专栏 | 阿里SIGIR 2017论文:GAN在信息检索领域的应用
选自 Alibaba Group
机器之心报道
信息检索领域的顶级会议 SIGIR 2017 即将开幕。昨日,机器之心报道了阿里被 SIGIR 2017 接收的一篇论文,据了解阿里共有 3 篇论文被此大会接收。本文介绍了另一篇由英国伦敦大学、上海交大、阿里等合著的论文。

论文链接:https://arxiv.org/pdf/1705.10513.pdf
Information Retrieval(IR)的典型问题是给出一些查询词(query),返回一个排序的文档列表(documents),但 IR 的应用范围可以扩展到文档检索、网页搜索、推荐系统、QA 问答系统和个性化广告等等。在 IR 的理论或模型领域,有两种典型的思维方式(如图所示):

生成式 IR 模型:第一种思想认为 documents 和 query 之间有一个隐含的随机生成(generative)过程,可以表示成:q→d,其中 q 表示 query,d 表示 document,箭头表示生成的方向,生成模型对 p(d|q) 进行建模。
判别式 IR 模型:第二种思想采用了机器学习的方法,将 IR 的问题转化成一个判别(discriminative)问题;可以表示成:q+d →r,其中+表示 query 和 document 的特征的组合,r 表示相关性,如果 r 为 0 或 1,则问题是一个分类问题,如果 r 是一个相关分数,则问题是一个回归问题;现在著名的方法就是排序学习(Learning to Rank)。排序学习可以分为 Pointwise、Pairwise 和 Listwise 三种模型。
虽然 IR 的生成模型在 Query 和 Document 的特征建模(例如文本统计)的方面非常成功,但它在利用来自其他的相关性信息(如链接,点击等等)方面遇到了很大的困难,而这些信息主要可以在现在互联网的应用中观察得到。于此同时,虽然诸如排序学习的 IR 判别模型能够从大量的标记和未标记的数据中隐式地学习检索排序函数,但是它目前缺乏从大量未标记数据中获取有用特征或收集有用信号的原则性方法,特别是从文本统计(源自 Document 和 Query 两方面)或从集合内相关文档的分布中。
应用 GAN 的思想,IRGAN 引入博弈论中的 minmax 博弈,来将生成式 IR 模型和判别式 IR 模型进行结合。具体来说,我们为两个模型定义一个共同的检索函数(例如基于判别的目标函数)。一方面,判别模型 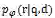
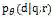
下面具体地介绍 IRGAN 的方法,会分别介绍 GAN 中对应的 Discriminator(D)和 Generator(G)。
1. Discriminator: 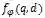
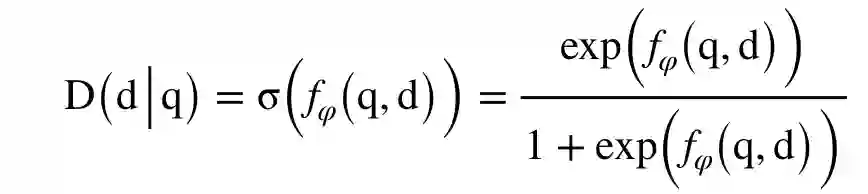
与原始的 GAN 相同,D 的,目标是最大化:
2. Generator: 
G 的目标是最小化:
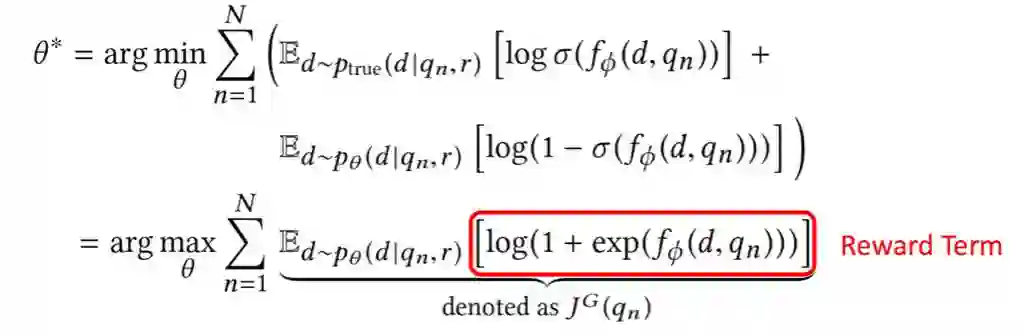
对 IRGAN 的 training 部分,G 和 D 交叉进行更新。对于 D,可以采用梯度下降更新法;对于 G,由于 G 的输出是离散 documents 的概率分布,没办法直接采用梯度下降的方法求 G 的梯度,针对这种使用 GAN 训练离散数据的问题,可以采用强化学习中 Policy Gradient 的方法,reward 由 D 给出。整个训练过程如下图算法所示:

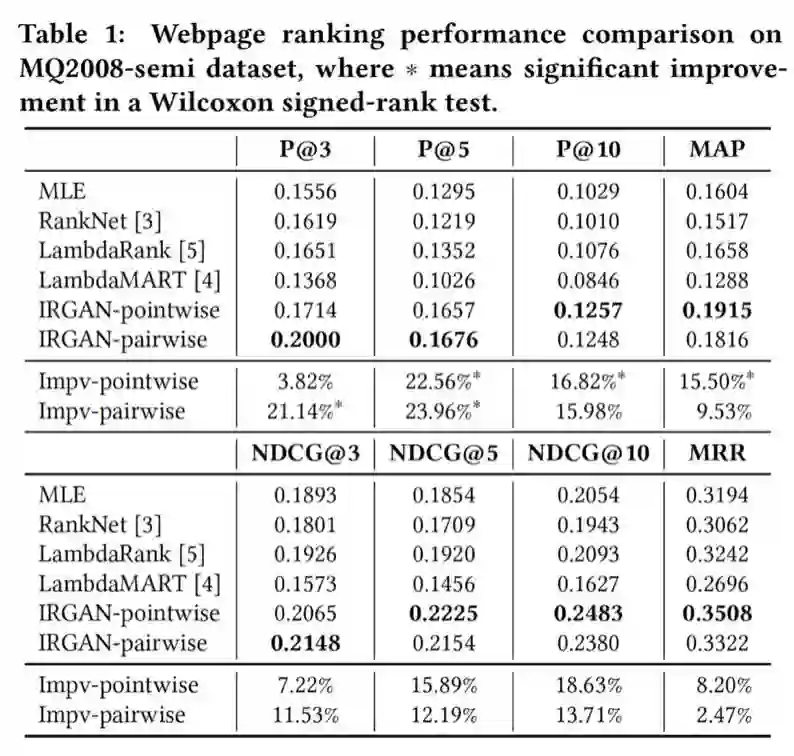
在实验部分,做了三个不同的 IR 任务:Web Search,Item Recommendation 和 Question Answering,实验结果表明,IRGAN 模型打败了多种 strong baseline。开源代码在:https://github.com/geek-ai/irgan。
阿里巴巴 SIGIR 2017 论文解读专栏:
本文为机器之心报道,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com




