Transformer 在自然语言处理和视觉任务中取得了令人瞩目的成果,然而预训练大模型的推理代价是备受关心的问题,华为诺亚方舟实验室的研究者们联合高校提出针对视觉和 NLP 预训练大模型的后训练量化方法。在精度不掉的情况下,比 SOTA 训练感知方法提速 100 倍以上;量化网络性能也逼近训练感知量化方法。
大型预训练模型在计算机视觉和自然语言处理中展现了巨大的潜力,但是模型大、参数多的问题也给它们的商业化落地带来了很大挑战。模型压缩技术是当前的研究热点,模型量化是其中的一个重要分支。
当下预训练模型的量化为了保证性能,大多采用量化感知训练(Quantization-aware Training, QAT)。而模型后量化(Post-training Quantization, PTQ)作为另一类常用量化方法,在预训练大模型领域却鲜有探索。诺亚方舟实验室的研究者从以下四个方面对 QAT 与 PTQ 进行了详细对比:
训练时间:QAT 由于模拟量化算子等操作,训练耗时远远超出全精度训练(FP),而 PTQ 仅仅需要几十分钟,大大缩短量化流程;
显存开销:QAT 显存消耗大于全精度训练(FP),使得在显存有限的设备上难以进行量化训练。而 PTQ 通过逐层回归训练,无需载入整个模型到显存中,从而减小显存开销;
数据依赖:QAT 需要获取整个训练数据集,而 PTQ 只需要随机采样少量校准数据,通常 1K~4K 张 / 条图像或者标注即可;
性能:鉴于 QAT 在整个训练集上充分训练,其性能在不同的量化 bit 上均领先 PTQ。因此性能是 PTQ 的主要瓶颈。
基于以上观测,
研究者提出了针对视觉和 NLP 任务的 PTQ 方法,在保持其训练时间、显存开销、数据依赖上优势的同时,大大改善其性能,使其逼近量化感知训练的精度
。具体而言,仅使用 1% 的训练数据和 1/150 的训练时间,即可达到 SOTA 量化方法的精度。
《Post-Training Quantization for Vision Transformer》
![]()
论文链接:https://arxiv.org/pdf/2106.14156.pdf
下图为视觉 Transformer 后训练量化算法框架:
![]()
自注意力层是 Transfomer 结构中十分重要的部分,也是 Transformer 与传统卷积神经网络不同的地方。对于自注意力层,研究者发现量化使得注意力特征的相对顺序变得不同,会带来很大的性能下降。因此,他们在量化过程中引入了一个排序损失:
![]()
其中表示成对的排序损失函数,表示权衡系数。然后,研究者将排序损失函数与相似度损失函数相结合,得到了最终的优化目标函数:
![]()
论文当中采用了比尔森相关系数作为特征相似度的度量,研究者认为皮尔森相关系数减去了均值,所以对特征的分布表示更加地敏感。
为了进一步减少量化带来的误差,他们在优化量化步长过程中采用了量化误差补偿的方法,以减小量化误差对之后的网络层带来影响。因此对每个网络层的输出都进行了量化误差补偿。
![]()
在实现过程中,误差的期望值可以通过校验数据集来计算,然后在网络层的 bias 参数中去修正。
