殊途同归的策略梯度与零阶优化

©PaperWeekly 原创 · 作者|苏剑林
单位|追一科技
研究方向|NLP、神经网络


形式描述
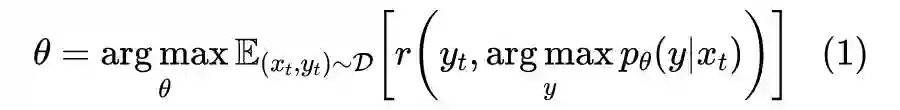

策略梯度
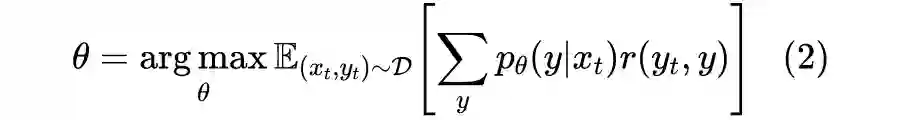
2.1 排序不等式
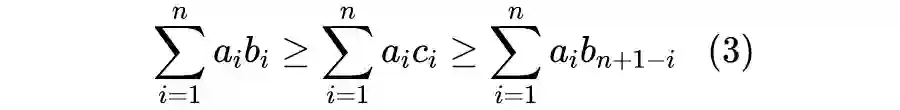
也就是说“同序积和 ≥ 乱序积和 ≥ 倒序积和”。
2.2 采样估计梯度
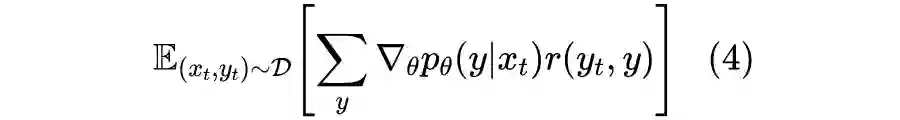
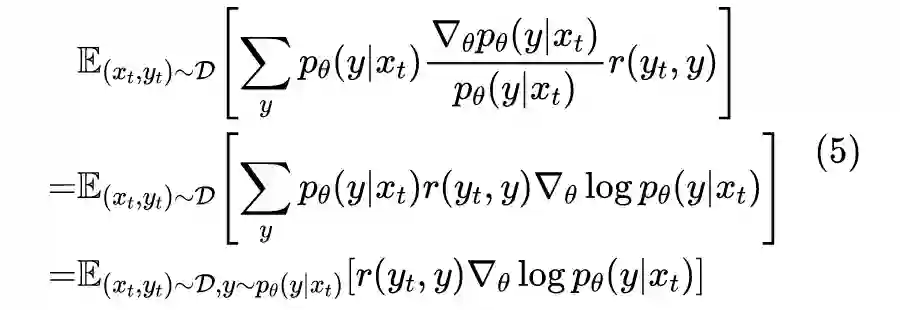
2.3 降低方差
如果我们只从中采样一个样本,那么前者与目标的最大误差也不过是 1,后者最大误差能达到 15,最小误差都有 5,所以虽然理论上最终的均值都是一样的,但是前者的估算效率要远远高于后者(采样更少的样本,得到更高的估算精度)。
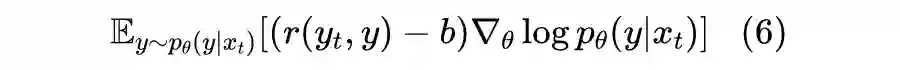
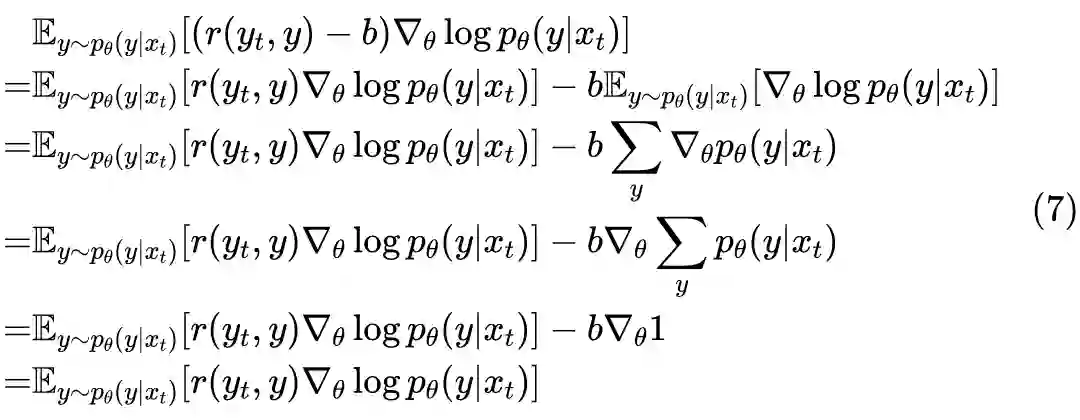
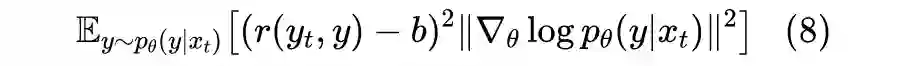
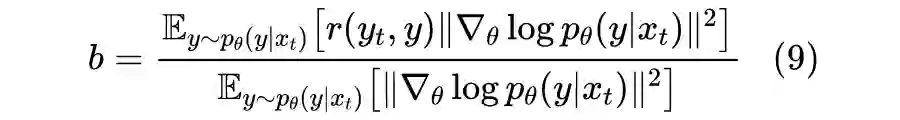
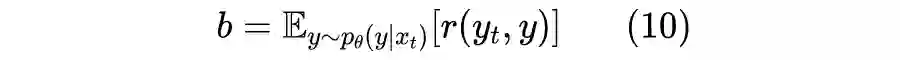
2.4 一言以蔽之

