【领域报告】行人再识别年度进展 |VALSE2018之十
编者按:杜甫在《江南逢李龟年》中曾写道:
“正是江南好风景,落花时节又逢君。”
讲的是杜甫与李龟年在江南重逢的场景,其实在计算机视觉领域,在跨摄像头跟踪等场景下,也时常面临着重逢,如果与某一目标重逢时无法准确地识别出其身份,将极大地影响整个系统的跟踪性能。因此,学术界衍生出了行人再识别这一研究方向。
本文中,来自浙江大学的李玺教授,将为大家介绍过去一年中,行人再识别领域所取得的研究进展。
文末提供文中提到参考文献的下载链接。

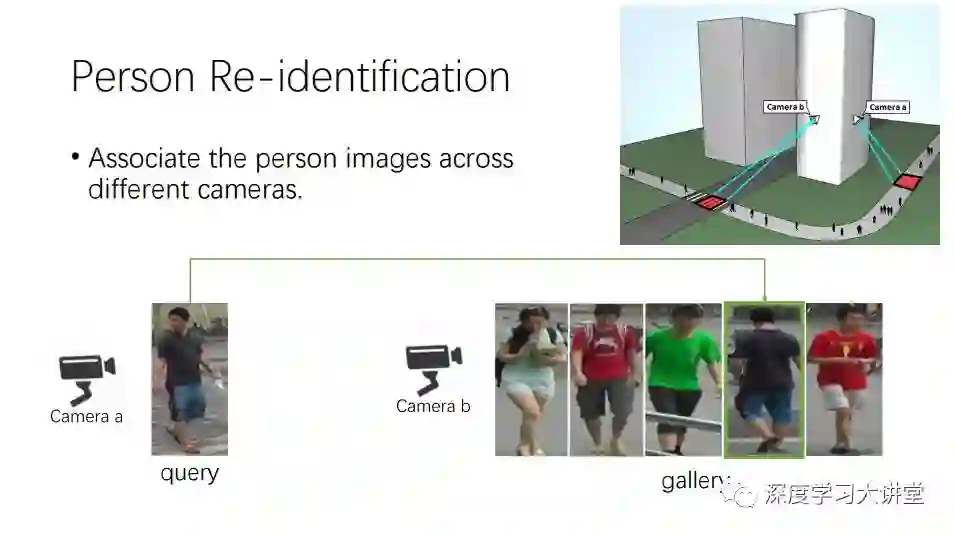
Person ReID(Person Re-identification)解决的问题是在有多个摄像头的情况下,如何快速识别一个人的ID。这是学术界和工业界都非常关注的问题,也是一个具有挑战性的问题。
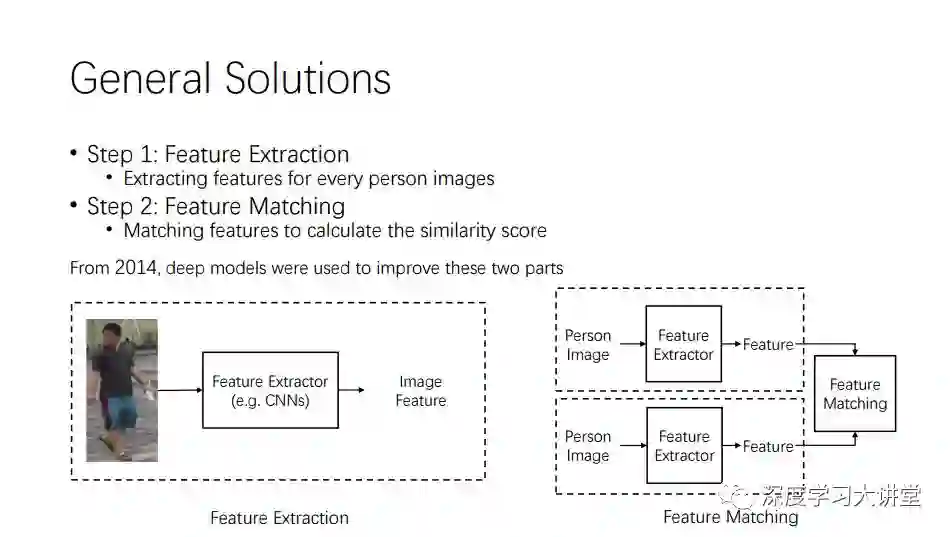
这个过程的关键是如何识别和匹配两个人的特征信息和语义结构特点。这个过程主要分为两个步骤。第一个步骤是特征提取,主流方法是CNN。

