不使用先验知识与复杂训练策略,从头训练二值神经网络!
选自 arxiv
作者:Joseph Bethge、Marvin Bornstein、Adrian Loy、Haojin Yang、Christoph Meinel
机器之心编译
参与:张玺、路
来自德国哈索普拉特纳研究院 (Hasso Plattner Institute) 的研究者近日发布论文,介绍了他们提出的训练二值神经网络新方法。该方法不使用以往研究通过全精度模型得到的先验知识和复杂训练策略,也能实现目前准确率最佳的二值神经网络。
引言
现在,日常生活中许多工作的自动化处理已取得重要的研究进展──从家用扫地机器人到工业生产线机器人,许多工作已经实现高度自动化。其他技术(如自动驾驶汽车)目前正处于发展过程中,并且强烈依赖于机器学习解决方案。智能手机上采用深度学习技术处理各种任务的 APP 数量一直保持快速增长,且未来仍将继续增长。所有这些设备的算力有限,通常要努力最小化能耗,但却有许多机器学习的应用场景。
以全自动驾驶汽车为例,保证实时图像处理同时达到高精度是系统关键。此外,由于该模式下很难保证稳定的低延迟网络连接,因此图像处理系统需配置于汽车内部。该配置要求虽然会限制可支配计算力及内存,但也将从低能耗中获取收益。最有希望解决上述问题的技术之一就是二值神经网络(Binary Neural Network,BNN)。在 BNN 中,卷积神经网络(CNN)中常用的全精度权重被替换成二值权重。这使得存储空间理论上可压缩 32 倍,使 CPU only 架构能够完成更高效的推断。
本文的研究成果概括如下:
本文提出了一种训练二值模型的简单策略,不需要使用预训练全精度模型。
实验表明,该策略并未得益于其他常用方法(如 scaling factor 或自定义梯度计算)。
本文表明快捷连接(shortcut connection)数的增加能够显著改善 BNN 的分类准确率,并介绍了一种新方法:基于密集快捷连接(dense shortcut connection)创建有效的二值模型。
针对不同模型架构及规模,本文提出的方法较其他方法达到当前最优的准确率。
网络架构
在研究模型架构前,我们必须考虑 BNN 的主要缺点:首先,相较于全精度网络,BNN 的信息密度理论上是前者的 1/32。研究表明,32 位与 8 位网络之间的差别不大,且 8 位网络的准确率水平几乎与全精度网络相同 [3]。然而,bit-width 降低到 4 位甚至 1 位(二进制)时,准确率会明显下降 [8, 20]。因此,需要借助其他技术降低精度损失,例如增加通过网络的信息流。我们认为主要有三种方法能够帮助保存信息,且无需担心网络二值化:
方法一:二值模型应该尽可能在网络中多使用快捷连接,使靠后的网络层能够使用靠前的网络层所获得的信息,不用担心二值化引起的信息损失。残差网络(Residual Network)[4] 与密集连接网络(Densely Connected Network)[7] 的全精度模型架构都使用了类似快捷连接。此外,网络层之间连接数的增加会改善模型性能,尤其是二值网络。
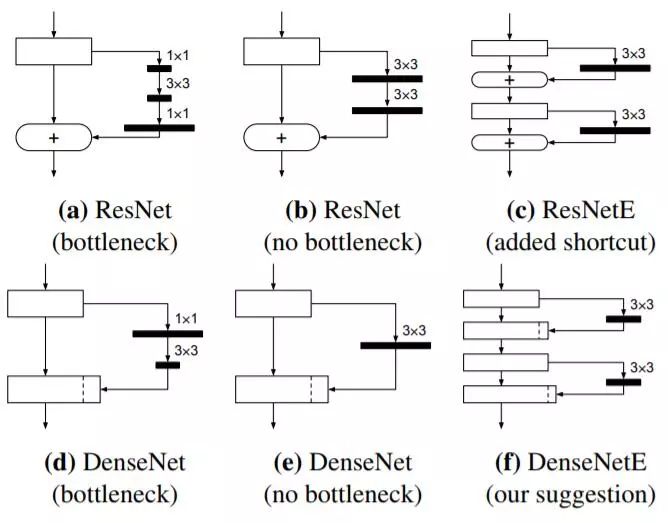
