南京大学周志华教授:人工智能在做什么?

本文整理自南京大学周志华教授 9 月 12 日在南京举行的 2017 中国人工智能峰会(CAIS 2017)上进行的演讲记录。
一提到人工智能,很多媒体、社会大众可能首先想到的是科幻电影中的「人工智能」形象。所以从事人工智能研究的人经常要面对一个很难回答,或是说很悲哀的问题:比人类更聪明的人工智能什么时候能够出现?
这样的问题,对做人工智能研究的人来说其实非常难回答。为什么呢?因为谈到人工智能,有两种差别非常大的观点。第一种,我们称之为强人工智能,目的是希望研制出和人一样聪明,甚至比人更聪明的机器,这种观点在科幻作品和电影里面出现的比较多。另外一种叫做弱人工智能,是觉得人做事的时候很聪明,能不能向人学习一下,让机器做事的时候也聪明起来,在科学界研究者探索的主要是这个方面。
有一位非常知名的学者,Marvin Minsky,他是人工智能的奠基者之一,图灵奖得主,也是 MIT 的计算机科学方面的奠基人。他曾经给人工智能下过一个定义说,人工智能就是研究「让机器来完成那些如果由人来做则需要智能的事情」的科学。
一个简单的类比:在一百多年前,我们看到天上有鸟在飞,然后大家就想,那我们能不能做一个东西让它飞起来,后来经过空气动力学研究,我们有了飞机。但是如果我们问,飞机到底有没有比鸟飞得更好,这其实可能很难说。飞机可能比鸟飞得更高、更远,但是没有鸟飞得灵活。但不管怎么样,原来的目的已经达到了,我们获得了能够帮我们飞起来的工具。
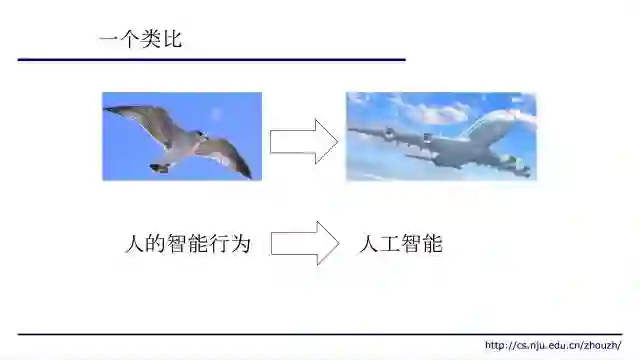
人工智能要做的事情和造飞机非常相似:我们看到人有很多行为很有智能性,我们希望通过借鉴这种智能性做出一些工具,帮助我们做更强大的事情。这就是我们在研究人工智能时考虑的主要内容。我们不是在做人造智能,而是人工智能,更确切地说,是一种受智能行为启发的计算过程(Intelligence-inspired Computing)。
我们简单地回顾一下过去几十年里人工智能学科发生了的事情。今天,我们一般认为人工智能这个学科诞生的话是在 1956 年。世界上第一个现代的计算机系统诞生于 1946 年,在 1956 年计算机的计算能力还非常弱,但是当时就有很多的学者在想:计算能力照此发展下去,我们就可以做一些更复杂的事情。那年夏天在达特茅斯学院开了一个会议,在这个会议上,后来被称为人工智能之父的 John McCarthy 为这个学科起了一个名字,叫做「人工智能」。由此今天我们都认为人工智能是 1956 年夏天诞生的。
在过去 60 多年的历史上,如果我们从主流的研究过程或者说研究者的工作重点来看,过去的发展大概经历了三个阶段。
第一个阶段从 50 年代中期到 60 年代,人工智能主要在做推理。这是为什么呢?因为当时人工智能的研究者很多是从数学、从计算机科学产生出来的,大家都对数学家有一种很自然的崇拜,认为数学家非常聪明,因为他们能够证明一些非常复杂的定理,这背后的能力就是逻辑推理能力。所以当时大家就想,如果能够把逻辑推理能力赋予计算机系统,那么这个机器做事情就会聪明起来,所以当时有很多很重要的研究结果,例如两位图灵奖得主 Herbert Simon 和 Allen Newel 做出来的自动定理证明系统 Logic Theorist。中国的吴文俊先生,他的研究成果也属于这一大类。那么这样的研究成果达到了一个什么样的水平?举个例子,大家都知道数学是自然科学工程科学的基础,但是数学的基础是什么呢?在上世纪 40 年代,有两位伟大的逻辑学家 Russell 和 Whitehead 他们用逻辑把整个数学系统建构起来,写了一本书叫做《数学原理》。为了证明这本书里面的定理,他们花了十年时间。然而程序证明这所有的定理只用了不到两个月的时间,而且机器证明出来的定理甚至有一条比这两位伟大的逻辑学家证明出来的还要巧妙。
