「Caffe架构+5.5万行代码+芯片每秒6万亿次浮点运算」这是AMD深度学习的开源战略
当一家公司开始使用突破性技术或商业模式时,其结果可能是令人难以想象的,甚至让竞争对手完全丧失追赶的可能。
能够达到这种结果的原因是:尽管公司的早期发展看起来是线性的,但其最终将显现为以指数形式增长。当一家公司到达这一点时,竞争对手再想赶上就变得非常困难,几乎不可能了。
本文将探讨AMD的深度学习开源策略,并解释AMD ROCm计划在加速深度学习发展方面的优势。回答AMD的竞争对手,是否需要关注AMD正在进行的突破性改变的问题。
▍AMD深度学习开源堆栈
在介绍AMD深度学习堆栈的细节之前,让我们来看看开发工具背后的理念。AMD作为CPU和GPU的供应商,享有独一无二的地位,多年来一直在推广异构系统架构(HSA)的概念。与其他供应商的大多数开发工具不同,AMD的工具旨在支持其基于x86的CPU和GPU。AMD在HSA基金会(成立于2012年)共享HSA设计和成果,该基金会是一个非营利组织,其成员包括ARM,Qualcomm和Samsung等其他CPU供应商。
HSA基金会用一个图表,说明了HSA堆栈:
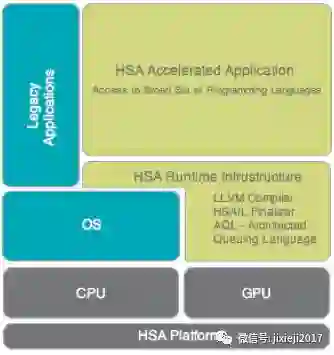
来源:HSA 基金会
如图所示所见,中间件(即HSA Runtime Infrastructure)在驻留在单个系统中的不同类型的计算设备之间提供了一个抽象层。人们可以将其视为允许在CPU和GPU上运行相同程序的虚拟机。
2015年11月,AMD宣布ROCm计划将支持高性能计算(HPC)工作负载,并为Nvidia的CUDA平台提供替代方案。该计划发布了一个开源的64位Linux驱动程序(称为ROCk内核驱动程序)和扩展(即非标准)HSA运行环境(称为ROCr Runtime)。ROCm还继承了之前HSA的创新,如AQL数据包、用户模式队列和环境切换。
ROCm还发布了一个名为异构计算编译器(HCC)的C / C ++编译器,旨在支持HPC应用程序。HCC基于开源的LLVM编译器基础设施项目(https://en.wikipedia.org/wiki/LLVM)。
还有许多使用LLVM的开源语言,包括Ada,C#,Delphi,Fortran,Haskell,Javabytecode,Julia,Lua,Objective-C,Python,R,Ruby,Rust和Swift。这个丰富的生态系统开启了ROCm平台上替代语言的可能性。一个令人瞩目的开发就是名为NUMBA的Python应用。
添加到编译器的是一个称为HC的API,它提供对同步,数据迁移和内存分配的附加控制。HCC支持其他并行编程API,为了避免混淆,不会在这篇文章中介绍。
HCC编译器基于HSA基础上工作。这样可以将CPU和GPU代码写入相同的源文件,并支持统一的CPU-GPU内存分配等功能。
为了进一步缩小差距,ROCm 项目创建了一个名为HIP的CUDA移植工具(让我们忽略缩写代表的意思)。HIP提供了扫描CUDA源代码并将其转换为相应的HIP源代码的工具。HIP源代码看起来类似于CUDA代码,但编译的HIP代码可以支持基于CUDA和AMD的GPU设备。
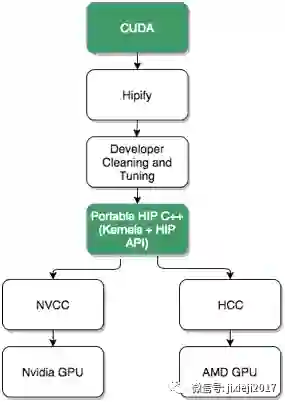
来源: AMD
AMD采用Caffe架构,拥有5.5万行优化的CUDA代码,并应用了HIP工具。55,000行代码中的99.6%由HIP自动翻译,其余部分代码由一个开发人员花了一个星期完成。一旦移植成功,HIP代码和原始的CUDA版本表现一直。
