业界 | Tensor Core究竟有多快?全面对比英伟达Tesla V100/P100的RNN加速能力
选自xcelerit
机器之心编译
参与:蒋思源
RNN 是处理量化金融、风险管理等时序数据的主要深度学习模型,但这种模型用 GPU 加速的效果并不好。本文使用 RNN 与 LSTM 基于 TensorFlow 对比了英伟达 Tesla P100(Pascal)和 V100(Volta)GPU 的加速性能,且结果表明训练和推断过程的加速效果并没有我们预期的那么好。

循环神经网络(RNN)
很多深度学习的应用都涉及到使用时序数据作为输入。例如随时间变化的股价可以作为交易预测算法、收益预测算法的输入而对未来某个时间点的可能状态进行推断。循环神经网络(RNN)非常是适合于建模长期或短期的时间依赖项,因此是本文测试的理想模型。
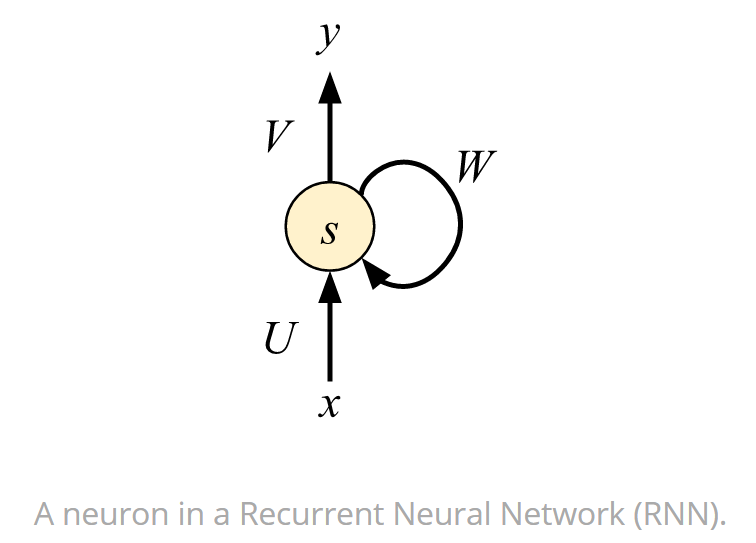
下图展示了 RNN 中的一个神经元,它不仅是最基础的组成部分,同时还是其它更复杂循环单元的基础。下图可以看出该神经元的输出 y 不仅取决于当前的输入 x,同时还取决于储存的前面状态 W,前面循环的状态也可以称之为反馈循环。正是这种循环,RNN 能够学习到时序相关的依赖性。
如下图所示,RNN 单元可以组织成一个个层级,然后再堆叠这些层级以组织成一个完整的神经网络。
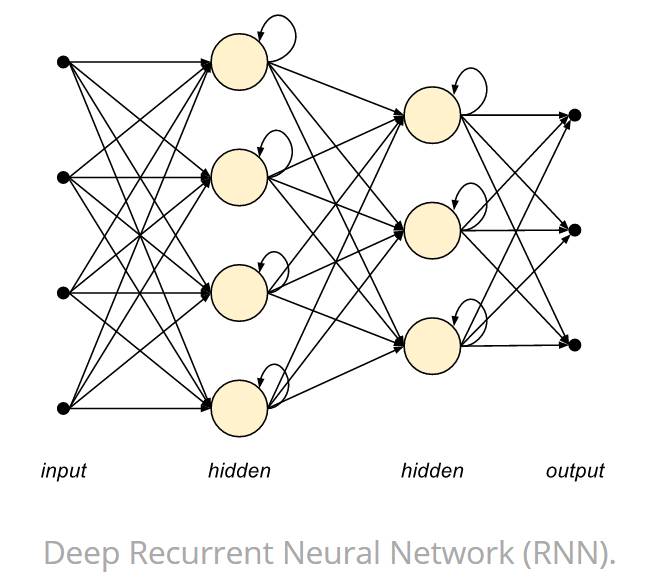
深度循环神经网络
由于梯度消失和爆炸问题,RNN 很难学习到长期依赖关系。这两个问题主要发生在训练时期的反向传播过程中,其中损失函数的梯度由输出向输入反向地计算。由于反馈循环,较小的梯度可能快速消失,较大的梯度可能急剧增加。
梯度消失问题阻止了 RNN 学习长期时间依赖关系,而长短期记忆模型(LSTM)正是 RNN 的一种变体以解决该问题。LSTM 引入了输入门、遗忘门、输入调制门和记忆单元。这允许 LSTM 在输入数据中学习高度复杂的长期依赖关系,因此也十分适用于学习时序数据。此外,LSTM 也可以堆叠多层网络形成更复杂的深度神经网络。