在上世纪 60 年代,机器所具有的推理能力就已经达到了人类的巅峰水平,但是机器在做事情这方面还远没有人类一样聪明。大家逐渐意识到,只有逻辑推理能力是不够的。数学家能够证明很多定理,不光是因为强大的推理能力,还因为有很多数学知识,所以人工智能的研究很自然地就进入了第二个阶段。在这个阶段大家思考的是能不能把知识总结出来交给计算机系统。这就是所谓的知识工程期,代表人物就是后来的图灵奖得主,被称为知识工程之父的 Edward Feigenbaum,曾任美国空军的首席科学家。在这个阶段,大家主要希望把人类专家解决问题的知识总结出来,比如说在做探矿系统时,如果看到岩石渗出红色,那么里面很可能是铁矿。把这样的知识总结出来,然后编程,放到计算机系统里,由此产生了很多的专家系统,解决了很多问题。
但是后来研究者发现,把知识总结出来交给系统是非常困难的。一方面,有时候我们人类能够解决一些问题却无法说清里面的知识是什么。还有一种情况,人类专家可能不太愿意分享他的知识。这该怎么办?因为人的知识主要是靠学来的,所以很多人自然地想到,我们能不能让机器自动的去学知识?所以从 20 世纪 90 年代开始,人工智能的主流研究就进入到第三个阶段,这个阶段一直持续到今天,就是「机器学习阶段」。因此,机器学习学科是为了解决知识获取瓶颈而出现的。机器学习的经典定义是,利用经验来改善系统自身的性能。但是不管什么样的经验,想要放在计算机系统中,必然是以数据的形式存在的。所以,机器学习想要研究如何利用经验就必须要对数据进行分析。因此这个领域发展到今天,主要研究的是如何利用计算机对数据进行分析的理论和方法,或者称为智能数据分析的理论和方法。这个领域特别的重要。举一个例子,图灵奖是计算机科学的最高奖,10 年和 11 年,图灵奖连续两年颁给了在机器学习方面做出杰出贡献的学者,这个在图灵奖历史是非常罕见的,直接体现出大家对这个领域的重视。
机器学习走上历史舞台是因为要解决知识获取的瓶颈。但是恰恰在 20 世纪末,人类开始发现,自己淹没在数据的海洋里面,我们急需技术对数据分析,而机器学习恰恰在这个时候出现了,我们对它的需求十分高涨。今天,大家都知道我们处于一个大数据时代,觉得拿到大数据就好像得到了很多宝物。但其实这只是一方面,大数据好比一座矿山,拥有了矿山之后,想要得到里面的价值,必须要有很强大的数据分析技术,而今天的数据分析主要靠机器学习。因此在大数据时代,要让数据发挥作用,就离不开机器学习技术。所以如今机器学习技术已经无所不在,不管是互联网搜索还是人脸识别、自动驾驶、火星机器人、美国总统大选甚至军队用的战场数据情况分析……只要你有数据、希望用计算机来辅助数据分析,就能使用机器学习技术。因此,我们可以说,今天人工智能的热潮正是因为机器学习,尤其是其中深度学习技术取得的巨大的发展,发挥了巨大的作用。
我们经常会听到「人工智能、机器学习、深度学习」这几个词,它们是什么关系呢?深度学习是机器学习的一个分支,而机器学习又是人工智能的一个核心研究领域。虽然深度学习可以解决很多问题,有很多公司基于深度学习技术创立,我们也要注意到其实深度学习并不能够「包打天下」,还有很多的机器学习技术在很多方面在发挥作用。机器学习是一个非常广袤的学科领域,其分支随着数据分析的需求不断涌现、增长而指数级地膨胀。深度学习只是其中的一个小分支。
下面我想谈一谈我关于机器学习下一步发展的一些思考。对于熟悉机器学习的人来说,谈到机器学习,有些人想到的是算法,有些人想到的是数据。可以说,今天的机器学习就是以「算法加数据」的形态存在的。在这种形态下,存在哪些技术局限?