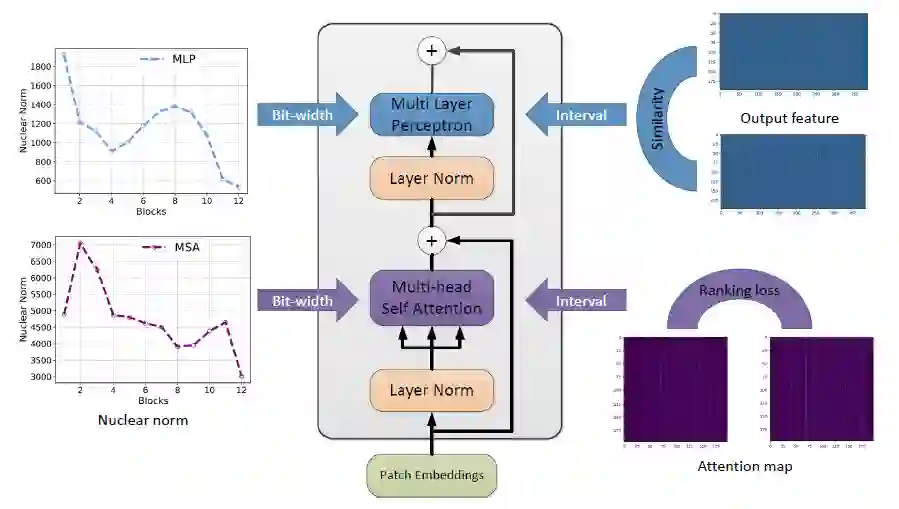
不同的 transformer 网络层有不同的数据分布,因为有不同的量化「敏感度」。研究者提出了混合精度量化,对于更加「敏感」的网络层分配更多的比特宽度。
在论文中,
研究者提出使用 MSA 模块中注意力层特征和 MLP 中输出特征矩阵的核范数来作为度量网络层「敏感度」的方法
。与 HAWQ-V2 中的方法类似,他们使用了一种帕累托最优的方式来决定网络层的量化比特。该方法的主要思想是对每个候选比特组合进行排序,具体的计算方式如下所示:
![]()
给定一个目标模型大小,会对所有的候选比特组合进行排序,并寻找值最小的候选比特组合作为最终的混合比特量化方案。
研究者首先在图像分类任务上对后训练量化算法进行了验证
。从下表可以看出,在 ViT(DeiT)经典 transformer 模型上,论文的量化算法均优于之前的卷积神经网络量化算法【1】【2】。例如,在 ImageNet 数据集上,量化 Deit-B 模型也取得了 81.29% 的 Top-1 准确率。
![]()
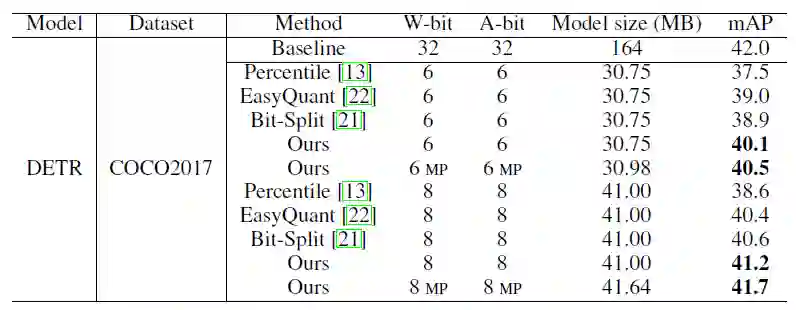
研究者还将后训练量化算法应用于目标检测任务中
,其中在 COCO2017 数据集上,对 DETR 进行量化,8bit 模型的性能可以达到 41.7 mAP,接近全精度模型的性能。
![]()
《Towards Efficient Post-training Quantization of Pre-trained Language Models》
![]()
论文链接:https://arxiv.org/pdf/2109.15082.pdf
![]()
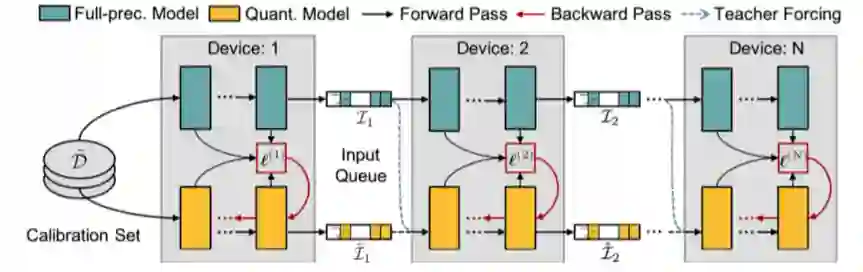
由于 Transformer-based 的预训练语言模型通常含有多个线性层耦合在一起,如果采用现有的逐层重构误差优化的方法【3】,作者发现很容易陷入局部最优解。为了考虑多个线性层内部的交互,如上图所示,
研究者把预训练语言模型切分成多个模块,每个模块含有多个 Transformer 层
。
因此该方法聚焦于逐个重构模块化的量化误差,即最小化全精度网络模块(教师模型)的输出与量化后模型模块(学生网络)的输出之间的平方损失:
![]()
与逐个模块化重构量化误差不同,后量化还可以并行化训练。研究者把每个切分后的模块可以放在不同的 GPU 上,在不同模块之间设置输入缓冲池(input queue)
![]() 来收集上一个模块的输出,同时为下一个模块的输入做准备。不同模块可以通过重置抽样从输入池获取输入样本来进行本地训练,无需等待其前继模块。因此,该设计可以使并行训练,并且实现接近
理论加速比
。
另外一个与逐模块训练不同的点在于,
在并行知识蒸馏训练的初期,下一个模块获得的输入是从上一个未经过充分训练的模块中获得
。因此,未充分训练的模块的输出可能依旧含有较大的量化误差,并且该误差会逐层传播,影响后续模块训练。
为了解决该问题,研究者受
教师纠正(teacher forcing)