第二个步骤是特征Matching,核心方法有两种:一种是基于预先定义的位置,例如gloabl,local stripes和grid patches,是比较启发式的;另一种是基于semantic region,借助Person parts, salient regions和attention regions,具有一定的语义含义。

下面从四个比较重要的领域,stripes方法,grids方法,attention方法以及pose方法来回顾一下ReID的进展。

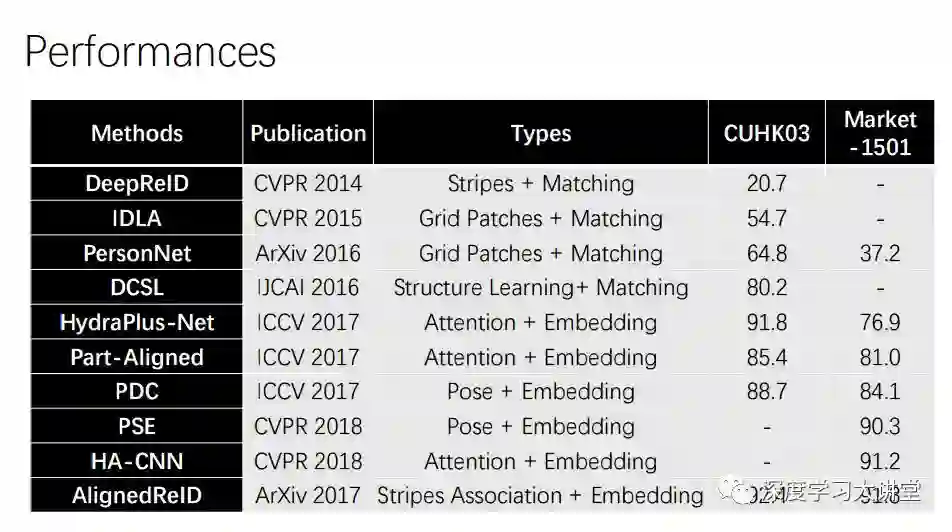
Stripes角度主要有三个方面的工作:DeepMetric,DeepReID和AlignedReID。
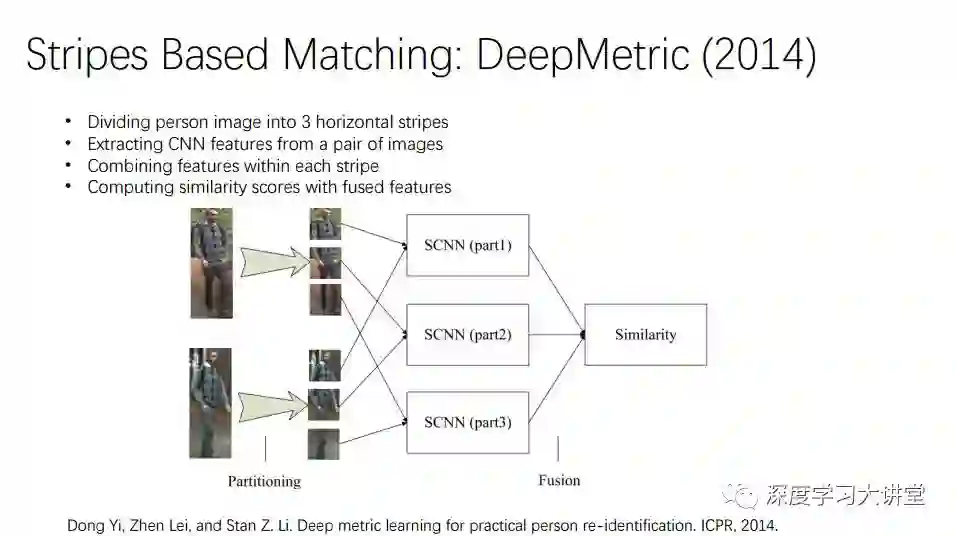