零阶优化泛指所有不需要梯度信息的优化方法,而一般情况下它指的是基于参数采样和差分思想来估计参数更新方向的优化算法。
从形式上来看,它是直接在参数空间中进行随机采样,不依赖于任何形式的梯度,因此理论上能求解的目标是相当广泛的;不过也正因为它直接在参数空间中进行采样,只是相当于一种更加智能的网格搜索,因此面对高维参数空间时(比如深度学习场景),它的优化效率会相当低,因此使用场景会很受限。
3.1 零阶梯度
零阶优化不需要我们通常意义下所求的梯度,但是它定义了一个基于采样和差分的“替代品”,我们暂且称为“零阶梯度”:
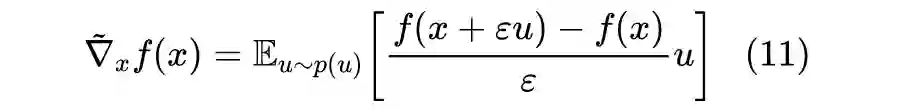
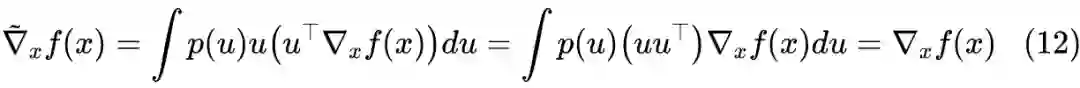
3.2 也有basline
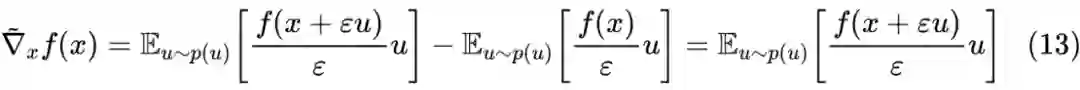
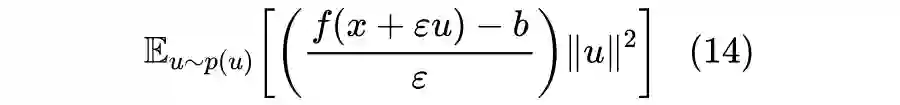
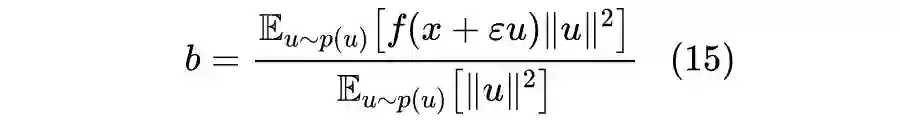
3.3 一言以蔽之
对于直接在高维空间中应用零阶优化方法,也有一定的研究工作(比如Gradientless Descent: High-Dimensional Zeroth-Order Optimization [2] ),但还不算很成功。

