ACL 2022 | DQ-BART:基于联合蒸馏和量化的高效Seq2Seq模型

©PaperWeekly 原创 · 作者 | BNDSBilly
单位 | 中科院软件所
研究方向 | 自然语言处理

Abstract
大规模预训练端到端模型如 BART 和 T5 已经在各类 NLP 任务上取得了 sota 表现。然而,由于它们的大内存需求和高延迟,这些模型在资源受限的场景中的应用受到了巨大的挑战。
为解决这个问题,本文同时使用了模型蒸馏和模型量化两种方式,将 BART 模型压缩了 16.5 倍,在多个摘要和 QA 数据集上达到了与原模型相当的表现。

论文标题:
DQ-BART: Efficient Sequence-to-Sequence Model via Joint Distillation and Quantization
https://arxiv.org/abs/2203.11239

预训练端到端模型如 BART 和 T5 在各类 NLP 任务(如文本摘要,机器翻译,QA,信息抽取等)上取得了很大的成功。然而,这些大规模预训练模型参数量已经达到了几亿甚至数十亿,并且还在不断增加。这导致推理期间的计算和内存资源需求很大,且很难部署到实际场景,尤其是实时及资源受限的场景。
以上问题促进了对模型压缩的研究,模型压缩可以使大规模预训练模型变快、变小,且保持与原模型相当的表现。近期模型量化收到了较多的关注,因为它不需要改变精心设计的模型结构,只需要用较少的位数来表示模型权重,从而降低模型规模。然而,对编码器-解码器结构的 transformers 模型量化的研究较少。Prato 等人利用 8-bit 量化压缩了端到端的 transformer 模型。但因为精度损失问题,不能继续压缩到 4-bit,且并不是针对大规模预训练模型的量化,也仅仅面向了机器翻译;Shleifer 等人对 BART 在文本摘要的应用上采用了模型蒸馏,但他们的工作并没有显著减少模型空间。
本文针对以下两个问题进行了研究:
量化后的端到端模型能否在各类NLP任务上都取得较好表现?
-
是否可以结合模型量化和模型蒸馏更进一步的压缩端到端预训练模型?
因此,作者利用了一个高精度的端到端教师模型进行模型蒸馏及量化,训练出了一个层数较少,且低位数的学生模型,缩小了原模型的 16.5 倍。本文还进一步将模型压缩到了 27.7 倍,并展示了预训练模型做生成任务的性能-效率权衡效果。本文也是第一篇探究端到端预训练模型采用模型蒸馏和模型压缩在语言生成任务表现的研究。

Method
3.1 Quantization
模型量化的一般思想是将高精度的实数映射到低精度的整数,从而达到降低模型大小的目的,同时还能加快模型运算速度。目前已经有很多针对神经网络的量化方法研究。包括线性量化、非线性量化、基于近似的量化方法和损失感知量化等。本文结合了线性量化和近似量化方法,对隐藏层和大部分嵌入层的参数进行了量化,没有量化 positional embeddings,激活层量化到了 8bit,以提升矩阵运算的速度。
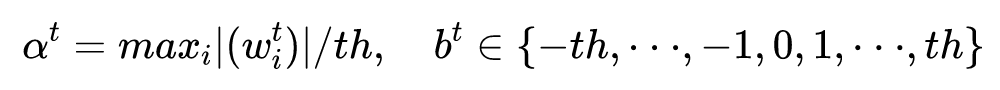
3.2 Distillation