DeepMetric把一幅图片强行分成三大块,每一大块做一个SCNN,再将各个部分整合。想法非常简单,实际应用过程中相对有效。
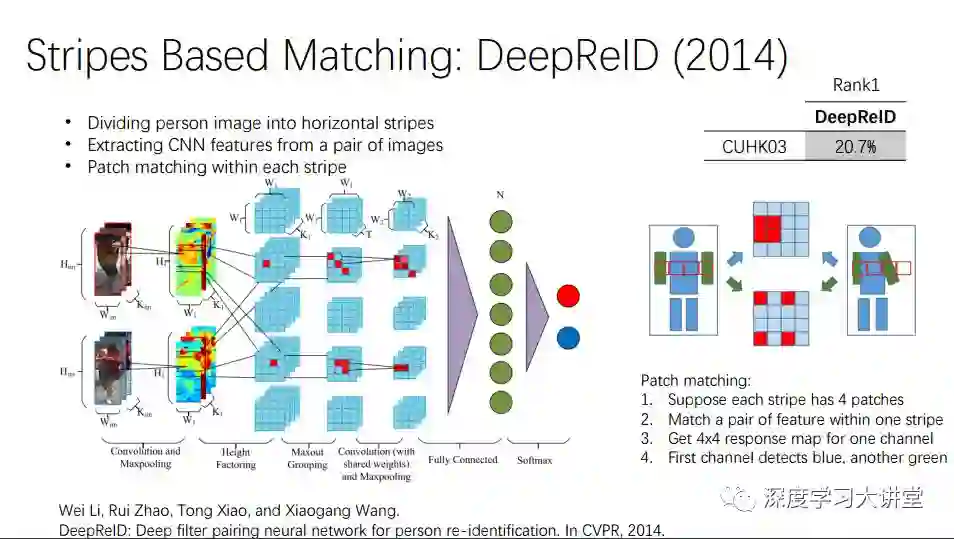
DeepReID更复杂,相当于把一个人的结构分成很多小块,每一个小块进行操作。这个方法比较直接,更加细致。缺陷是在识别较为复杂的情况时,或者任何人之间特征区分较差时会受到噪音干扰。
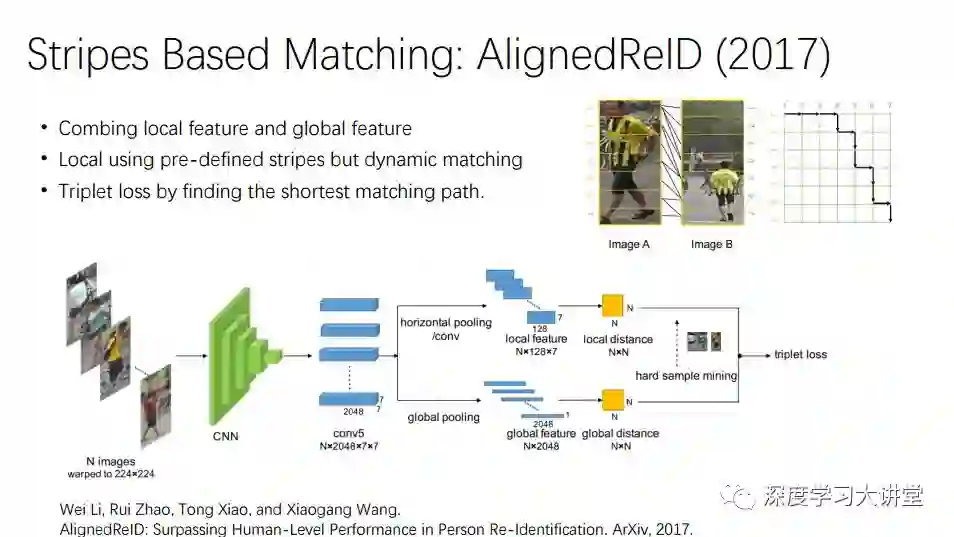
Stripes效果最好的是王老师的工作AlignedReID,他们通过动态规划计算距离,需要动态匹配的过程,比较复杂,但效果不错。过程分为两个部分,一个是水平的pooling,一个是global pooling,再将两部分融合,得到local distance和global distance,再加入hard sample mining。