在训练循环网络中的启发,将第 n 个全精度模块的输出导入为第 (n+1) 个量化模块的输入,从而中断在后续模块的量化误差传播。然而,这种跨模块输入打破了与量化模型自身前继模块的联系,造成训练和推理前向不一致。为了实现平稳过渡,他们采用了如下的凸组合:
来收集上一个模块的输出,同时为下一个模块的输入做准备。不同模块可以通过重置抽样从输入池获取输入样本来进行本地训练,无需等待其前继模块。因此,该设计可以使并行训练,并且实现接近
理论加速比
。
另外一个与逐模块训练不同的点在于,
在并行知识蒸馏训练的初期,下一个模块获得的输入是从上一个未经过充分训练的模块中获得
。因此,未充分训练的模块的输出可能依旧含有较大的量化误差,并且该误差会逐层传播,影响后续模块训练。
为了解决该问题,研究者受
教师纠正(teacher forcing)
在训练循环网络中的启发,将第 n 个全精度模块的输出导入为第 (n+1) 个量化模块的输入,从而中断在后续模块的量化误差传播。然而,这种跨模块输入打破了与量化模型自身前继模块的联系,造成训练和推理前向不一致。为了实现平稳过渡,他们采用了如下的凸组合:
![]()
并对连接系数
![]() 随着迭代次数 t 进行线性缩减。
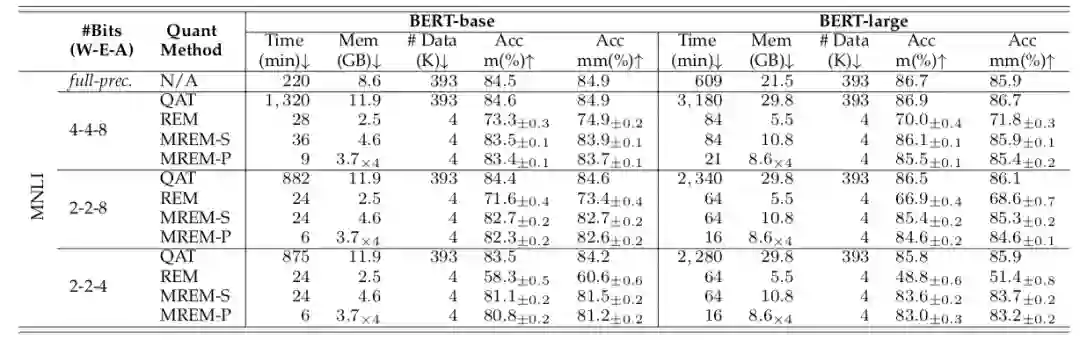
研究者首先在 MNLI 数据集上进行验证。由下表可以发现,对比逐层后量化训练(REM)算法,提出的逐模块量化误差重构 (MREM-S)大大提升了后量化的准确率;同时,MREM-S 性能也可以接近量化感知训练(QAT)的方法,对于 BERT-base 和 BERT-large 在 W4A8 的设定下仅仅比 QAT 低了 1.1% 和 0.8%,训练时间、显存开销和数据消耗也有了减小。
当结合并行知识蒸馏时(MREM-P),后量化训练时间可以进一步缩短 4 倍,而且没有明显性能损失。例如,MREM-P 仅耗时
6 分钟
,占用
3.7GB
即可完成 BERT-base 上 2 比特权重的后量化训练。
随着迭代次数 t 进行线性缩减。
研究者首先在 MNLI 数据集上进行验证。由下表可以发现,对比逐层后量化训练(REM)算法,提出的逐模块量化误差重构 (MREM-S)大大提升了后量化的准确率;同时,MREM-S 性能也可以接近量化感知训练(QAT)的方法,对于 BERT-base 和 BERT-large 在 W4A8 的设定下仅仅比 QAT 低了 1.1% 和 0.8%,训练时间、显存开销和数据消耗也有了减小。
当结合并行知识蒸馏时(MREM-P),后量化训练时间可以进一步缩短 4 倍,而且没有明显性能损失。例如,MREM-P 仅耗时
6 分钟
,占用
3.7GB
即可完成 BERT-base 上 2 比特权重的后量化训练。
![]()
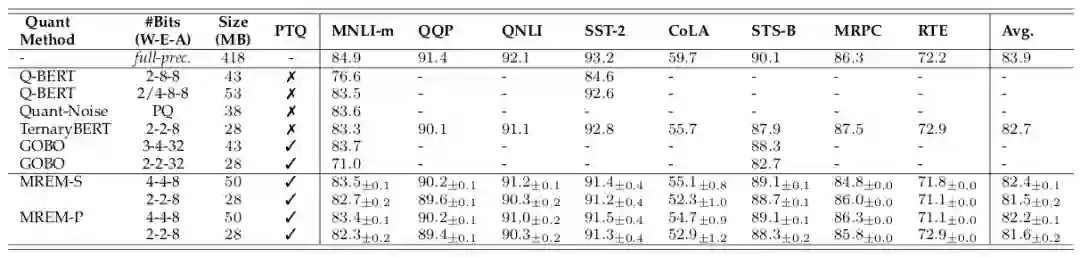
研究者同时在 GLUE 上与现有的其他算法进行了对比。如下表所示,本文的方法 (MREM-S 和 MREM-P) 比后量化方法 GOBO【4】取得更好的效果,甚至在多个任务上接近量化感知训练方法 TernaryBERT。
![]()