-
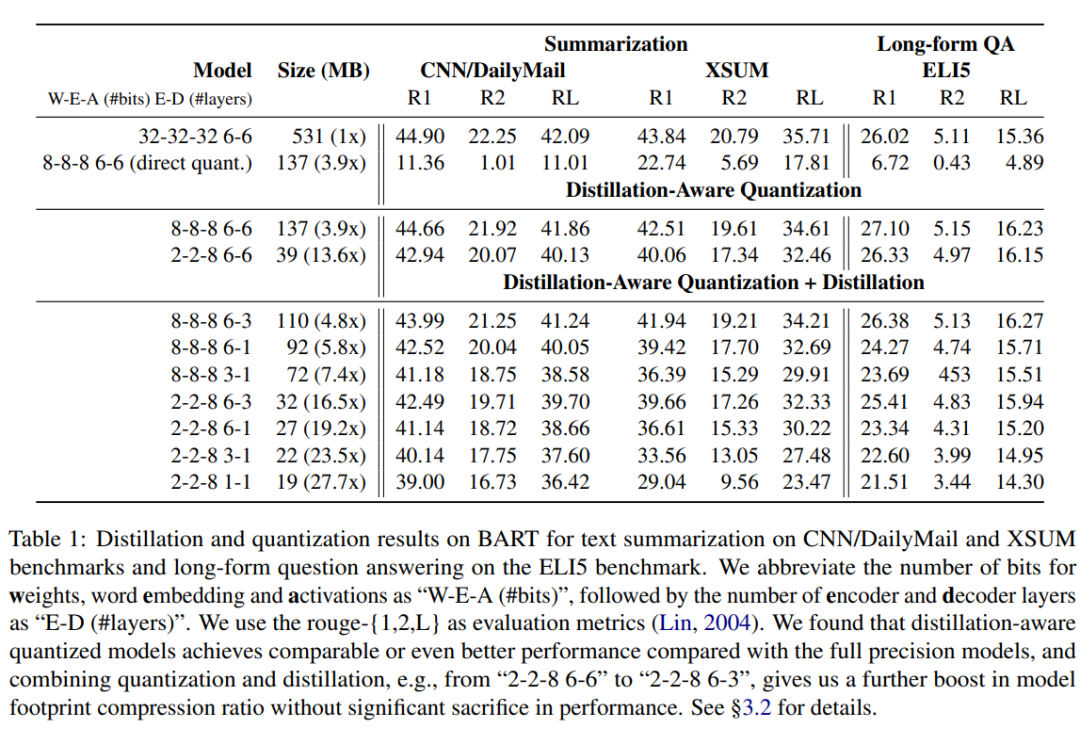
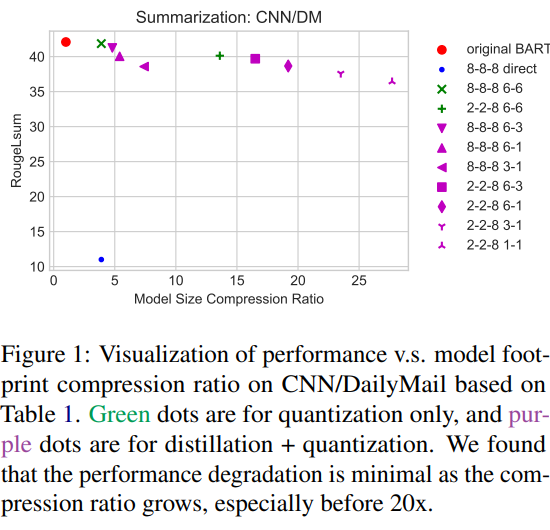
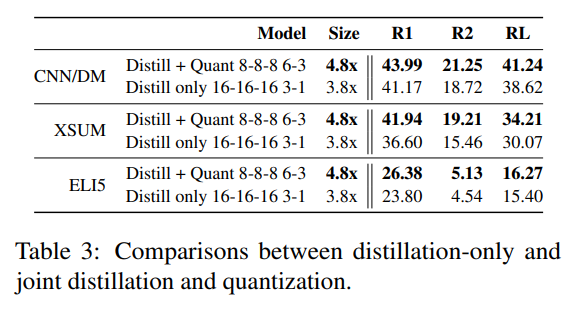
仅使用量化方法压缩模型,在生成任务上表现很差。如图表所示,rouge-L分数(Recall-Oriented Understudy for Gisting Evaluation)与原模型相比降低了约 。 -
位的蒸馏感知量化模型的性能与原模型相当甚至更好,说明对于生成模型如 BART 来说,量化到 位是很容易的。 -
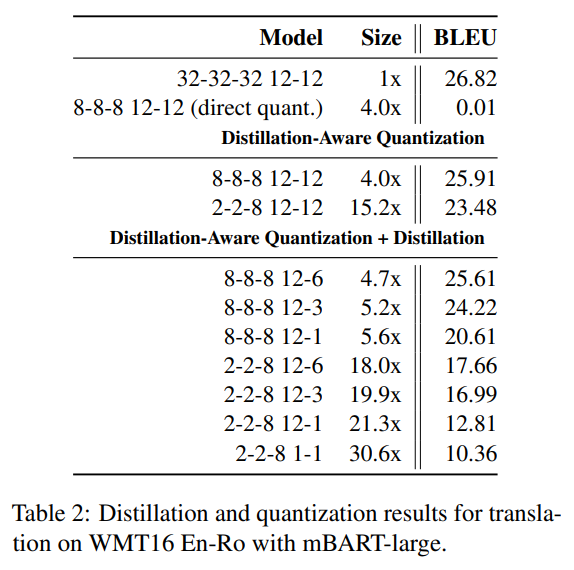
当量化到 位时( ),本文能够实现 倍的模型大小压缩比,相比于原模型,仅摘要任务的性能略有下降,长格式 QA 任务的性能仍保持相当。当我们结合模型蒸馏后(减少编码器和解码器的层数),可以进一步将模型压缩到 倍( ),而不会过度牺牲性能。 -
当将模型压缩到极限时( ),模型被压缩了 倍,此时在三个 benchmark 上仍保持可接受的性能:CNN/DailyMail 的 rouge-L 下降了 ,XSUM 下降了 ,ELI5 下降了 。这表明在实际应用中,选取的压缩比要基于具体选择的任务。

更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧



