【平行讲坛】中科院王飞跃团队详解平行增强学习最新理论框架与案例

近日,针对现有基于数据驱动的方法对新目标缺乏泛化能力、数据匮乏和数据的分布和联系不明显等问题,来自中科院自动化所、中国科学院大学和慧拓智能机器有限公司的多位学者联合发表论文提出了一种平行增强学习的理论框架并展示了多个应用案例。本文对该方法进行了详细的解读与介绍,原文将发表于IEEE/CAA Journal of Automatica Sinica 2018年第3期。
引用格式:T. Liu, B. Tian, Y. Ai, L. Li, D. Cao, and F-Y. Wang, “Parallel Reinforcement Learning: A Framework and Case Study,” IEEE/CAA Journal of Automatica Sinica, 2018.
原文链接:https://book.yunzhan365.com/iths/yhvv/index.html(或扫描文末二维码查看全文)
正文
机器学习,特别是深度增强学习在最近几年呈现飞速的发展态势[1],[2]。无论是在传统的视觉检测[3]、机器人灵巧的操控[4]、能量效率的提升[5]、目标定位[6]或新颖的Atari游戏[7],[8]、Leduc扑克[9]、Doom游戏[10]和基于文本的游戏[11]等领域,基于数据驱动的学习方法在提升控制效果和精度方面都展现了巨大的潜能。然而,将深度增强学习应于真实复杂系统的控制时,仍然遇到以下几个难点。
第一个难点是缺乏对新目标的泛化能力[3]。控制器在应对新的目标时,需要收集新的数据和学习新的模型。训练新的模型的过程十分耗时。因此,我们需要利用有限的数据来获取控制,去适应不同的环境。
第二个难点是数据匮乏[8]。针对复杂系统,获取大规模的行动和交互数据十分困难。在没有指导的前提下,去探索策略也十分不易。因此,需要有效地利用历史数据,用于新的数据获取和行动选择。
最后一个难点是数据的分布和联系并不明显。在实际系统中,数据之间联系往往是不确定的,数据的概率分布也经常时变。因此,控制器很难对这样的数据进行分析,并获得有效的行动指导。
为了处理上述问题,本文提出针对于复杂系统控制的平行增强学习框架。通过构建与真实系统并行的人工系统,获得平行系统。通过将转移学习、预测学习和深度学习与增强学习融合,用于处理数据获取和行动选择过程,同时表达获得的知识。最后,介绍了几个平行增强学习应用的案例。本文提出的平行增强学习的框架可以看作是平行学习[12]的一个实例。
中科院自动化所王飞跃研究员于2004年提出了平行系统的思想,试图用一种适合复杂系统的计算理论与方法(ACP方法)解决社会经济系统中的重要问题[13],[14]。ACP方法是指人工社会(A)用于建模,计算实验(C)用于分析,平行执行(P)用于控制。人工系统往往通过建模获得,用于数据获取和行动选择。通过实际系统与人工系统相辅相成地运行,控制器能够变得更高效,同时对数据的依赖度也会减少。ACP方法用于复杂系统中解决不同的领域的问题参见文献[15]-[17]。
转移学习强调将解决某一问题的知识转化并扩展,应用于同类型的其他问题。本文以车辆驾驶工况为例,通过平均驱动力(MTF)组件对它们实现转化。这样做可以有效地减缓缺乏泛化能力的问题。预测学习指通过已有的数据和知识构建预测模型,对不同环境中的控制进行预测。本文以需求功率为例,提出模糊编码预测器对未来的需求功率进行不同步长的预测。可以有效地减轻数据匮乏问题。深度学习定义为学习数据的表现形式,包括多层的非线性处理单元和监督或非监督学习方法去学习每层的特征表达。增强学习关心控制对象如何从环境中获取控制来最大化累积回报。
该文章通过将转移学习、预测学习和深度学习与增强学习融合构建深度增强学习的理论框架,用于处理本文开始提出的几个难点问题。
1. 平行增强学习框架和平行系统
平行增强学习的框架如图1所示。数据代表人工系统和真实系统的输入和参数。知识代表从状态空间到控制空间的记录,在真实系统中叫作经验,在人工系统中叫作策略。经验用于修正人工模型,策略用于指导真实系统的运行。
最近,信息物理系统越来越受到关注,源于它们处理复杂计算过程的能力。同时,信息物理社会系统加入了人和社会的特性,从而能够更有效地进行设计和操作[18]。基于ACP的平行系统框架如图2所示。人工系统和真实系统统称为平行系统。
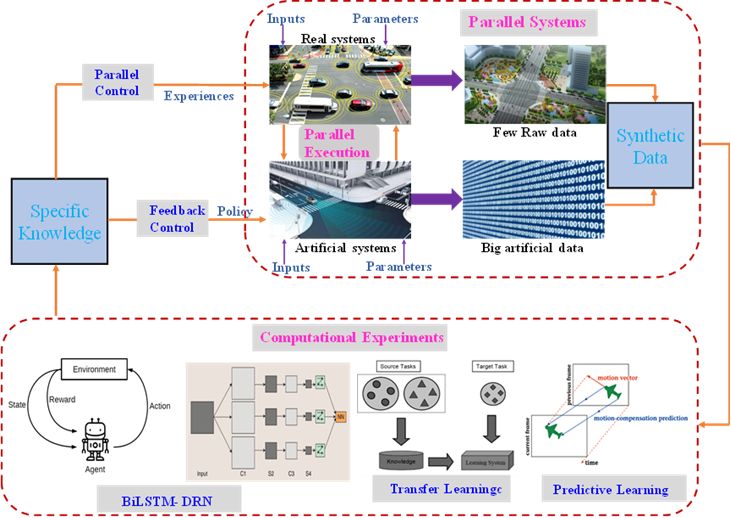
图1 平行增强系统框架
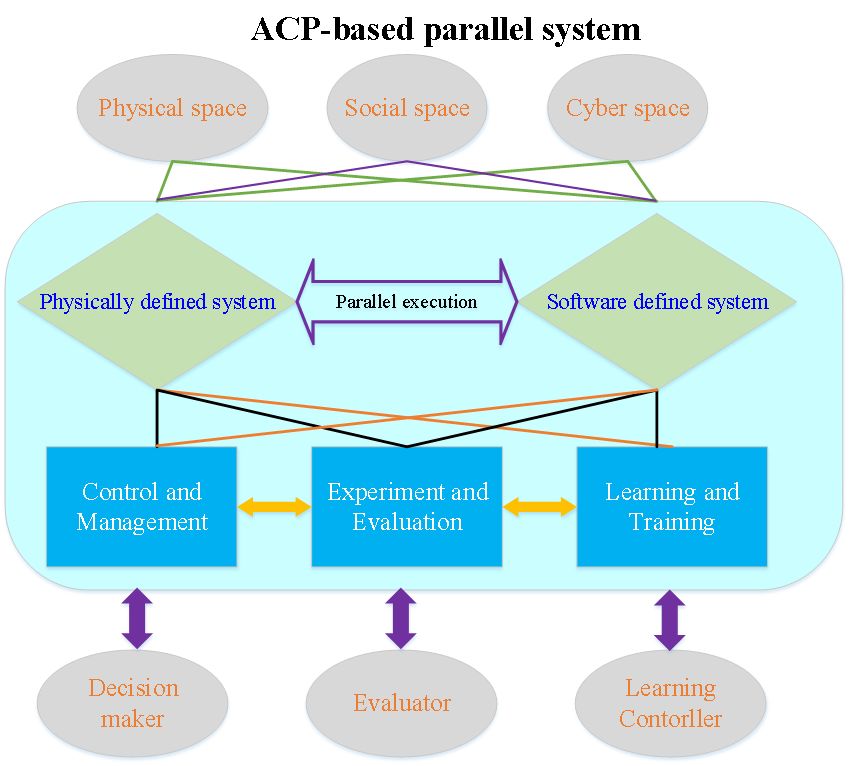
图2 基于ACP的平行系统框架
在该平行系统中,物理定义的真实系统与软件定义的人工系统通过三个模块耦合。这三个模块分别是控制和管理、实验和评估以及学习和训练。第一个模块属于决策与规划模块、第二个属于数据评价模块、第三个模块属于学习控制模块。
人工系统常通过观察实际系统的表现,而后通过描述学习构建。它能够帮助学习控制器存储更多的计算结果,同时做更有效的行动。针对特定的平行智能系统,计算实验常通过不同的学习方法来获得不同的经验或策略[19]。平行执行则是人工系统和真实系统在平行空间中相辅相成的运行,不断地修改建模精度和指导实际系统运行[20]。
2. 转移学习
本文以车辆的行驶工况为例来介绍转移学习,如图3所示。本文介绍基于平均驱动力组件的转移工况方法。该方法能够将已有的工况数据转移为与当前环境契合的等效数据。
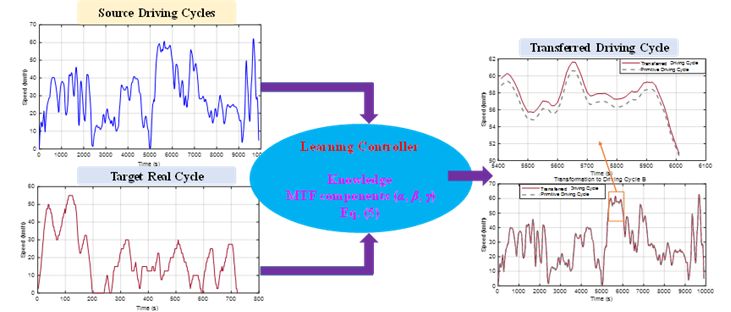
图3 转移学习用于工况转移
平均驱动力定义为在特定的时间区间[0,T]内,驱动能除以行驶距离:
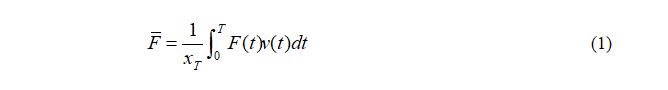
其中,xT=∫v(t)dt是行驶距离,v是车辆速度。F是纵向驱动力:

其中,Fa 是空气阻力,Fr 是滚动阻力,Fm 是惯性力。ρa 是空气密度,Mv 是车辆质量,Cd 是空气阻力系数,A是迎风面积。g重力加速度,f 滚动阻力系统,a是加速度。
车辆的驱动模式可分为驱动,巡航,制动和怠速。根据不同模型下驱动力的不同,时间区间可分为[21]:
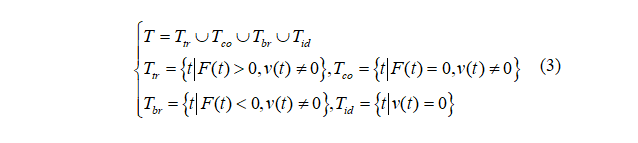
其中,Ttr和Tco是驱动模式和巡航模式,Tbr代表车辆制动,Tid 是怠速时间集。
对式(3)来说,车辆传动系统只有在驱动模式下提供正的功率。因此式(1)中的驱动力可以改写为:
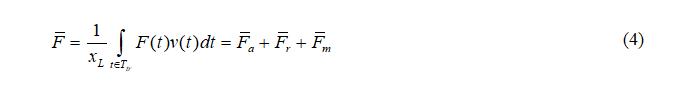
随后,特定工况下的驱动力组件(α, β, γ)可以定义为[22]:
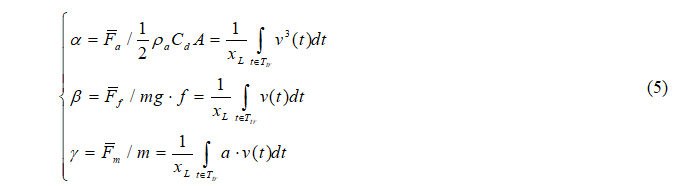
最终,工况的转移过程可以定义为非线性规划问题。其中的代价函数可以表达为:
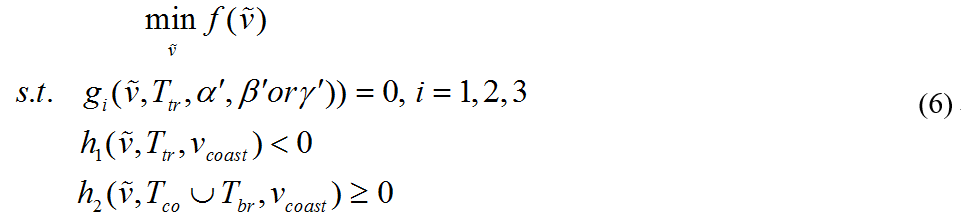
其中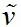
转移学习的目的是将历史可用数据转化为与真实环境契合的等效数据,它可以用于自适应控制,从而解决泛化能力和数据匮乏问题。
3. 预测学习
本文以需求功率为例来介绍预测学习,如图4所示。本文介绍基于模糊编码控制器的需求功率预测方法。该方法可以用于获得不同复杂系统的未来经验和策略。
需求功率建模为有限的马尔科夫链[23],Pdem={pj | j=1, …, M⊂X,,需求功率的转移概率通过极大似然估计求得
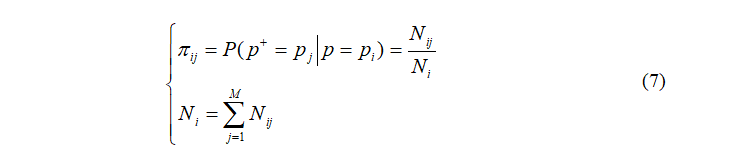
其中,πij是从pi到 pj的转移概率。p和 p+是当前和下一步的转移概率。Nij代表从pi到 pj的转移概率的总转移次数,Ni是起始于pi 的总转移次数。
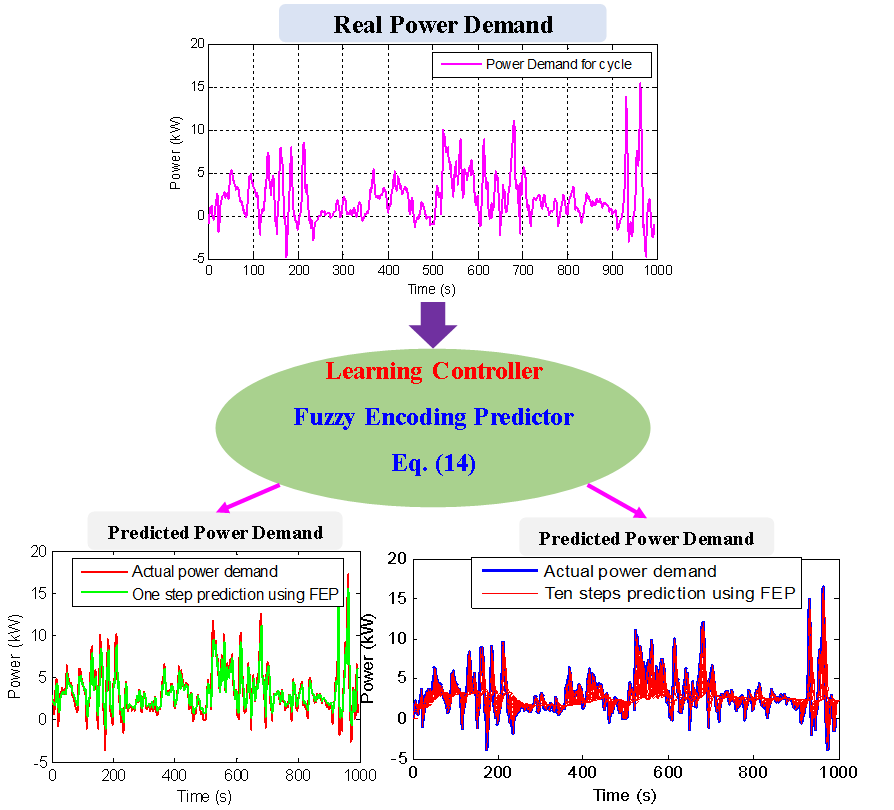
图4 预测学习用于预测未来需求功率
所有转移概率πij组成转移概率矩阵Π。在模糊编码方法中,X被分为有限个模糊子集,Φj, j=1, …, M。Φj称为勒贝格隶属函数,定义为
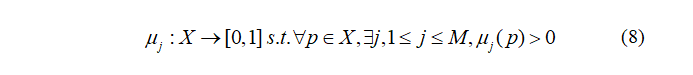
其中,μj(p)反应在 μj 中p∈X 的隶属度。需要注意的是,一个连续状态p∈X,在模糊编码方法中,可以拥有对个隶属函数[24]。
模糊编码预测器包含两步:第一步是为每个p∈X分配M维的可能度矢量
