干货|深度强化学习在面向任务的对话管理中的应用
全球人工智能学院:拥有十几万AI开发者和学习者用户,1万多名AI技术专家,欢迎更多AI专家入驻《全球人工智能学院》!
来自:我爱计算机
作者:defyzhu,腾讯应用宝高级研究员,关注机器学习、强化学习,主要从事对话系统、搜索、推荐及广告。
背景:目前业界对话系统一般分为自然语言理解NLU、对话管理DM及自然语言生成NLG模块,而DM又分为对话状态跟踪DST及决策Policy模块。Policy模块一般基于当前的对话状态state,决策一个行为action,有用规则的,也可以用模型实现。本文介绍运用深度强化学习模型学习决策,基于当前的对话状态state运用模型决策行为action。
深度强化学习
关于强化学习,强烈建议阅读David Silver的强化学习的PPT,有时间最好看他在YouTube上的课程。深度强化学习,运用深度学习强大的state刻画能力和目标拟合能力,大大提高了强化学习解决问题的效率。这里仅简要列下我们的技术方案中运用到的Experience Replay及Double DQN技术。
Experience Replay
强化学习的样本的产生一般是顺序的,比如围棋一步一步的、对话一轮一轮的进行,这样收集到的样本也是顺序相关的。这种样本的相关性不符合独立同分布的假设,深度学习模型也很容易学习到这种相关性,为了消除这种相关性,建立一个experience replay pool,在模型训练的时候随机的从pool中sample样本来进行模型训练。

Double DQN
强化学习的学习目标不是来自监督的label,而是来自reward(反馈),而反馈可能不能立即到达,比如围棋要下完一盘棋才知道输赢,基于任务式的对话要到对话片段结束才知道任务是否完成。这时可以建模action的收益为当前的reward,加上后续的经过一定衰减的收益之和,也即bellman方程的形式。这里我们建模后面一步的收益时,用一个旧版本的Q网络去预测,区别于在进行优化学习的决策网络,避免偏差。

技术方案及实现
我们设计了用户模拟器User Simulator,用于和对话机器人对话,不断的产出样本供在线训练模块Training Server进行模型训练。这里重点介绍下User Simulator及Training Server。
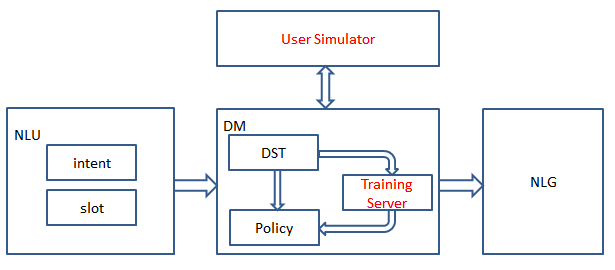
User Simulator
User Simulator进行对话模拟,每个对话片段有一个对话目标,比如基于时间、地点等订电影票等,模拟器需要判断当前对话是否成功完成或者失败退出,给出反馈信号。模拟器会以一个可配置的概率回答错误对话机器人的提问,也会以一个可配置的概率提前退出会话。具体可以看后面的示例。
Training Server