第二种思路是基于网格的方法,主要有两个工作。
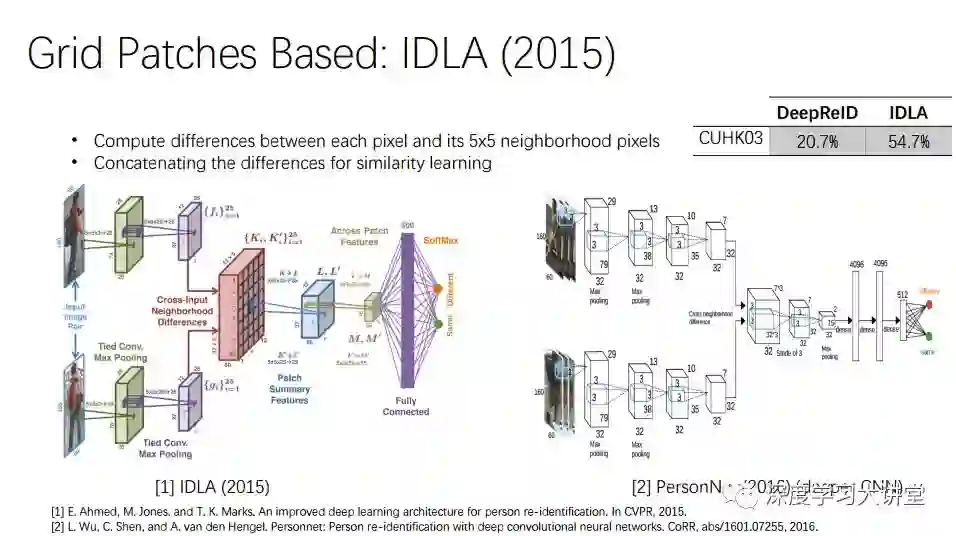
首先是发表在CVPR2015的工作IDLA。它将两个图片转化匹配,认为在另一个图像的邻域网格总能找到匹配。在难以匹配的情况下,可以到邻域寻找匹配,所以性能提高很多。
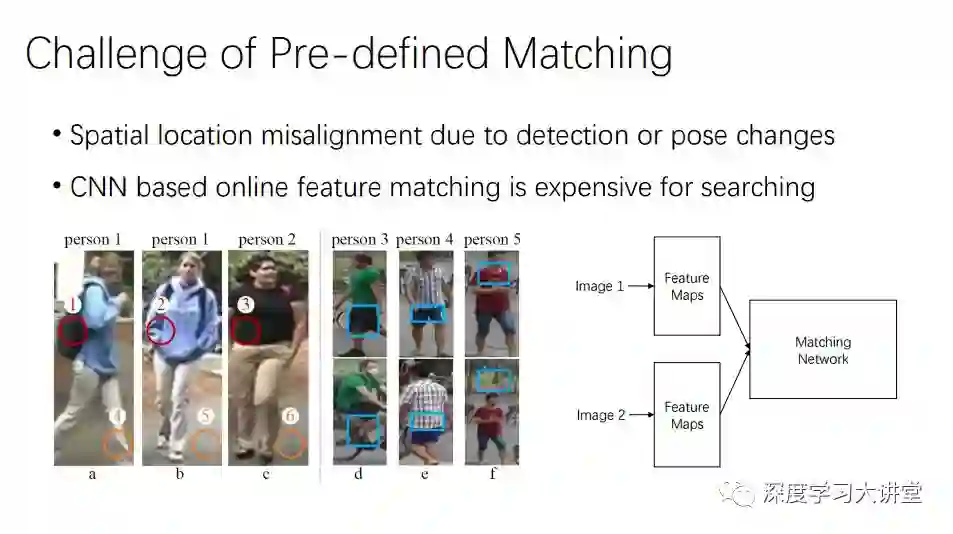
下一个是我们自己的工作。我们认为之前Pre-define的过程有问题,匹配过程很难适应大场景的变换,所以基于这个不足做了一些改进。
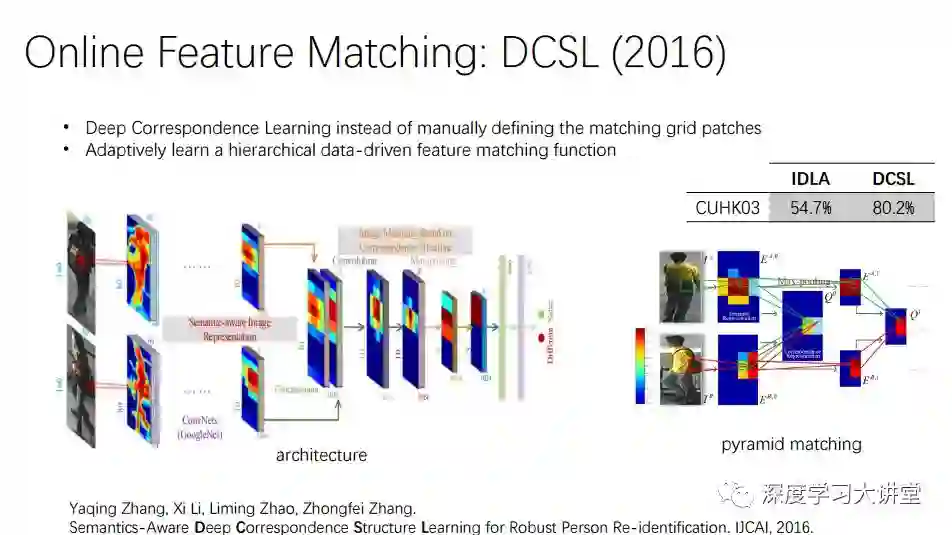
我们将网络结构转化成一个空间金字塔,在一层匹配不了的情况下,到上一层匹配。