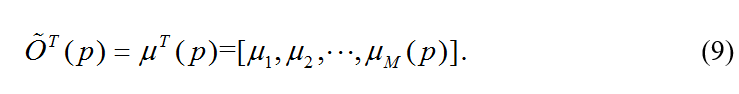
第二步称为成比例的可能到概率的转移,将可能度矢量转移为概率矢量:
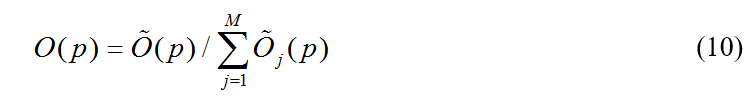
最后,需求功率的预测公式为:
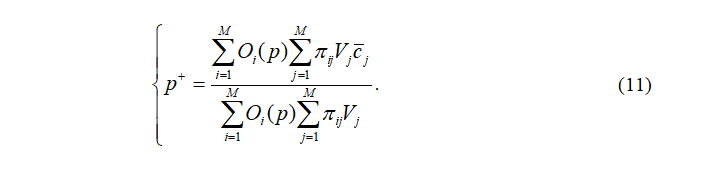
预测学习的目的是通过存在的数据和实时的观察来预测未来的情况。生成的数据可以指导真实系统的学习,从而解决数据匮乏和数据分布不确定的问题。
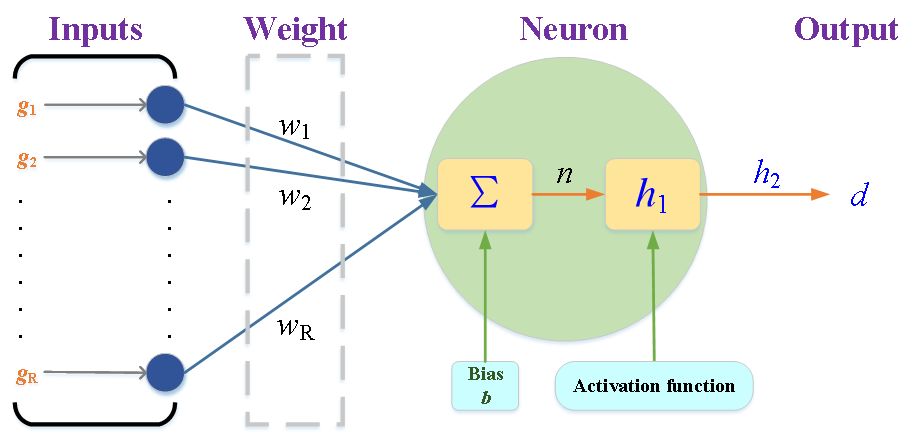
(a) 深度神经网络
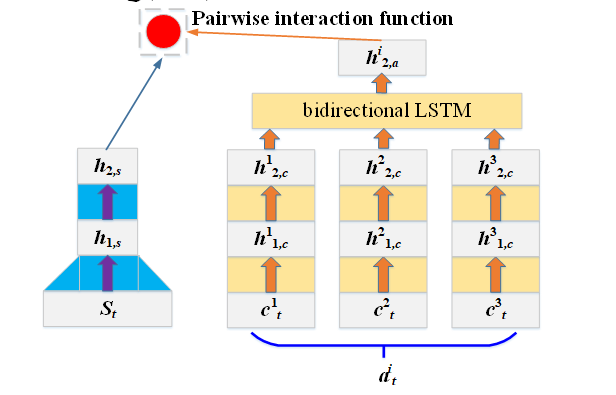
(b) 双向长短记忆网络[26]
图5 深度神经网络和双向长短记忆网络
4. 增强学习
在增强学习框架中,环境与被控对象的交互过程可以建模为五维数组(S, A, Π, R, γ),其中s∈S 和 a∈A 称为状态变量和控制变量集合,Π 是转移概率矩阵,r∈R是汇报函数,γ∈(0, 1)是折扣因子。
控制值函数Q(s,a)定义为:
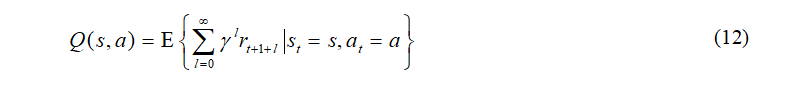
强化学习中,Q-learning算法的迭代公式为[25]:
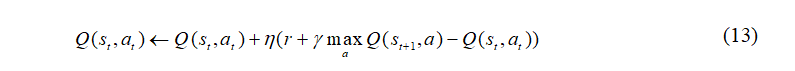
当控制变量包含多个子控制at时,直接对Q值建模十分困难。在这种情况下,我们控制和状态变量输入深度神经网络进行近似,如图5所示。
最终,经训练后的控制值函数表达为:
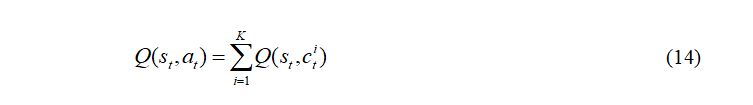
其中,K是子控制变量的个数,Q(st, cit)代表期望的累积回报。
融合平行系统、转移学习、预测学习、深度学习和增强学习,可以构建如图1所示的平行增强学习框架,下一节讨论几个平行增强学习应用的应用案例。
5. 平行增强学习典型应用案例介绍
平行增强学习的概念应用到了不同的复杂系统控制领域,比如交通系统[27],[28],视觉系统[29]和其他的社会系统[30]。文献[27]中主要讨论交通流的预测过程,包括构建人工系统(名为栈式自编码模型)用于学习一般的交通流特性。然后,深度学习用于训练人工系统和真实系统提供的综合数据。最后,预测学习用于预测未来的交通流,同时指导平行系统。
同时,平行增强学习理论还用于解决视觉感知问题[29]。构建人工视觉系统,其产生数据与真实系统数据融合,用于特征分析、目标分析和场景分析。衍生的新的视觉感知研究方法称为平行视觉。
最后,旨在提升车辆能量效率的车辆自主学习系统也可以归为平行增强学习的范畴[31]。 首先,插电式的混合动力模型用于构建平行系统;随后,深度神经网络和增强学习用于处理综合数据,得到最优的燃油使用控制策略;最后,获得的策略用于指导实际系统的运行,同时提升控制特性。