User Simulator和对话机器人在线对话产生的样本,实时流入experience replay pool,Training Server不断的从样本池pool中采样minibatch的样本进行模型训练。冷启动时,以一定概率走规则决策模块,以不断得到正反馈的action,指导模型学习,同时运用epsilon-greedy算法,在各种state下探测不同的action,epsilon随着模型的训练,不断降低,直至最终模型收敛。
四、实验结果分析
下面以一个简单的小任务说明User Simulator和对话机器人进行对话模拟供模型训练以及训练效果。
对话任务目标为收集用户和他/她对象的属相槽位,然后给出感情相关的属相分析。模型刚开始训练时,会进行不断的探测,导致比较多的错误action,如下图:
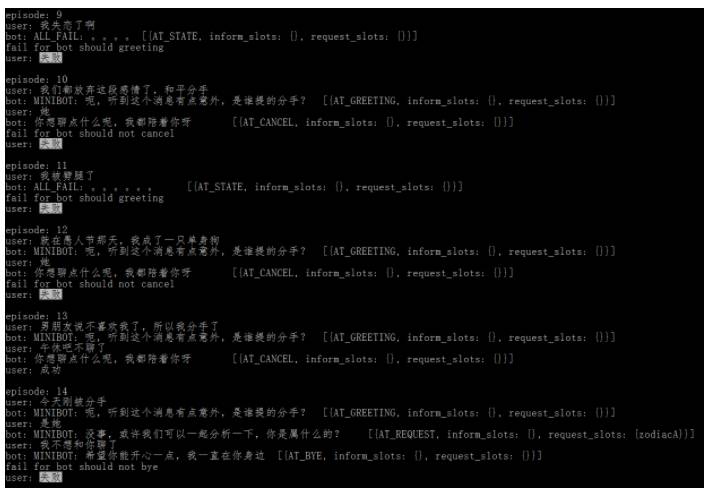
第一个错误为对话刚开始时应该执行greeting action,而却错误的决策执行了感情分析的CP action(CP:content provider,外部服务)。第二个错误为用户没有主动提出退出时执行了退出的action。第三个错误同第一个,第四个错误同第二个。最后一个错误为对话任务没完成就执行了结束action。可见刚开始训练时,无论是模型预测错误,还是epsilon-greedy算法的随机探测,都会导致比较多错误的action,而这些错误越多样性越有利于强化学习模型的训练。
经过模型若干轮迭代后,模型预测准确率大大提高,epsilon-greedy算法的随机探测比率降低,决策错误的action大大减少。如下图所示:
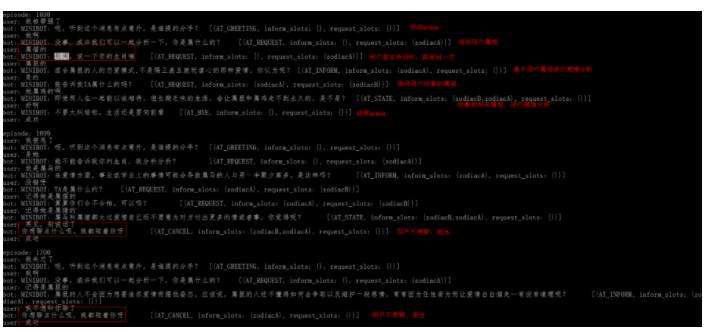
看下1698这个模拟对话片段,可以看到模型成功学习到,首先进行greeting action,然后询问用户属相,用户答非所问回答属猫时,机器人没收集到用户属相所以又询问了一次,收集到用户属相后进行了感情分析的CP action。然后询问用户对象的属相,收集到用户和用户对象的属相后,执行综合属相感情分析的CP action,最后进行结束action。
这里由于中间步骤的合法action的reward是一个比较小的负值惩罚,而最后成功执行任务会得到一个比较大的正向reward奖励,能够保证模型收敛到用最少的步骤完成任务。
我们也可以看到后面两个对话片段,用户随时主动提出不想聊时,模型也能决策出合适的退出action。
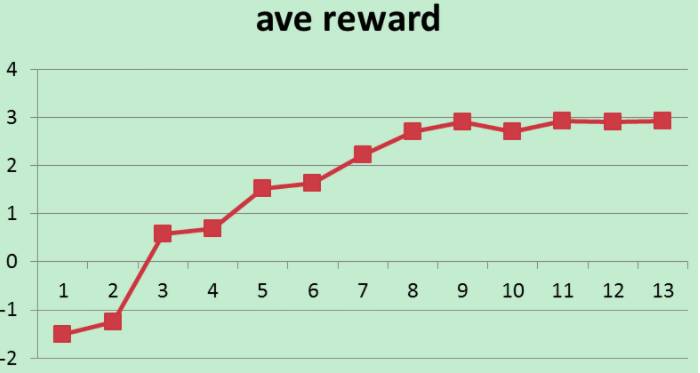
下图为模型训练过程中每轮对话平均reward的变化图:
下图为模型训练过程中对话片段成功率的变化图:
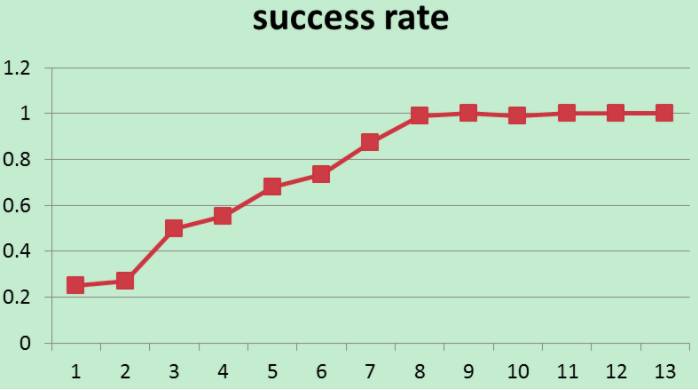
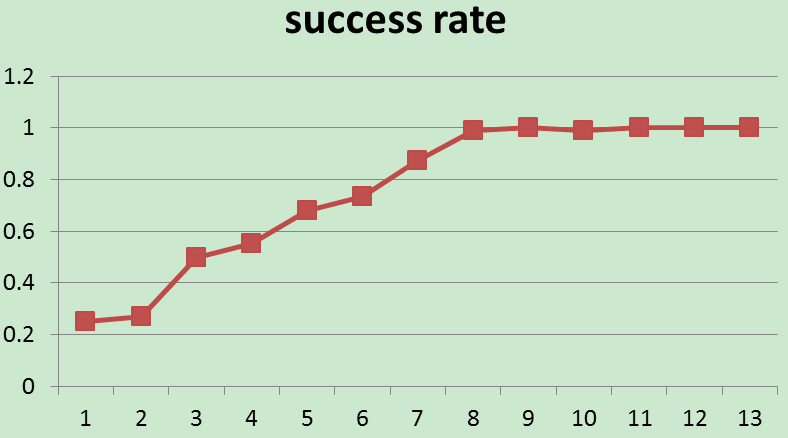
