GPT-3突然不香了?LeCun昨夜发帖:「人们对它抱有完全不切实际的期望」

新智元报道
【新智元导读】GPT-3是 OpenAI 开发的一种先进的语言处理模型,它非常擅长「炮制出类似人类的文本」。但被称为「人工智能教父」的 Yann LeCun 发帖否定了这个算法,并认为人们对 GPT-3这样的大规模语言模型能做什么抱有「完全不切实际的期望」。

GPT-3可以打破飞行高度,但「登月」需要完全不同的方法
GPT-3可以打破飞行高度,但「登月」需要完全不同的方法


不止是LeCun,马库斯也「喷」过GPT-3
不止是LeCun,马库斯也「喷」过GPT-3

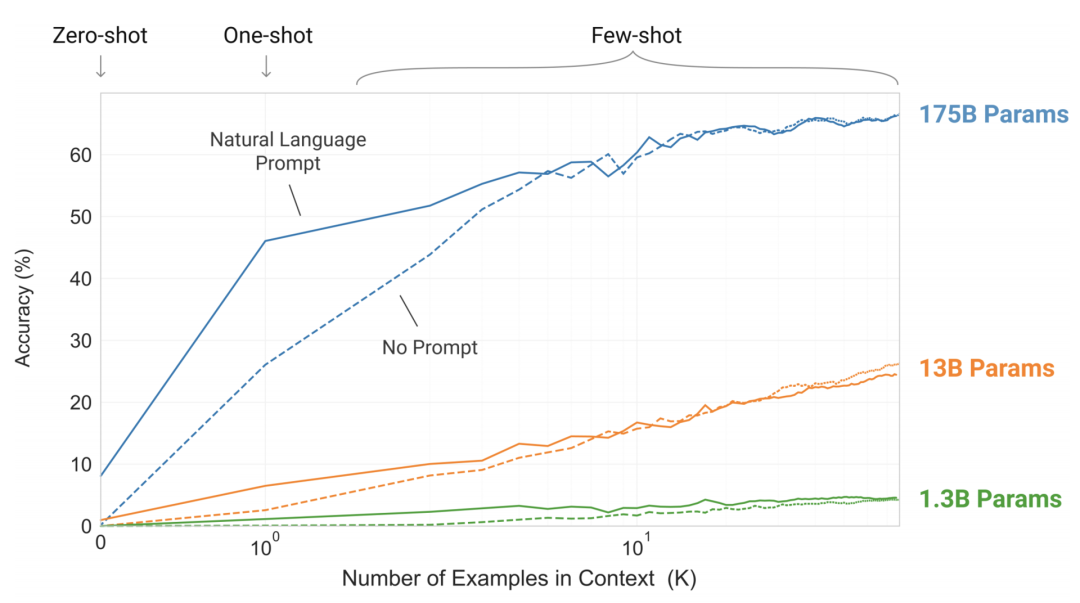
GPT-3解决的问题变多了,但只是堆了更多参数
GPT-3解决的问题变多了,但只是堆了更多参数
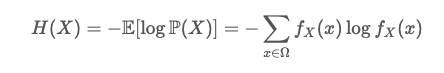 香农熵:
由于语言固有的随机性,一个语言模型可能达到的理论上最低的损失,损失越低,语言越像「人话」。
香农熵:
由于语言固有的随机性,一个语言模型可能达到的理论上最低的损失,损失越低,语言越像「人话」。



登录查看更多
相关内容
Arxiv
0+阅读 · 2021年1月25日




相关VIP内容
相关资讯