在假定隐藏层具有相同的宽度下,深度 RNN 网络的计算复杂度与采用的层级数成线性缩放关系。因此,单层 RNN 或 LSTM 单元就可以看作是深度 RNN 中的基础构建块,这也就是为什么我们要选择下面这样的层级进行基础测试。
硬件对比
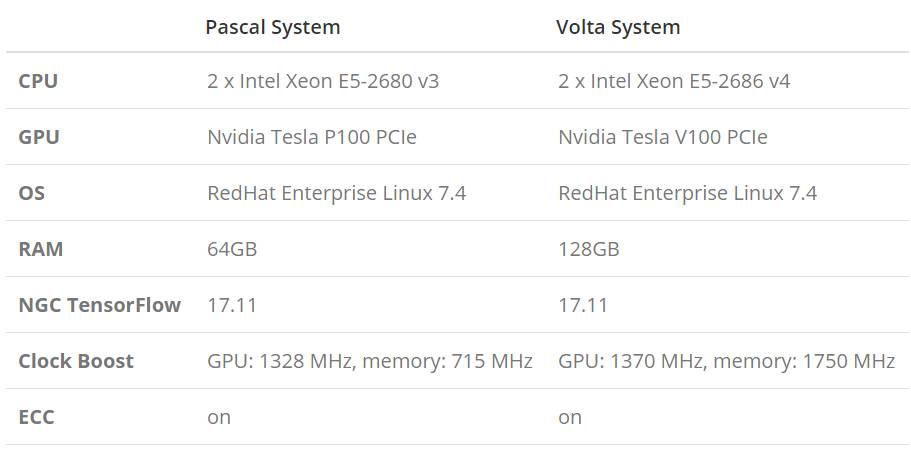
下表展示了英伟达 P100 和 V100 GPU 的关键性能与不同点。

请注意 FLOPs 的计算先假定纯粹的加乘混合(fused multiply-add /FMA)运算指令记为两个运算,即使它们都只映射到一个处理器指令中。
在 P100 上,我们测试的是半精度(FP16)FLOPs。而在 V100 上,我们测试的是张量 FLOPs,它以混合精度的方式在 Tensor Cores 上运行:以 FP16 的精度执行矩阵乘法,而以 FP32 的精度进行累加。
也许 V100 GPU 在深度学习环境下最有意思的硬件特征就是 Tensor Cores,它是能以半精度的方式计算 4×4 矩阵乘法的特定内核,并在一个时钟周期内将计算结果累加到单精度(或半精度)4×4 矩阵中。这意味着一个 Tensor Cores 在每个时钟周期内可以执行 128 FLOPs,并且带有 8 个 Tensor Cores 的 Streaming Multiprocessor 能实现 1024 FLOPs/cycle 的速度。这比常规单精度 CUDA 核要快 8 倍。为了从这种定制化的硬件中获益,深度学习模型应该以混合精度(半精度与单精度)或纯粹以半精度的方式编写,因此才能利用深度学习框架高效地使用 V100Tensor Cores。
TensorFlow
TensorFlow 是一个谷歌维护的开源深度学习框架,它使用数据流图进行数值计算。TensorFlow 中的 Tensor 代表传递的数据为张量(多维数组),Flow 代表使用计算图进行运算。数据流图用「结点」(nodes)和「边」(edges)组成的有向图来描述数学运算。「结点」一般用来表示施加的数学操作,但也可以表示数据输入的起点和输出的终点,或者是读取/写入持久变量(persistent variable)的终点。边表示结点之间的输入/输出关系。这些数据边可以传送维度可动态调整的多维数据数组,即张量(tensor)。
