实用户上测试得到的成功率均优于 ABUS,而在 ABUS 上训练得到的 agent 效果只在 ABUS 上测试好。
是用户目标约束向量,长度等于可告知槽总个数,用来表示本轮用户目标中出现了哪些可告知槽。
NUS 生成的回复是去词汇化的自然语句,经过后处理则得到了用户的自然语言回复。论文为了论证 NUS 效果优异 Agenda-based User Simulator (ABUS), 提出了一个交叉模型评估的方法,即在一个 User Simulator 上训练一个 agent,在其他 User Simulator 上测试该 agent,如果 agent 效果依旧很好,说明用于训练的 User Simulator 是更加贴近真实用户。
最终实验结果证明,在 NUS 上训练得到了的 agent,在 ABUS 和真实用户上测试得到的成功率均优于 ABUS,而在 ABUS 上训练得到的 agent 效果只在 ABUS 上测试好。
代表论文:Iterative Policy Learning in End-to-End Trainable Task-Oriented Neural Dialog Models
论文链接:https://arxiv.org/abs/1709.06136v1
![]()
用户模型和对话管理模型功能十分接近,因此对用户模型也采用强化学习的框架,将用户模拟器和对话系统联合优化是一个可行的方向。论文在对用户模拟器和对话系统分别采用了 RNN 进行端到端的建模并使用同一个回报函数优化,两者交替训练共同最大化累计回报。
论文使用的对话系统是一个端到端的 LSTM 模型,如图 6 所示:
对话系统的状态由 LSTM 的隐层节点编码,每一轮都会进行更新。在第 k 轮对话,给定上一轮的系统语句
 ,用户语句
,用户语句  ,数据库查询结果
,数据库查询结果  作为输入,LSTM 模型更新上一轮的对话状态
作为输入,LSTM 模型更新上一轮的对话状态  为
为  。新的对话状态
。新的对话状态  通过前馈神经网络可以直接预测出本轮各个槽的跟踪分布、系统应采取的对话动作
通过前馈神经网络可以直接预测出本轮各个槽的跟踪分布、系统应采取的对话动作  和一个 one-hot 编码的数据库指针 。NLG 部分作者选择采用模板的方法生成。
和一个 one-hot 编码的数据库指针 。NLG 部分作者选择采用模板的方法生成。
对应的用户模拟器的结构如图 7 所示。它也是采用了端到端的 LSTM 模型,输入换作了用户目标编码  ,上一轮用户语句
,上一轮用户语句
 和当前轮系统语句
和当前轮系统语句  ,模型每轮更新用户状态
,模型每轮更新用户状态  为
为  。新的用户状态
。新的用户状态  也通过前馈神经网络得到本轮用户应采取的动作和槽值参数。NLG 部分采用模板的方法直接生成。
也通过前馈神经网络得到本轮用户应采取的动作和槽值参数。NLG 部分采用模板的方法直接生成。
作者对用户模拟器和对话系统进行联合策略优化,使用了策略梯度(policy gradient)算法,两者各自的状态为  和
和  ,动作为
,动作为  和
和  。回报函数采用:
。回报函数采用:
 是用户目标,
是用户目标, 是对话系统对用户目标的估计,D( · ) 是一个得分函数。根据相邻轮得分函数之差可以得到单轮回报函数
是对话系统对用户目标的估计,D( · ) 是一个得分函数。根据相邻轮得分函数之差可以得到单轮回报函数![]() 。用户模拟器和对话系统交替优化,共同最大化累计回报函数
。用户模拟器和对话系统交替优化,共同最大化累计回报函数![]() 。
为了降低 REINFORCE 策略梯度优化的方差,论文采用 Advantage Actor-Critic (A2C) 算法,并使用 ε-softmax 进行策略探索,在 DSTC2 数据集上进行了初步实验,结果如下:
。
为了降低 REINFORCE 策略梯度优化的方差,论文采用 Advantage Actor-Critic (A2C) 算法,并使用 ε-softmax 进行策略探索,在 DSTC2 数据集上进行了初步实验,结果如下:
代表论文:User Simulation in Dialogue Systems using Inverse Reinforcement Learning
论文链接:https://core.ac.uk/download/pdf/52801075.pdf
![]()
在马尔科夫决策过程 (MDP) 的框架下, 强化学习在是回报函数(reward function)给定下,找出最优策略以最大化累计反馈,而逆强化学习(Inverse reinforcement learning, IRL)就是通过给出最优策略估计出回报函数。
通常最优策略会通过专家行为近似得到,例如请经验丰富的专家充当用户直接给出合理的回复。需要注意的是模仿学习(imitation learning)和 IRL 不同,模仿学习是直接通过专家行为的数据优化策略而不估计回报函数。
目前很多基于强化学习的对话管理模块中,回报函数多以是否成功和总轮数给出,不够多样真实,IRL 方法对于优化回报函数也有很大的潜力,值得研究。
论文给出了 UserMDP,对用户模拟器也进行 MDP 建模,利用 IRL 估计出回报函数,从而为 User simulator 和 Agent 交替使用强化学习优化提供有效途径。
首先论文假设回报函数是状态动作特征基函数的线性拟合:
![]() 被称作特征期望(feature expectation),实际中通过采样统计得到,设采样了 m 个 episode 序列样本,第 i 个序列的长度记为 Hi。
