【ICLR2022】序列生成的目标侧数据增强

论文题目:Target-Side Data Augmentation for Sequence Generation
作者:解曙方,吕昂,夏应策,吴郦军,秦涛,刘铁岩,严睿
通讯作者:严睿
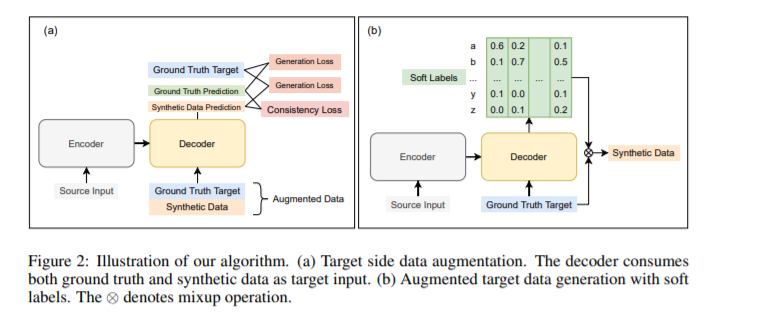
论文概述:自回归序列生成是机器学习和自然语言处理中的一个重要方法。每个元素在生成的时候,它同时基于输入条件和已经生成的元素。之前的数据增强方法,虽然已经在各种任务上取得的显著的效果,却只是被运用在了输入条件上。例如在输入的序列中增加噪声,或进行随机替换,打乱,掩码等操作。这些方法都忽视了对已生成元素的增强。本文提出了一种生成端的数据增强方法。在训练阶段,我们使用解码器的输出作为软标签,与真实数据一起生成增强的数据。这些增强数据则进一步用来训练解码器。我们在多个序列生成任务上进行了实验,包括对话生成,机器翻译,和摘要生成。在不使用额外数据和额外的模型参数的情况下,我们的方法在所有指标上显著的高于许多强力的基线模型,充分证明了我们的算法的有效性。
https://openreview.net/forum?id=pz1euXohm4H
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“TDSG” 就可以获取《【ICLR2022】序列生成的目标侧数据增强》专知下载链接



登录查看更多
相关内容
Arxiv
0+阅读 · 2022年4月19日
Arxiv
0+阅读 · 2022年4月16日
Arxiv
0+阅读 · 2022年4月15日





相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年4月19日
Arxiv
0+阅读 · 2022年4月16日
Arxiv
0+阅读 · 2022年4月15日