【1】Di Wu, Qi Tang, Yongle Zhao, Ming Zhang, Ying Fu, and Debing Zhang. Easyquant: Posttraining
quantization via scale optimization. arXiv preprint arXiv:2006.16669, 2020.
【2】Peisong Wang, Qiang Chen, Xiangyu He, and Jian Cheng. Towards accurate post-training
network quantization via bit-split and stitching. In International Conference on Machine
Learning, pages 9847–9856. PMLR, 2020.
【3】I. Hubara, Y. Nahshan, Y. Hanani, R. Banner, and D. Soudry, “Improving post training neural quantization: Layer-wise calibration and integer programming,” in Proceedings of the International Conference on Machine Learning, 2021.
【4】A. H. Zadeh, I. Edo, O. M. Awad, and A. Moshovos, “Gobo: Quantizing attention-based nlp models for low latency and energy efficient inference,” Preprint arXiv:2005.03842, 2020.
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com


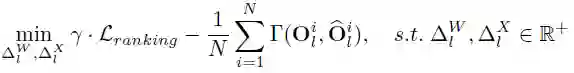
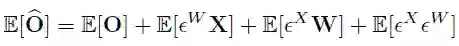
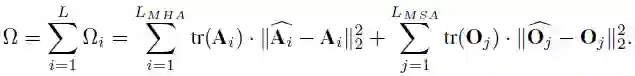


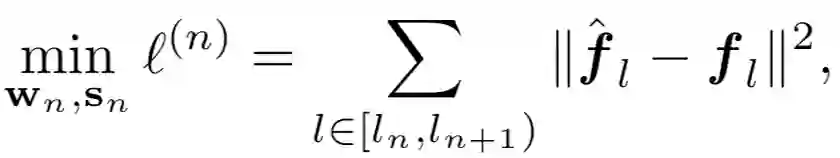
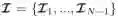 来收集上一个模块的输出,同时为下一个模块的输入做准备。不同模块可以通过重置抽样从输入池获取输入样本来进行本地训练,无需等待其前继模块。因此,该设计可以使并行训练,并且实现接近
理论加速比
。
来收集上一个模块的输出,同时为下一个模块的输入做准备。不同模块可以通过重置抽样从输入池获取输入样本来进行本地训练,无需等待其前继模块。因此,该设计可以使并行训练,并且实现接近
理论加速比
。
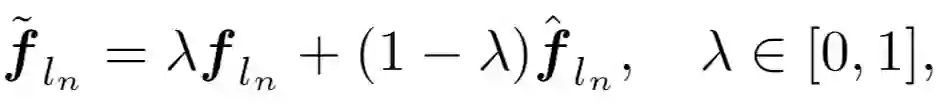
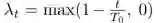 随着迭代次数 t 进行线性缩减。
随着迭代次数 t 进行线性缩减。