貌离神合
看上去,策略梯度和零阶优化确实有很多相似之处,比如大家都是需要随机采样来估计梯度,大家都需要想办法降低方差,等等。当然,不相似之处也能列举出不少,比如策略梯度是要对策略空间采样,而零阶优化则是对参数空间采样;又比如策略梯度本质上还是基于梯度的,而零阶优化理论上完全不需要梯度。
4.1 划分全空间
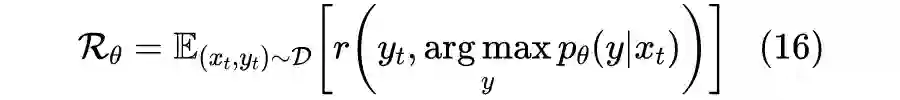
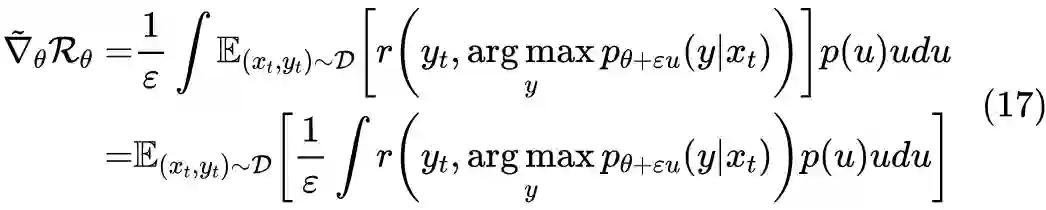
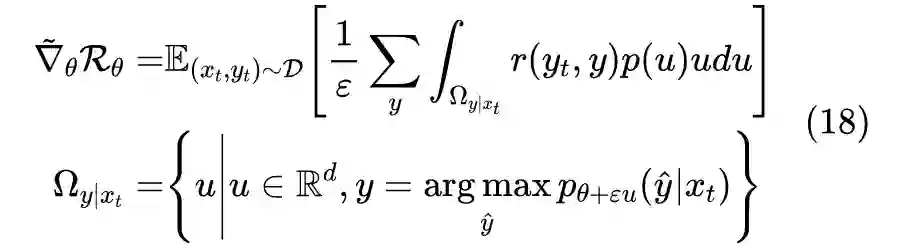
4.2 示性函数
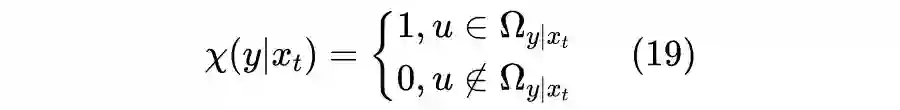
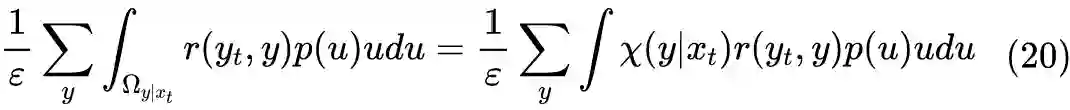
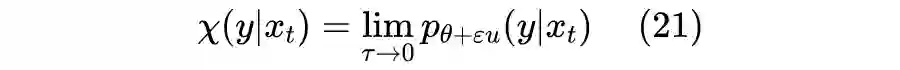
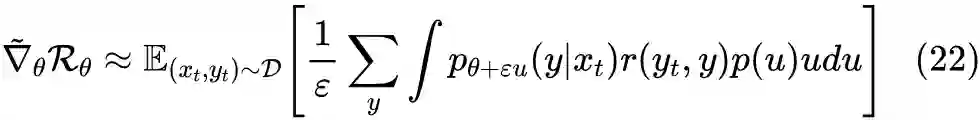
4.3 近似求积分
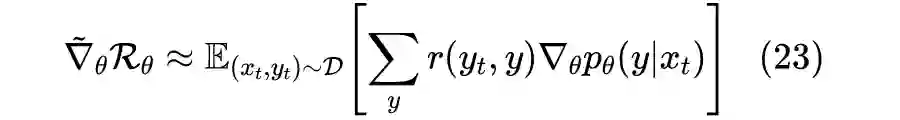
对比式(4)可以发现,上式右端正是策略梯度。
所以,看起来差异蛮大的零阶梯度,最终指向的方向实际上跟策略梯度是相近的,真可谓貌离神合、殊途同归了,有种“正确的答案只有一个”的感觉。这不禁让笔者想起了列夫·托尔斯泰的名言:
幸福的家庭都是相似的,不幸的家庭各有各的不幸。

文末小结
本文主要介绍了处理不可导的优化目标的两种方案:策略梯度和零阶优化,它们分别是从两个不同的角度来定义新的“梯度”来作为参数的更新方向。

参考文献
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。