被称作特征期望(feature expectation),实际中通过采样统计得到,设采样了 m 个 episode 序列样本,第 i 个序列的长度记为 Hi。
![]() 首先通过对话语料收集出真实的用户对话策略的特征期望 , 并且初始化用户模拟器的对话策略
首先通过对话语料收集出真实的用户对话策略的特征期望 , 并且初始化用户模拟器的对话策略![]() ,通过采样得到模拟用户的特征期望
,通过采样得到模拟用户的特征期望![]() ,
,![]() 添加到对话策略集合 Π 中; 然后经过多次迭代,每次根据估计出的回报函数进一步求解出新的最优对话策略
添加到对话策略集合 Π 中; 然后经过多次迭代,每次根据估计出的回报函数进一步求解出新的最优对话策略![]() 并添加到策略集合 Π 中。算法最终可以合理估计出回报函数的,该回报函数和专家策略
并添加到策略集合 Π 中。算法最终可以合理估计出回报函数的,该回报函数和专家策略![]() 相容。
论文中实验结果表明,通过对 IRL 找出来的策略集合 Π 进行加权随机采样得到的用户对话策略相比于固定的用户策略(专家行为)有更短的对话轮数和更高的 reward 值。说明了 IRL 方法在估计出回报函数的同时也能得到更加多样真实的策略,这在某些场景下将会非常有用。
相容。
论文中实验结果表明,通过对 IRL 找出来的策略集合 Π 进行加权随机采样得到的用户对话策略相比于固定的用户策略(专家行为)有更短的对话轮数和更高的 reward 值。说明了 IRL 方法在估计出回报函数的同时也能得到更加多样真实的策略,这在某些场景下将会非常有用。
代表论文:Collaboration-based User Simulation for Goal-oriented Dialog Systems
论文链接:http://www.alborz-geramifard.com/workshops/nips17-Conversational-AI/Papers/17nipsw-cai-collaboration-based-simulator.pdf
![]()
在有高质量语料库的情况下,我们可以考虑直接根据对话上下文,从语料库中推荐出最恰当的用户语句作为用户模拟器的回复。Amazon 的论文就是根据这样的想法设计了基于协同过滤算法的用户模拟器。首先,论文论证了在客服领域,对话系统的语句表达相比于用户的表达通常比较规整单一,因此可以对所有的用户语句进行粗略的标注,如图 8 所示:
▲ 图8. (a) 每个对话被转换成语义标签序列 (b) 正在进行的对话和语料库对话的匹配示意图,红橙色表示系统标签,绿色表示用户语句
系统语句被赋予了 salutation、apology 等等语义标签,这样语料库中的对话都被抽象成了一个个语义标签序列,每次进行用户语句推荐时,通过计算正在进行的对话所对应的语义标签序列和语料库中每个对话对应的语义标签序列的编辑距离进行粗筛,得到本轮用户语句回复的候选集,再对候选集中各个用户语句所在对话的上一轮系统语句的 tf-idf 特征排序进行 re-rank,从而选择最佳用户语句回复。
-
-
-
可以从目标信息中自动化地计算出一个标量值,而无需人工干预。
论文实验结果显示,由协同过滤的方法所给出的用户语句在众包平台上评估得到的可行率为 84.7%。
用户模拟器的评价方式
论文 [14] 提出,一个好的用户模拟器的评价方式需要满足以下几点要求:
-
-
-
可以从目标信息中自动化地计算出一个标量值,而无需人工干预。
通常用户模拟器的评价指标可以分为单轮级别度量 (turn-level metrics) 和对话级别度量 (dialog-level metrics)。
单轮级别度量主要针对用户动作的语义标签,最常见度量是精确率,召回率和 F1 得分,对于每一轮可以计算:
但是以上的度量不能评估用户模型泛化能力,例如某个用户动作是合理的但因为在对话数据中并未出现,如果预测了就会导致得分低。因此我们还可以将用户动作的预测概率分布P和真实概率分布 Q 之间的 KL 距离作为度量,从概率分布上评估用户预测模型的合理性。
类似地,也可以用过计算对数似然值或者混淆度(perplexity)来评估。
对话级别的度量最常用的是任务完成率和平均对话轮数。将用户模型和对话系统进行真实交互,完成训练后的对话系统所能达到的任务完成率(通过记录对话系统是否完成用户目标得到)和平均每个对话的轮数可以作为评价与用户模型整体效果的有效指标。
用户模拟器面临的挑战
1. 对话行为一致性(Coherence):对话行为要保证前后连贯,符合语境,避免出现不符合逻辑的对话行为。如何综合考虑对话上下文和 User Goal 等因素,保证用户行为序列在多轮交互过程中的一致性是一个有挑战的课题。
2. 对话行为多样性(Diversity):模拟用户群的行为特性,需要建模这个群体的行为分布。例如某用户群是健谈的还是寡言的,是犹豫的还是果断的,各部分占比多少,这里引入用户群体画像特征,使得用户模拟器的行为更加丰富多样,贴近目标用户群体。这个方向学术界有一些研究进展,值得继续深入研究。
3. 对话行为的泛化性(Generalization):目前来看,无论是基于规则方法还是基于模型学习的用户模拟器,在遇到语料中未曾出现的对话上下文时,表现出的泛化能力依旧比较有限。对话行为的泛化性直接体现了用户模拟器是否表现得如同真实用户一样处理更多未见的复杂的对话场景。这个方向有待学界更深入的探索。
总结