HIP并不是100%兼容CUDA,但它确实为开发人员提供了支持替代GPU平台的迁移路径。对于已经拥有大量CUDA代码库的开发人员来说,这是非常有帮助的。
今年年初,AMD宣布决定,将通过“闪电编译器计划(Lightning Compiler Initiative)”来“更接近金属”。该HCC编译器现在支持直接生成Radeon GPU指令集(称为GSN ISA)而不再是HSAIL。
我们将在后面看到,直接针对本地GPU的指令对于获得更高的性能至关重要。ROCm下的所有库都支持GSN ISA。
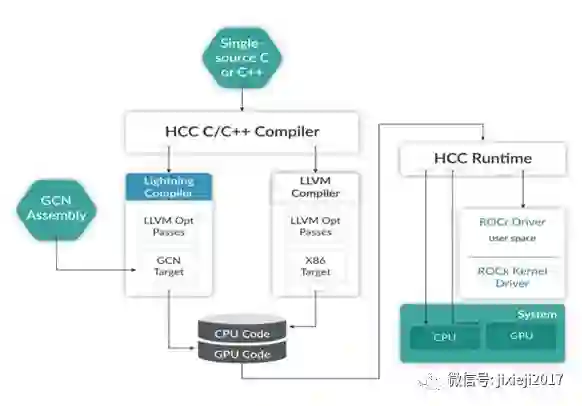
来源:AMD
该图描绘了ROCm组件之间的关系。HCC编译器生成CPU和GPU代码,使用不同的LLVM后端从单个C/ C ++源生成x86和GCN ISA代码。GSN ISA汇编器也可以用作GCN目标源。
CPU和GPU代码与HCC运行时链接以形成应用程序(与HSA图进行比较)。应用程序与驻留在Linux中的用户空间中的ROCr驱动程序进行通信。ROCr驱动程序使用低延迟机制(基于数据包的AQL)来与ROCk内核驱动程序协调。
这提出了高性能计算所需要的两个关键点:
1. 在设备的汇编语言级别执行工作的能力。
2. 高度优化库的可用性。
2015年,Peter Warden在《为什么GEMM是深度学习的核心?》(https://petewarden.com/2015/04/20/why-gemm-is-at-the-heart-of-deep-learning/)中谈到了关于优化矩阵库的重要性。BLAS(基本线性代数子程序)是人工优化库,可追溯到Fortran代码。Warden写道:
“科学程序员们,在Fortran世界花了几十年时间优化代码,来执行大规模矩阵到矩阵乘法,并且从常规的存储器访问模式中的获益,要大于存储成本的浪费。”
尽管我们在编译器技术方面取得了进展,但是对于内存访问的每个详细细节的关注却很难复制。在2017年,Warden在《为什么深度学习需要汇编黑客呢?》(https://petewarden.com/2017/01/03/why-deep-learning-needs-assembler-hackers/)中写道:
“我花了大量的时间来努力摆脱开发中硬件的性能。”
尽管是最近才出现的技术,但是深度学习的软件是一个复杂的堆栈。公认的最流行的深度学习框架(TensorFlow,Torch,Caffe等)都是开源的。然而,这些框架是建立在高度优化的内核上,但这些内核通常是不公开的。开发人员需要尽全力挤出他们硬件中每一点可用的性能。
例如,Nervana系统的Scott Gray不得不逆转Nvidia的指令集来创建汇编器(https://github.com/NervanaSystems/maxas/wiki/Introduction):
“我基本上得出结论,不可能充分利用Nvidia提供的工具来达到我所购买硬件的最优性能。不幸的是,Nvidia也不买自己工具的帐,他们手工组装自己的库例程,而不是像我们其他人一样使用Nvidia的ptxas。”
Gray使用汇编语言来编写他们自己的内核,从而创建最佳的专有替代方案的算法。现在想象如果汇编语言是可用的并记录在文档中,他可以少做多少工作。这也是AMD将要推出的。
ROCm计划提供手工库和汇编语言工具,这将使开发人员能够发挥AMD硬件中的每一微小性能。