TensorFlow 允许我们将模型部署到台式电脑、服务器或移动设备上,并调用这些设备上的单个或多个 CPU 与 GPU。开发者一般使用 Python 编写模型和训练所需的算法,而 TensorFlow 会将这些算法或模型映射到一个计算图,并使用 C++、CUDA 或 OpenCL 实现图中每一个结点的计算。
从今年 11 月份发布的 TensorFlow 1.4 开始,它就已经添加了对半精度(FP16)这种数据类型的支持,GPU 后端也已经为半精度或混合精度的矩阵运算配置了 V100 Tensor Cores。除了 1.4 这个主线版本外,英伟达还在他们的 GPU Cloud Docker 注册表以 Docker 容器的形式维护了一个定制化和优化后的版本。这个容器目前最新版为 17.11,为了实现更好的性能,我们将使用这个 HGC 容器作为我们的测试基准。
基准测试
我们的基准性能测试使用含有多个神经元的单隐藏层网络架构,其中隐藏层的单元为分别为原版 RNN(使用 TensorFlow 中的 BasicRNNCell)和 LSTM(使用 TensorFlow 中的 BasicLSTMCell)。网络的所有权重会先执行随机初始化,且输入序列因为基准测试的原因而采取随机生成的方式。
我们比较了模型在 Pascal 和 VoltaGPU 上的性能,且系统所使用的配置如下所示:
性能
为了度量性能,我们需要重复执行模型的训练,然后再记录每次运行的时钟长度,直到估计的时间误差低于特定值才停止。性能度量包括完整的算法执行时间(使用梯度下降的时间加上推断的时间),训练的输入为批量大小为 128 的 10 万批数据,且每一个序列长度为 32 个样本。训练过程大概有 1300 万的训练样本,且我们使用重叠的窗口进行序列分析。一个深度学习模型大概会依据 32 个以前样本的状态而预测未来的输出,因此我们修正隐藏层中 RNN/LSTM 单元的数量以执行基线测试。
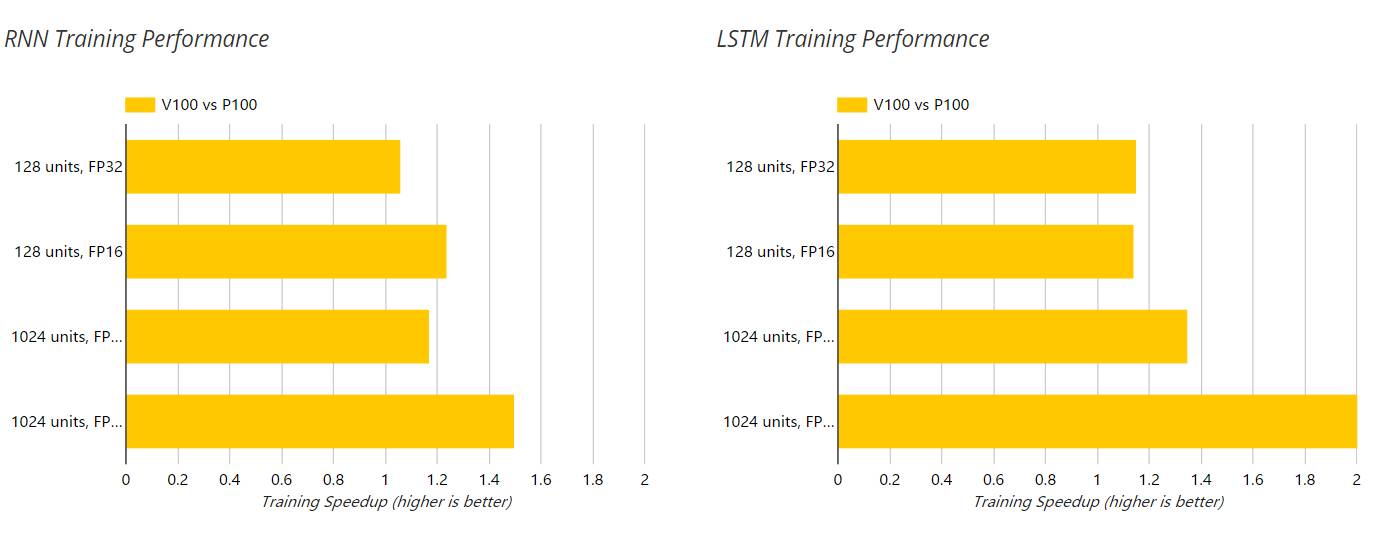