综合车辆的工况转移方法和增强学习,本文提出混合动力车辆的自适应能量管理策略。它可以解决两个潜在的困难:首先,大多数能量管理策略无法适应不同的环境;其次,基于模型的能量管理策略常常需要准备的车辆模型,同时对计算能力的要求较高。基于平行增强学习的自适应能量管理策略如图6所示。
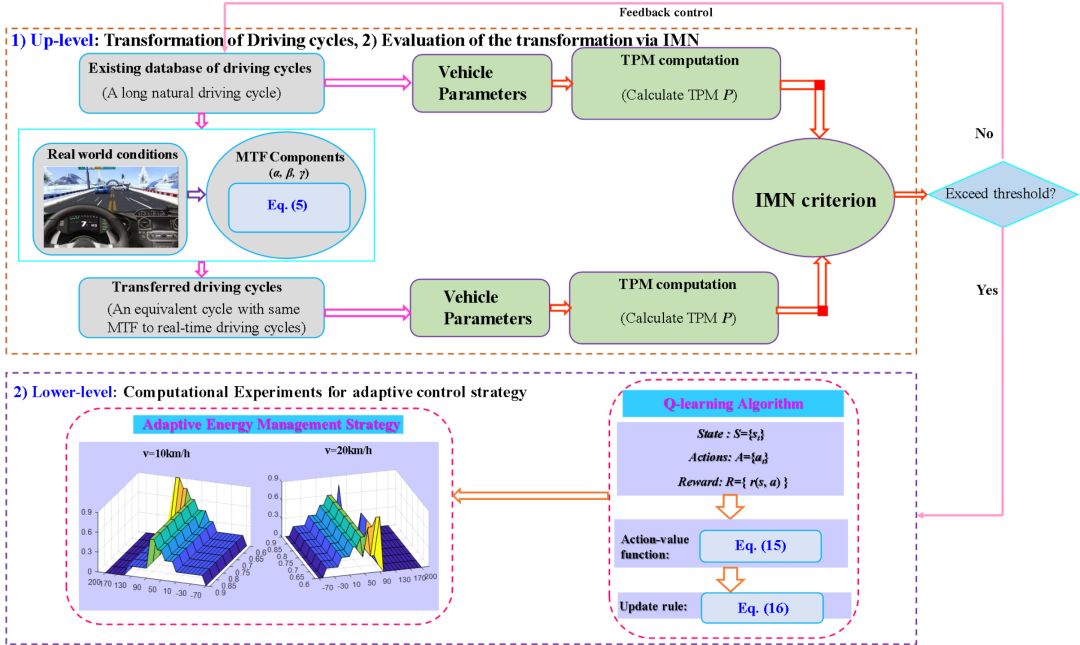
图6. 平行增强学习在混合动力轮式车辆能量管理中应用
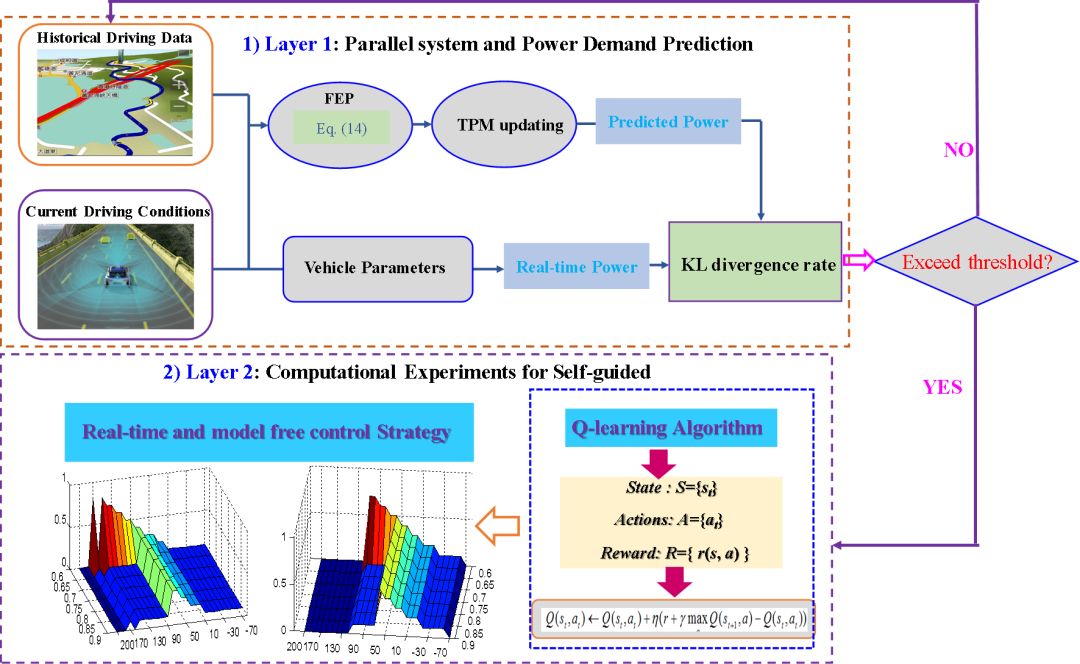
图7. 平行增强学习在混合动力履带车辆
上层主要解决车辆行驶工况的转移问题,下层主要通过增强学习来求得对应的控制。实验结果证明基于平行增强学习的能量管理策略在计算速度和控制效果上都远优于传统的增强学习方法。
最后,本文还将平行增强学习的理论应用到了混合动力履带车的节油控制中,如图7所示。首先,利用预测学习对履带车辆的需求功率进行预测,然后利用增强学习对最优的节油控制进行计算。比较结果分析显示,平行增强学习能够有效地提升燃油经济性,同时有潜能实现实时控制。将来,平行增强学习的理论还拟用到自动驾驶的各项任务中。包括:决策与规划、速度规划和路径规划等等。
本文介绍了平行增强学习的理论框架和应用案例。目的在于在平行系统的框架下构建系统的数据与知识的闭环交互系统,用于指导实际系统的操作和提升人工系统的准确性。在转移学习中,平均驱动力组件用于实现行驶工况的等效变换。在预测学习中,模糊编码预测器用于预测未来的需求功率。
基于数据驱动的模型常会导致大规模的探索过程和无效的观测过程。同时,这些模型中的数据常常不大准确,一般的指导性规则也有所缺失。融合平行系统、转移学习、预测学习、深度学习和增强学习,本文提出了平行增强学习的理论。相信在将来,平行增强学习的理论能够得到广泛的应用并推动机器学习的进一步发展。

扫描二维码,查看下载原文章
参考文献:
[1] V. Mnih, K. Kavukcuoglu, D. Silver, A. A. Rusu, J. Veness, M. G. Bellemare, A. Graves, M. Riedmiller, A. K. Fidjeland, G. Ostrovski, S. Petersen, C. Beattie, A. Sadik, I. Antonoglou, H. King, D. Kumaran, D. Wierstra, S. Legg, and D. Hassabis, “Human-level control through deep reinforcement learning,” Nature, vol. 518, no. 7540, pp. 529-533, Feb. 2015.