第三个是Attention方法,它借助自然语言和图像语言做特征选择。
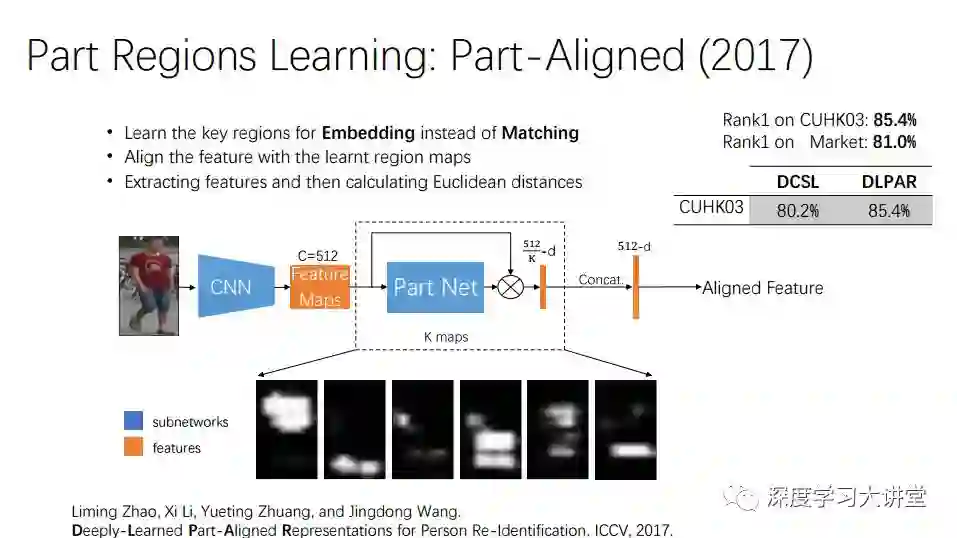
第一个是我们的工作,也算是比较先锋的工作,发表在ICCV2017。这个工作是简单但是非常有效的。在将一个人进行匹配时不是所有区域都参与到匹配中,我们希望加入attention map,来自动发现适合做re-identify的pattern,再做triplet loss,能够在性能上提高7到8个点。
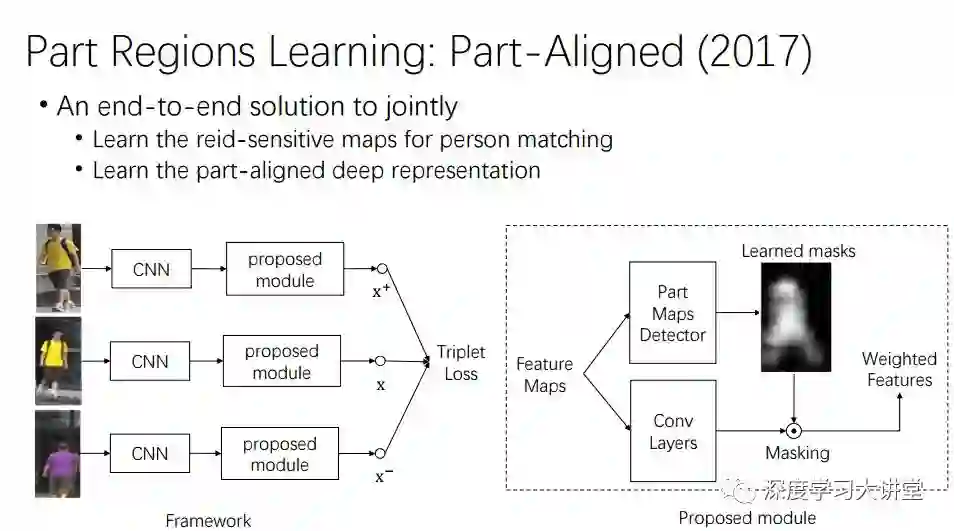
这个模型不需要改变任何网络结构,只需要加入attention map,很适合工程应用。