用户模拟器是对话系统形成闭环训练的重要组成部分,它和对话系统结构类似,但最大的区别在于增加了用户目标的建模。好的用户模拟器不仅能够生成连贯的动作,而且还能够体现多样性和泛化能力。
本综述详细地介绍了目前学界的常用模型和方法。由于学界一般关注的对话任务是订餐馆、订电影票、订飞机票这类简单的填槽(slot-filling)任务,对话的状态和动作空间有限,不需要太复杂的模型和大规模的语料就能获得比较好的效果,因此在数据充分的情况下,基于模型学习的方法在效果上普遍优于基于规则的方法。
而在工业界真实的场景里,除了上面的简单任务,占比更多的是“查话费”、“开发票”、“挂失信用卡”这类中等复杂度的场景,它的特点是机器人有外部 API 调用、基于 API 返回结果的分支判断、异常兜底逻辑、多个子意图的串联、多个填槽过程等,对话的状态和动作空间迅速扩大,需要有足量的训练语料才能保证用户模拟器的覆盖率。
因此在实际生产实践中,我们需要划分好场景,重新制定更加贴近业务的用户动作标签,统计出真实的用户目标,再选择最合适自身场景的模型来构建模拟器。
参考文献
[1] Li X, Chen Y N, Li L, et al. End-to-end task-completion neural dialogue systems[J]. arXiv preprint arXiv:1703.01008, 2017.
[2] Schatzmann J, Young S. The hidden agenda user simulation model[J]. IEEE transactions on audio, speech, and language processing, 2009, 17(4): 733-747.
[3] Schatzmann J, Thomson B, Weilhammer K, et al. Agenda-based user simulation for bootstrapping a POMDP dialogue system[C]//Human Language Technologies 2007: The Conference of the North American Chapter of the Association for Computational Linguistics; Companion Volume, Short Papers. Association for Computational Linguistics, 2007: 149-152.
[4]W. Eckert, E. Levin, and R. Pieraccini. 1997. User modelling for spoken dialogue system evaluation. In Proc. of ASRU ’97, pages 80–87.
[5]E. Levin, R. Pieraccini, and W. Eckert, “A stochastic model of human machine interaction for learning dialog strategies,” IEEE Trans. Speech Audio Process., vol. 8, no. 1, pp. 11–23, Jan. 2000.
[6]K. Scheffler and S. J. Young. 2001. Corpus-based dialogue simulation for automatic strategy learning and evaluation. In Proc. NAACL Workshop on Adaptation in Dialogue Systems, pages 64–70.
[7]O. Pietquin. 2004. A Framework for Unsupervised Learning of Dialogue Strategies. Ph.D. thesis, Faculte Polytechnique de Mons.
[8] Lee S, Eskenazi M. An unsupervised approach to user simulation: toward self-improving dialog systems[C]//Proceedings of the 13th Annual Meeting of the Special Interest Group on Discourse and Dialogue. Association for Computational Linguistics, 2012: 50-59.
[9] Layla El Asri, Jing He, and Kaheer Suleman. 2016. A sequence-to-sequence model for user simulation in spoken dialogue systems. Proceedings of the 17th Annual Conference of the International Speech Communication Association, pages 1151–1155
[10] Kreyssig F, Casanueva I, Budzianowski P, et al. Neural user simulation for corpus-based policy optimisation for spoken dialogue systems[J]. SIGDIAL, 2018.