[2] D. Silver, A. Huang, C. J. Maddison, A. Guez, L. Sifre, G. vanden Driessche, J. Schrittwieser, I. Antonoglou, V. Panneershelvam, M. Lanctot, S. Dieleman, D, Grewe, J. Nham, N. Kalchbrenner, I. Sutskever, T. Lillicrap, M. Leach, K. Kavukcuoglu, T. Graepel, and D. Hassabis, “Mastering the game of Go with deep neural networks and tree search,” Nature, vol. 529, no. 7587, pp. 484-489, Jan. 2016.
[3] Y. Zhu, R. Mottaghi, and E. Kolve, “Target-driven visual navigation in indoor scenes using deep reinforcement learning,” in Proc. 2017 IEEE International Conference on Robotics and Automation (ICRA), 2017.
[4] I. Popov, N. Heess, and T. Lillicrap, “Data-efficient Deep Reinforcement Learning for Dexterous Manipulation,” arXiv:1704.03073, 2017.
[5] X. Qi, T. Luo, G. Wu, K. Boriboonsomsin, and M. Barth, “Deep reinforcement learning-based vehicle energy efficiency autonomous learning system,” in Proc.Intelligent Vehicles Symposium (IV), 2017.
[6] J. Caicedo, and S. Lazebnik, “Active object localization with deep reinforcement learning,” in Proc. IEEE International Conference on Computer Vision, 2015.
[7] X. Guo, S. Singh, R. Lewis, and H. Lee, “Deep learning for reward design to improve monte carlo tree search in atari games,” arXiv preprint arXiv:1604.07095, 2016.