首先,我们需要大量的训练样本。大数据时代,是不是大量的训练样本这件事就不再是问题?其实还是一个很大的问题。第一种情况,在有些应用里样本总量很少,例如做油田定位的时候,数据必须通过人工诱发地震才能获得,因此获得这样的数据成本非常高,不可能有大量数据去用。第二种情况,数据很多,但其中我们真正关心的很少。例如,做银行欺诈检测时,一个银行每天的信用卡交易数据可能有百万甚至千万条,但是其中真正的信用卡欺诈数据可能很少。还有一种情况,数据的总量很多,但是已知结果的数据很少。比如,要做软件缺陷检测的时候,虽然有大量的程序代码,但是真正把缺陷标记出来的数据是非常少的。所以,即使在大数据时代,我们仍然希望能用少量的数据就做出很好的模型。
第二,做出一个机器学习模型后,环境如果稍微发生变化,就可能导致模型失效,或者是性能大幅度降低。比如说,我们布置了 100 个传感器,一个月之后有 60 个传感器失效了,这时候我新部署 60 个传感器,原来的模型能不能用呢?很抱歉,这时候模型的性能会大幅度衰减,因为人很难把新的传感器放到原来的位置,传感器发出的信号质量和信号强度也会有很大的变化,模型很难适应。
第三,今天的机器学习系统绝大多数都是黑箱。我们能做出预测,甚至是非常精确的预测,但是我们很难解释为什么做出这样的预测。这就会导致这样的模型很难用于一些高风险应用场景中。比如,我们要做地震预报,预测今天明天要地震,请大家撤离。领导肯定会问,你为什么做出这样的决策?如果这个模型是黑箱,它就只能告诉你,结果肯定是这样,至于理由是什么,我也不知道。这种情况下,是肯定不能够采纳这个建议的。
最后,其实还有很多别的问题,比如说,即使有同样的数据,普通用户能得到的结果和专家能得到的结果差别会非常大。再比如数据隐私问题,现在大医院有很多的病例,基于这些数据能够做出非常好的诊断系统,同时社区医院的病历数据可能比较少,直接基于它的数据很难做出好的模型。社区医院想获得帮助,大医院也乐于帮忙,但是这很难完成。因为一旦要分享病例数据,就会涉及到数据隐私、所有权等等问题。存在一面数据保护的墙,阻止我们有效地分享机器学习经验。
机器学习技术在当下还面临着很多其它问题,我列举出来的只是一部分。今天,科研人员都在各个方面做努力的探索,但是如果把所有这些方面割裂,逐个去解决,就很难摆脱「头疼医头脚疼医脚」的现状。所以,有没有可能在一个整体性的框架之下全面的考虑所有这些问题?
最近,我们提出了一个新的想法,我们称其为「学件」。现在计算机有硬件,有软件,我们希望经过若干年的探索之后,机器学习会产生出一种叫做「学件」的产物。
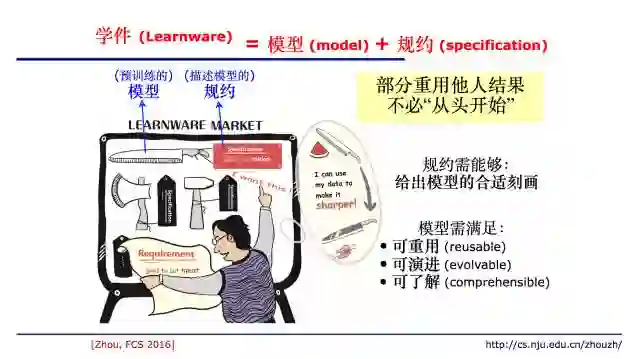
现在,已经有很多人做出自己的机器学习应用,也很愿意分享他们的模型。我们可以把这些模型做出来,放在一个地方。以后,一个新的用户想做自己的应用时,不再需要从头开始,只需要去这个市场上看一看有没有什么东西直接可以使用。比如说用户希望有一把切肉的刀,他绝对不会自己去采矿、去打铁,而是去市场上先看一看能不能买到这样的刀。就算买不到切肉刀,假设找到一把西瓜刀,拿回家用自己的数据打磨一下,可能就变成很适用的一个工具。这里的基本想法是,希望我们能够部分重用他人的结果,不再需要从头开始。
为了达到这个目的,「学件」应由两部分组成,一部分是模型,一部分是用于描述模型的规约(specification)。为了做到这件事情,模型需要有三个重要的特征,规约也需要达到他自己的性能。如果学件真正变成一个现实的话,可能刚才提到的这些问题都可以得到全面的解决。比如说,因为它本身是可以演进的,所以自己能适应环境;它本身有规约,不再是黑箱;用户可以把别人的模型作为基础,更容易得到专家级的性能。分享的是模型而不是分享数据,就避免了数据隐私和数据保护之类的问题。因此,如果学件能成为现实,可以有很多模型放在这个市场里,模型被更多的人用、用得更好,就可以有更高的定价。这样甚至有可能产生出一个新的产业。我们期望,经过十到十五年的探索以后,也许机器学习可以从「算法加数据」的形态过渡到「学件」的形态。
来源:机器之心,如有侵权请联系小编删除。
📚往期文章推荐

🔗起底中美252家独角兽公司,估值合计8795亿美元【附报告】
🔗著名植物学家、复旦大学研究生院院长钟扬教授不幸车祸去世 年仅53岁
🔗人工智能名人堂第46期 | 机器学习泰斗:弗拉基米尔·万普尼克
🔗周末观影 | 《猩球崛起3》,崛起的不是猩猩,而是人工智能!
🔗他是哈佛大学高材生,为了摧毁现代工业体系向大学教授邮寄炸弹
德先生公众号 | 往期精选
在公众号会话位置回复以下关键词,查看德先生往期文章!
人工智能|机器崛起|区块链|名人堂
虚拟现实|无人驾驶|智能制造|无人机
科研创新|网络安全|数据时代|人机大战
……
更多精彩文章正在赶来,敬请期待!



点击“阅读原文”,移步求知书店,可查阅选购德先生推荐书籍。