[11] Chandramohan S, Geist M, Lefevre F, et al. User simulation in dialogue systems using inverse reinforcement learning[C]//Interspeech 2011. 2011: 1025-1028.
[12] Devin Didericksen,Oleg Rokhlenko, Kevin Small, Li Zhou, Jared Kramer. Collaboration-based User Simulation for Goal-oriented Dialog Systems. NIPS 2017
[13] Liu B, Lane I. Iterative policy learning in end-to-end trainable task-oriented neural dialog models[C]//2017 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU). IEEE, 2017: 482-489.
[14] Pietquin O, Hastie H. A survey on metrics for the evaluation of user simulations[J]. The knowledge engineering review, 2013, 28(1): 59-73.
[15] Shah P, Hakkani-Tür D, Tür G, et al. Building a conversational agent overnight with dialogue self-play[J]. NAACL, 2018.
[16] H. Cuayahuitl, S. Renals, O. Lemon, and H. Shimodaira, “Human computer dialogue simulation using hidden Markov models,” in Proc. ASRU, San Juan, Puerto Rico, 2005



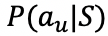 用于建模用户动作选择,
用于建模用户动作选择,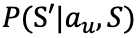 用于建模发出用户动作
用于建模发出用户动作
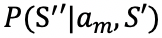 用于建模接收到系统动作
用于建模接收到系统动作
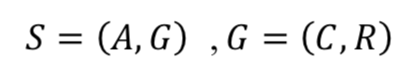
 ▲ 图2. 表示用户目标和agenda的状态变化的示例
▲ 图2. 表示用户目标和agenda的状态变化的示例
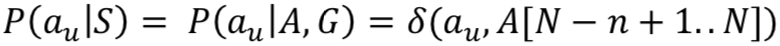 ,其中 δ 为狄拉克函数,A[N] 代表栈顶的元素, A[1] 代表栈底的元素, A[N-n+1..N] 代表在 Agenda 栈顶的 top-n 的用户动作 acts,该模型的直观理解是如果
,其中 δ 为狄拉克函数,A[N] 代表栈顶的元素, A[1] 代表栈底的元素, A[N-n+1..N] 代表在 Agenda 栈顶的 top-n 的用户动作 acts,该模型的直观理解是如果
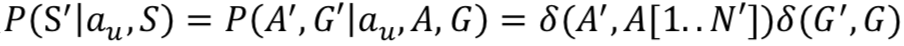 ,其中 A' 代表选择
,其中 A' 代表选择
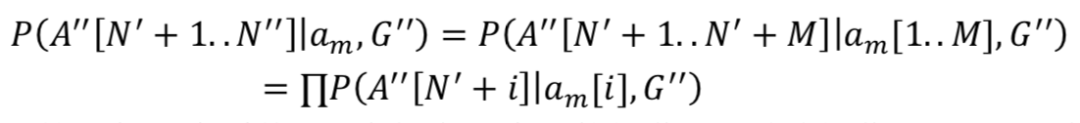
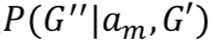 描述的是当给定
描述的是当给定
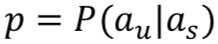 , 从而对用户模型进行概率建模。尽管 bi-gram 模型简单可用,但是由于没有对整个对话历史和用户目标进行有效建模,模拟出来用户行为通常过于随机不够真实。随后提出的 Levin model [5],Schefller model [6], Pietquin Model [7] 均在 bi-gram 模型上进行了一定改进,使得用户动作的生成有一定的约束。
, 从而对用户模型进行概率建模。尽管 bi-gram 模型简单可用,但是由于没有对整个对话历史和用户目标进行有效建模,模拟出来用户行为通常过于随机不够真实。随后提出的 Levin model [5],Schefller model [6], Pietquin Model [7] 均在 bi-gram 模型上进行了一定改进,使得用户动作的生成有一定的约束。


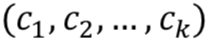 作为输入,然后输出用户动作序列
作为输入,然后输出用户动作序列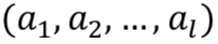 。
。

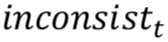 ;3)约束条件的状态
;3)约束条件的状态
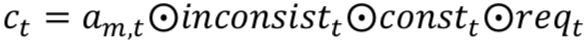 ,⊙ 代表拼接操作。
,⊙ 代表拼接操作。



 ▲ 图5. 神经用户模拟器的端到端模型
▲ 图5. 神经用户模拟器的端到端模型
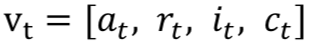 :其中
:其中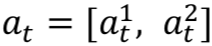 ,
,