[8] V. Mnih, K. Kavukcuoglu, D. Silver, and A. Graves, “Playing atari with deep reinforcement learning,” arXiv preprint arXiv:1312.5602, 2013.
[9] J. Heinrich, and D. Silver, “Deep reinforcement learning from self-play in imperfect-information games,” arXiv preprint arXiv:1603.01121, 2016.
[10] D. Hafner, “Deep Reinforcement Learning From Raw Pixels in Doom,” arXiv preprint arXiv:1610.02164, 2016.
[11] K. Narasimhan, T. Kulkarni, and R. Barzilay, “Language understanding for text-based games using deep reinforcement learning,” arXiv preprint arXiv:1506.08941, 2015.
[12] L. Li, Y. L. Lin, N. N. Zheng, and F. -Y. Wang, “Parallel Learning: A Perspective and A Framework”, IEEE/CAA J. of Autom. Sinica, vol. 4, no. 3, pp. 389-395, Jul. 2017.
[13] F.-Y. Wang, “Artificial societies, computational experiments, and parallel systems: A discussion on computational theory of complex social-economic systems,” Complex Syst. Complex. Sci., vol. 1, no. 4, pp. 25-35, Oct. 2004.
[14] F.-Y. Wang, “Toward a paradigm shift in social computing: The ACP approach,” IEEE Intell. Syst., vol. 22, no. 5, pp. 65-67, Sept.-Oct. 2007.