图 2:不同网络架构的单个构造块(加粗黑线的长度代表滤波器数量)。(a)带有瓶颈层架构的初始 ResNet 设计。少量滤波器会降低 BNN 的信息量。(b)无瓶颈层架构的 ResNet 设计。滤波器数量增加,但这时卷积层由 3 变为 2。(c)添加额外快捷连接的 ResNet 架构 [15]。(d)初始 DenseNet 设计,第二层卷积操作中出现瓶颈层。(e)无瓶颈层架构的 DenseNet 设计,两次卷积操作变成一次 3 × 3 卷积操作。(f)本文提出的 DenseNet 设计,具备 N 个滤波器的卷积操作被替换成两个层,每一层各使用 N/2 个滤波器。
方法二:与方法一思路相同,包含瓶颈层的网络架构始终是一项亟待解决的挑战。瓶颈层架构减少了滤波器数量,显著降低了网络层间的信息通路,最终使得 BNN 的信息流变少。因此,我们假定消除瓶颈层或增加瓶颈层的滤波器数量都能使 BNN 获取最好的结果。
方法三:将二值网络中的某些核心层替换为全精度层,以保存信息(提高模型准确率)。原因如下:如果网络层完成二值化,取消快捷连接,则(二值化产生的)信息损失无法在后续的网络层中复原,这将影响第一层(卷积层)和最后一层(全连接层,输出神经元数与类别数相同)。第一层为整个网络产生初始信息,最后一层使用最终信息进行预测。因此,我们在第一层使用全精度层,最后一层使用全网络架构。关于该决策,我们采用了之前研究 [16,20] 的成果,其通过实验验证了第一层和最后一层的二值化将大幅降低准确率,且节省的内存及计算资源非常有限。深度网络的另一个关键部分是下采样卷积,其将网络先前收集的所有信息转化为规模较小且具备更多通道的特征图(该卷积通常步幅为 2,输出通道数两倍于输入通道数)。下采样过程中损失的的任何信息将不可恢复。因此,即便会增加模型规模和运算次数,下采样层是否应该被替换为全精度层始终需要仔细权衡。
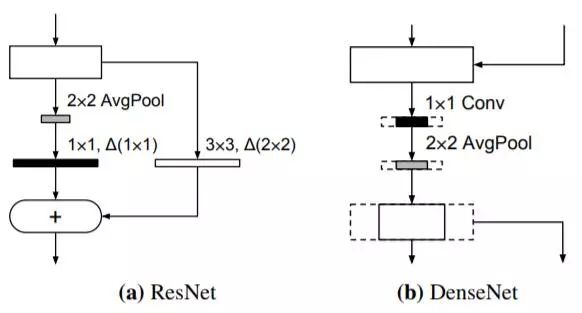
图 3:ResNet 与 DenseNet 的下采样层。加粗黑线表示下采样层,它可被替换为全精度层。如果在 DenseNet 中使用全精度下采样层,则需要加大减少通道数量的缩减率(虚线表示没有减少的通道数量)。
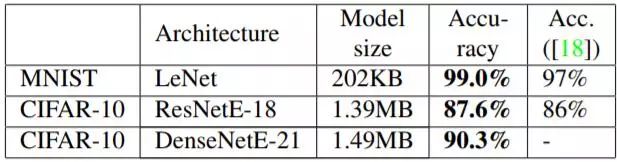
表 1:在 MNIST 和 CIFAR-10 数据集上,本文提出的二值模型的性能与 Yang 等人 [18] 结果的对比。

表 7:在 ImageNet 数据集上,本文方法与当前最优二值模型的对比。所有方法都在下采样部分的卷积层中使用了全精度权重。
论文:Training Competitive Binary Neural Networks from Scratch

论文链接:https://arxiv.org/abs/1812.01965
代码链接:https://github.com/hpi-xnor/BMXNet-v2
摘要:卷积神经网络已在不同应用领域获得令人瞩目的成就。现有文献已提出许多在移动端和嵌入式设备中应用 CNN 模型的方法。针对计算力低的设备,二值神经网络是一项特别有前景的技术。然而,从零开始训练准确的二值模型仍是一项挑战。之前的研究工作通常使用全精度模型产生的先验知识与复杂的训练策略。本研究关注如何在不使用类似先验知识与复杂训练策略的前提下,改善二值神经网络的性能。实验表明,在标准基准数据集上,本文提出的方法能达到当前最优水平。此外,据我们所知,我们首次成功地将密集连接网络架构应用于二值网络,提高了当前最优的性能。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com