这都是从头开始应用HIP接口实现的。AMD甚至提供了支持rocBLAS基准测试的工具(即Tensile,https://github.com/RadeonOpenCompute/Tensile/wiki)。AMD还提供了一个名为rocFFT的FFT库,它也是用HIP接口编写的。
深度学习算法将继续快速发展。
一开始,框架利用了可用的矩阵乘法库。这些精细调整的算法已经开发了几十年。随着研究的不断深入,还将有新的算法提出。
因此,需要超越通用矩阵乘法的算法。卷积网络的出现导致了更多的创新算法。今天,许多这类算法通过汇编语言手工实现。这些底层调整可以显著提高性能。对于某些操作(如批量归一化),与传统非优化解决方案相比,新算法性能提高了14倍。
AMD发布了一个名为MiOpen(https://rocmsoftwareplatform.github.io/MIOpen/doc/html/)的库,其中包括手工实现的深度学习优化。
该库包含了针对Radeon GPU特定的操作优化,也将可能包含上述描述的许多优化。MiOpencoin的发布恰逢Caffe版本释放。这将允许使用这些框架的应用程序代码在Radeon GPU硬件上更有竞争力。
Arxiv上几乎每天都会有新的算法论文发表,而许多最先进的方法还未进入专有的深度学习库。
任何供应商都难以跟上这样激动人心的步伐。在目前的情况下,鉴于开发工具缺乏透明度,开发人员不得不选择等待,尽管他们很希望能自己进行编码和优化。幸运的是,开源ROCm项目解决了这个问题。
▍部署
在本文中,我们讨论了ROCm软件栈的前景。到了ROCm大展身手的时候,我们需要讨论软件运行的硬件种类,部署深度学习在很多不同的场景下都是富有意义的。与通常的观点不同,并不是所有的东西都要部署在云端。无人车或通用翻译设备就需要在没有连接的情况下运行。
深度学习也有两种主要的操作模式 ——“训练”和“推理”。在训练模式下,您总希望拥有许多地球上最强最快的GPU。在推理模式下,您仍然希望能更快,但重点却转向经济功耗,我们不想看到通过支付昂贵的电力来开展业务。
总而言之,您需要在不同的情境下运行各种硬件。这就体现了AMD的优势。AMD最近宣布了一些令人非常印象深刻的硬件,专门面向深度学习的工作负载。

该产品称为Radeon Instinct,它由几个GPU芯片组成:MI6,MI8和MI25。编号数字大致对应于芯片的操作次数。MI6可以每秒执行大约6万亿次浮点运算(也称为teraflops)。
在嵌入式设备层面也有新的曙光。AMD已经支持Microsoft Xbox和Sony PlayStation的定制CPU-GPU芯片。AMD APU(即具有集成GPU的CPU)也可为具有较小外观的设备提供解决方案。
AMD战略的优点在于,开发者既可以将HSA的架构用于最小的服务器上,也可以部署到最快的服务器上。这种广泛的硬件产品允许深度学习的开发人员在部署他们的解决方案方面拥有丰富的灵活性。深度学习正以爆炸的速度发展,人们永远不能预测部署解决方案的最佳方式。
▍结论
像互联网和智能移动设备一样,深度学习是一种突破性的技术。开源软件已经成为支持这些技术的主要平台。
AMD将这些强大的原理与开源的ROCm计划相结合,这本身就具有加速深度学习发展的潜力。ROCm提供了一整套满足高性能计算需求的组件,例如提供更接近硬件的工具,包括手动编程库和对汇编语言工具的支持。
未来的深度学习软件将需要更多优化,涵盖多种计算核心。在我看来,AMD在异构系统架构中大量投资的战略眼光让他们的平台有了显著的优势。
AMD开源战略具有独特的地位,将打破未来深度学习的发展。
★推荐阅读★
长期招聘志愿者
加入「AI从业者社群」请备注个人信息
添加小鸡微信 liulailiuwang