这是我们的实验结果,发现人变大或变小,或者抠图时人抠得不好,仍然能发现ReID的pattern,这是一个很有意义的insight。
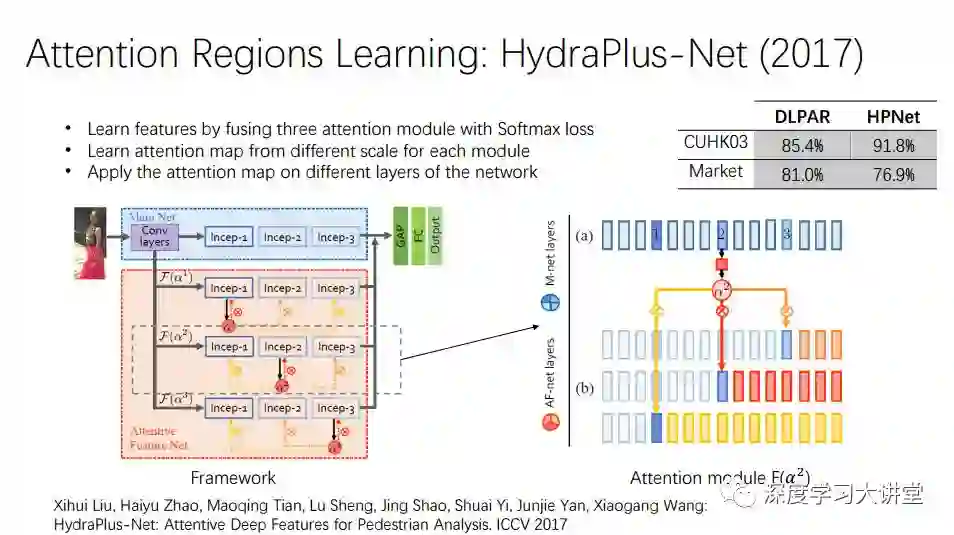
还有工作基于我们这个思想做了一些改进。比如这项工作HPNet很复杂,有多层attention,attention map有多个layer,还有遗忘skip的功能,需要把很多过程整合起来得到一个结果。
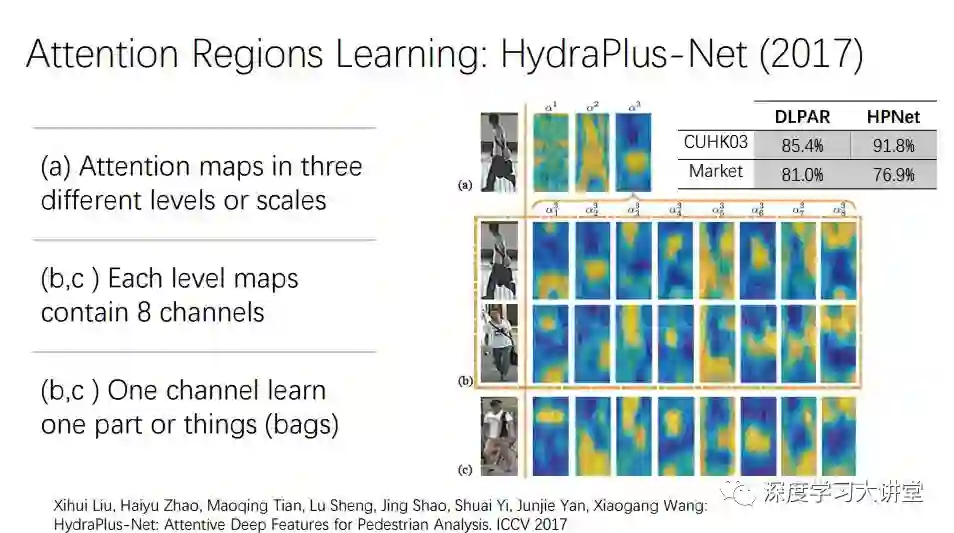
最后HPNet相比我们的模型有进一步的提高,但是在market数据集上比我们的效果差一点。方法越来越复杂,可能在某个数据集上表现越来越好,但是可能泛化能力越来越差。而我们的模型简单,泛化能力强。
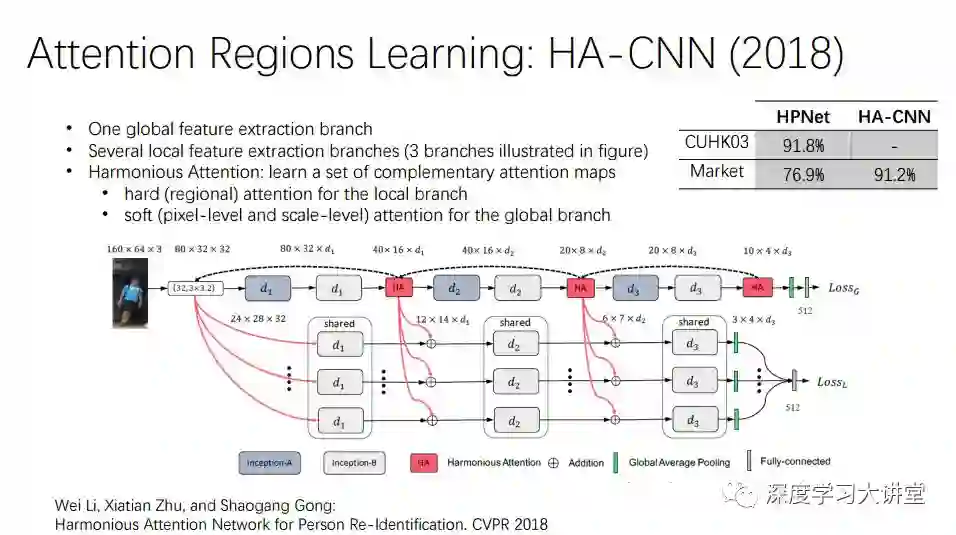
下面这个attention regions learning的方法进一步深化,定义了两种attention,一种是hard attention,有主干道,一种是soft attention,加入一些分支,然后把soft和hard枝干融合。最后只放出market数据集的结果,相比HA-CNN提高很多,但没有放出CHUK03的结果,无法重复实验。