[15] F. -Y. Wang, “Parallel control and management for intelligent transportation systems: Concepts, architectures, and applications,” IEEE Trans. Intell. Transp. Syst., vol. 11, no. 3, pp. 630-638, Sep. 2010.
[16] F. -Y. Wang and S. N. Tang, “Artificial societies for integrated and sustainable development of metropolitan systems,” IEEE Intell. Syst., vol. 19, no. 4, pp. 82-87, Jul.-Aug. 2004.
[17] F. -Y. Wang, H. Zhang, and D. Liu, “Adaptive dynamic programming: An introduction,” IEEE Comput. Intell. magazine, vol. 4, no. 2, 2009.
[18] F. -Y. Wang, “The emergence of intelligent enterprises: From CPS to CPSS,” IEEE Intelligent Systems, vol. 25, no. 4, pp. 85-88, 2010.
[19] F. -Y. Wang, N. -N. Zheng, D. Cao, C. Martinez, L. Li, and T. Liu, “Parallel Driving in CPSS: A Unified Approach for Transport Automation and Vehicle Intelligence,” IEEE/CAA J. of Autom. Sinica, vol. 4, no. 4, pp. 577-587, Oct. 2017.
[20] K. F. Wang, C. Gou, and F. -Y. Wang, “Parallel Vision: an ACP-based Approach to Intelligent Vision Computing,” Acta Automat. Sin., vol. 42, no. 10, pp. 1490-1500, Oct. 2016.
[21] P. Nyberg E. Frisk, and L. Nielsen, “Driving Cycle Equivalence and Transformation,” IEEE Trans. Veh. Technol., vol. 66, no. 3, pp. 1963-1974, 2017.
[22] P. Nyberg, E. Frisk, and L. Nielsen, “Driving cycle adaption and design based on mean tractive force,” in Proc. 7th IFAC Symp. Adv. Autom. Control, Tokyo, Japan, vol. 7, no. 1, pp. 689-694, 2013.
[23] D. P. Filevand, and I. Kolmanovsky, “Generalized markov models for real-time modeling of continuous systems,” IEEE Trans. Fuzzy. Syst., vol.22, pp.983-998, 2014.
[24] D. P. Filevand, and I. Kolmanovsky, “Markov chain modeling approaches for on board applications,” In: Proc. of the 2010 American Control Conference, pp.4139-4145, 2010.
[25] T. Liu, X. Hu, S. Li, and D. Cao, “Reinforcement Learning Optimized Look-Ahead Energy Management of a Parallel Hybrid Electric Vehicle,” IEEE/ASME Trans. on Mechatronics, vol. 22, no. 4, pp.1497-1507, 2017.
[26] A. Graves, and S. Jürgen, “Framewise phoneme classification with bidirectional LSTM and other neural network architectures,” Neural Networks, vol. 18, no. 5, pp. 602-610, 2005.
[27] Y. S. Lv, Y. J. Duan, W. W. Kang, Z. X. Li, and F.-Y. Wang, “Traffic flow prediction with big data: a deep learning approach,” IEEE Trans. on Intell. Transp. Syst., vol. 16, no.2, pp. 865-873, Apr. 2015.
[28] J. P. Zhang, F. -Y. Wang, K. F. Wang, W. H. Lin, X. Xu, and C. Chen, “Data-driven intelligent transportation systems: A survey,” IEEE Trans. Intell. Transp. Syst., vol. 12, no.4, pp. 1624-1639, Dec. 2011.
[29] K. F. Wang, C. Gou, N. N. Zheng, J. M. Rehg, and F. -Y. Wang, “Parallel vision for perception and understanding of complex scenes: methods, framework, and perspectives,” Artif. Intell. Rev., pp.1-31, 2016.
[30] F. -Y. Wang, and J. S. Lansing, “From artificial life to artificial societies: New methods for studies of complex social systems,” Complex Syst. Complex. Sci., vol. 1, no. 1, pp. 33-41, 2004.
[31] W. Liu, Z. H. Li, L. Li, and F. -Y. Wang, “Parking like a human: a direct trajectory planning solution,” IEEE Trans. Intell. Transp. Syst., no. 99, pp. 1-10, Apr. 2017.
📚往期文章推荐

🔗【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
🔗【智能自动化学科前沿讲习班第1期】王坤峰副研究员:GAN与平行视觉

德先生公众号 | 往期精选
在公众号会话位置回复以下关键词,查看德先生往期文章!
人工智能|机器崛起|区块链|名人堂
虚拟现实|无人驾驶|智能制造|无人机
科研创新|网络安全|数据时代|人机大战
……
更多精彩文章正在赶来,敬请期待!


点击“阅读原文”,移步求知书店,可查阅选购德先生推荐书籍。