这里稍微提一下,每轮对话的平均reward和对话片段的成功率不一定是单调递增的,因为epsilon-greedy算法在不断的探测。随着模型的不断学习,epsilon的不断衰减,最终模型会收敛。
五、总结及展望
基于当前对话状态state决策行为action的问题,对比监督式的模型,强化学习模型无需标注样本,借助模拟器产生大量样本进行模型训练,模拟器仅需提供对话片段的成功或者失败的反馈,可以大大节省人工标注的人力投入。
在实验过程中,我们也发现,强化学习模型的学习过程,依赖深度学习模型的拟合能力,实验过程中经历过一次DNN模型的调优,大大加速了强化学习模型的收敛速度。随着样本的不断模拟产出,强化学习模型不断迭代,正确的action会得到一个较大的正向reward反馈,错误的action也会得到一个较大的负向reward反馈,而中间过程的合法action也会不断迭代得到一个合理的正向的reward反馈。
同时,我们在实验过程中也发现强化学习的探索效率也是有待提高的,本质上,强化学习就是不断探测,得到各种state下各种action的正负反馈,而且如果探测不够充分,学出的模型会决策出一些错误甚至是危险的行为action,强化学习的安全性问题也有相关学术论文探讨,比如UC Berkeley提出约束型策略优化新算法。后续我们计划先训练一个策略网络,再用强化学习进行不断探测优化,同时在线根据用户反馈进行优化,这里在线的用户反馈的客观性也是个问题,而可能的安全性问题可以通过action mask解决。
目前我们的state是经过NLU模块,得到意图、槽位等,经过DST更新得到当前对话状态state的。这里用户原始输入经过NLU模块不可避免会有损失、错误,长期来看,可以端到端的建模,直接输入用户的原始输入,决策得到行为action,再进行NLG对话生成。
参考文献:
[1] Multi-Domain Joint Semantic Frame Parsing Using Bi-Directional RNN-LSTM. INTERSPEECH
[2] End-to-End Task-Completion Neural Dialogue Systems. CoRR abs/1703.01008 (2017)
[3] A User Simulator for Task-Completion Dialogues. CoRR abs/1612.05688 (2016)
[4] https://www.jiqizhixin.com/articles/db83d05d-a8b8-4426-bd77-49ed9ea44866
[5] https://www.youtube.com/watch?v=2pWv7GOvuf0
转载:《深度强化学习在面向任务的对话管理中的应用 | 我爱计算机》