最后是基于Pose的方法,让ReID方法具有更强可解释性。
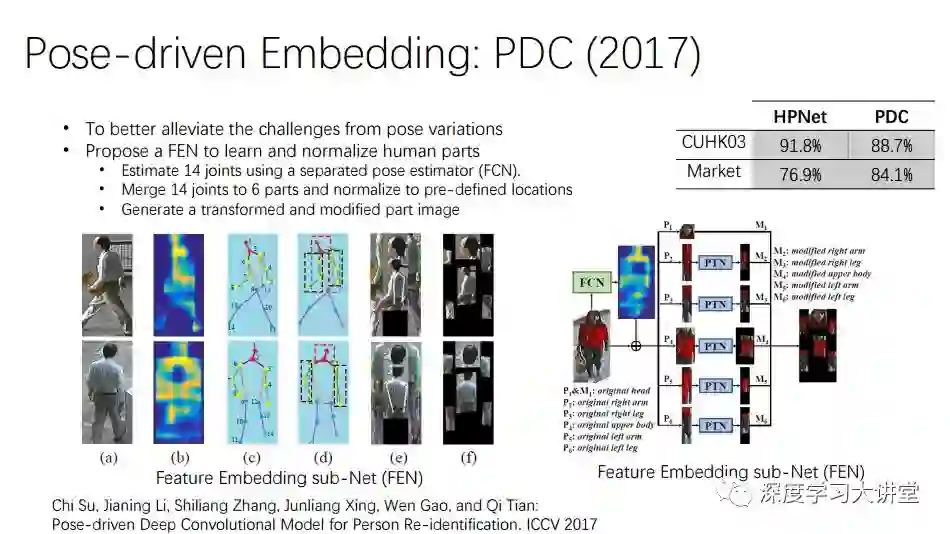
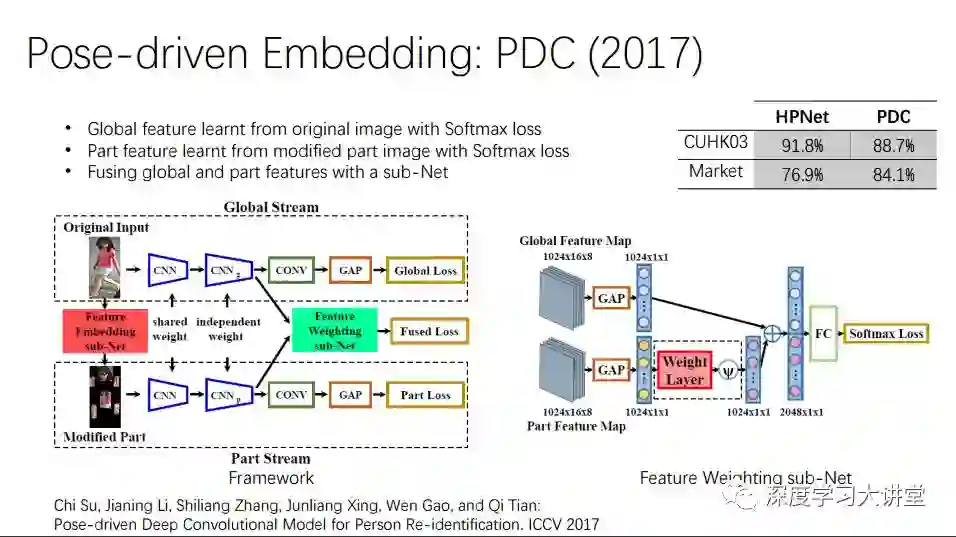
PDC发表在ICCV2017,它将Pose信息嵌入到结构网络中,生成一个modified结构图像,然后对这个结构图像进行识别,效果会有极大提高。
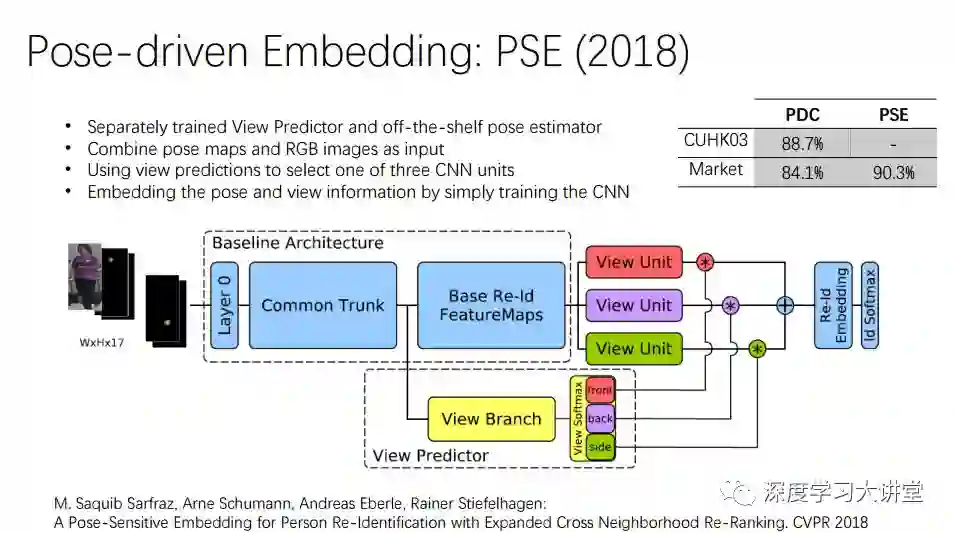
这项工作PSE引入视角关系,将多视角结构进行整合,最后得到的结果也还不错。