训练
以下两图展示了 V100 和 P100 GPU 在训练过程中对 RNN 和 LSTM 的加速,这个过程的单精度(FP32)和半精度(FP16)运算都是使用的 NGC 容器。此外,隐藏层单元数也在以下图表中展示了出来。
推断
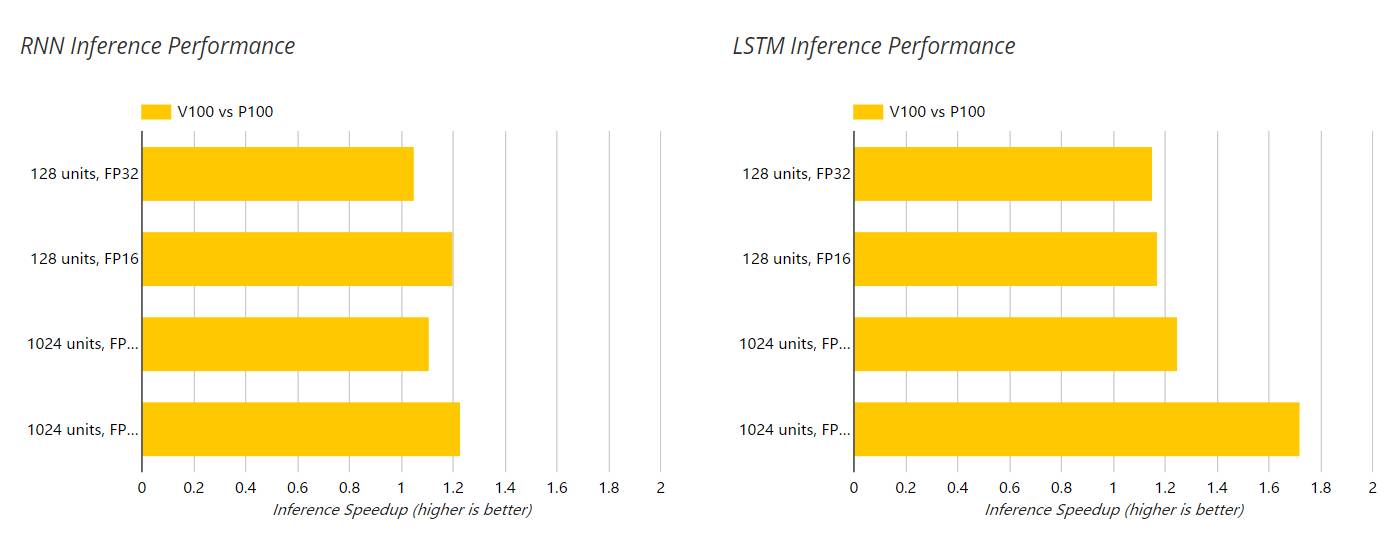
以下两图展示了 V100 和 P100 GPU 在推断过程中对 RNN 和 LSTM 的加速,这个过程的单精度(FP32)和半精度(FP16)运算都是使用的 NGC 容器。此外,隐藏层单元数也在以下图表中展示了出来。
结语
对于测试过的 RNN 和 LSTM 深度学习模型,我们注意到 V100 比 P100 的相对性能随着网络的规模和复杂度(128 个隐藏单元到 1024 个隐藏单元)的提升而增加。我们的结果表明 V100 相对于 P100 在 FP16 的训练模式下最大加速比为 2.05 倍,而推断模式下实现了 1.72 倍的加速。这些数据比基于 V100 具体硬件规格的预期性能要低很多。
这一令人失望的性能比可能是因为 V100 中强大的 Tensor Cores 只能用于半精度(FP16)或混合精度的矩阵乘法运算。而对这两个模型进行分析的结果表示矩阵乘法仅占 LSTM 总体训练时间的 20%,所占 RNN 总体训练时间则更低。这与擅长于处理图像数据的卷积神经网络形成鲜明对比,它们的运行时间由大量的矩阵乘法支配,因此能更加充分地利用 Tensor Cores 的计算资源。
虽然 V100 与 P100 相比显示出强大的硬件性能提升,但深度学习中擅于处理时序数据的循环神经网络无法充分利用 V100 这种专门化地硬件加速,因此它只能获得有限的性能提升。

原文地址:https://www.xcelerit.com/computing-benchmarks/insights/benchmarks-deep-learning-nvidia-p100-vs-v100-gpu/
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com