通过回顾以上ReID的关键进展,我认为接下来如何更强调空间结构的感知,语义信息的嵌入,以及用快速有效的匹配方式进行融合,例如利用类似人脑的启发性的匹配方式,才是ReID真正应该解决的问题。

最后感谢我的两位学生。谢谢大家!
个人主页:http://mypage.zju.edu.cn/xilics/
参考文献链接:
https://pan.baidu.com/s/1csXOCetmUb-LDfAI6jssGw 密码: h8ft

主编:袁基睿 编辑:程一
整理:曲英男、杨茹茵、高科、高黎明
--end--
该文章属于“深度学习大讲堂”原创,如需要转载,请联系 Emily_0167。
作者简介:

李玺,浙江大学教授,博导,现就职浙江大学计算机学院人工智能研究所,入选第五批中国国家“青年千人计划”和浙江省151第二层次人才。主要从事计算机视觉、模式识别和机器学习等领域的研究和开发。在目标跟踪、目标行为识别、图像标注、视频检索、哈希(hashing)函数学习、深度特征学习等方面取得了深入系统的研究成果,其中在视频的运动跟踪、理解与检索等方面的研究具有特色和优势,取得了多项具有国际影响力的创新性成果。本人在国际权威期刊和国际顶级学术会议发表文章100余篇。担任神经计算领域知名国际刊物Neurocomputing和Neural Processing Letters的Associate Editor,同时担任多个计算机视觉和模式识别方面的国际刊物和国际会议的审稿人和程序委员。获得两项最佳国际会议论文奖(包括ACCV 2010和DICTA 2012),一项ACML最佳学生论文奖,ICIP2015 Top 10% paper award,另外分别获得两项中国北京市自然科学技术奖(包括一等奖和二等奖),以及一项中国专利优秀奖。
往期精彩回顾



欢迎关注我们!
深度学习大讲堂是由中科视拓运营的高质量原创内容平台,邀请学术界、工业界一线专家撰稿,致力于推送人工智能与深度学习最新技术、产品和活动信息!
中科视拓(SeetaTech)将秉持“开源开放共发展”的合作思路,为企业客户提供人脸识别、计算机视觉与机器学习领域“企业研究院式”的技术、人才和知识服务,帮助企业在人工智能时代获得可自主迭代和自我学习的人工智能研发和创新能力。
中科视拓目前正在招聘: 人脸识别算法研究员,深度学习算法工程师,GPU研发工程师, C++研发工程师,Python研发工程师,嵌入式视觉研发工程师,运营经理。有兴趣可以发邮件至:hr@seetatech.com,想了解更多可以访问,www.seetatech.com


中科视拓

深度学习大讲堂
点击阅读原文打开中科视拓官方网站



