AAAI 2020 提前看 | 三篇论文解读问答系统最新研究进展
机器之心原创
作者:仵冀颖
编辑:H4O
2020 年 2 月 7 日至 12 日,AAAI 2020 将于美国纽约举办。今年 AAAI 共接受了 8800 篇提交论文,其中评审了 7737 篇,接收 1591 篇,接收率为 20.6%。为了向读者们介绍更多 AAAI2020 的优质论文,机器之心组织策划了 AAAI 2020 论文分享,邀请国内外著名大学、研究机构以及工业界的研究人员详细介绍他们发布在 AAAI 2020 的文章,欢迎大家持续关注。



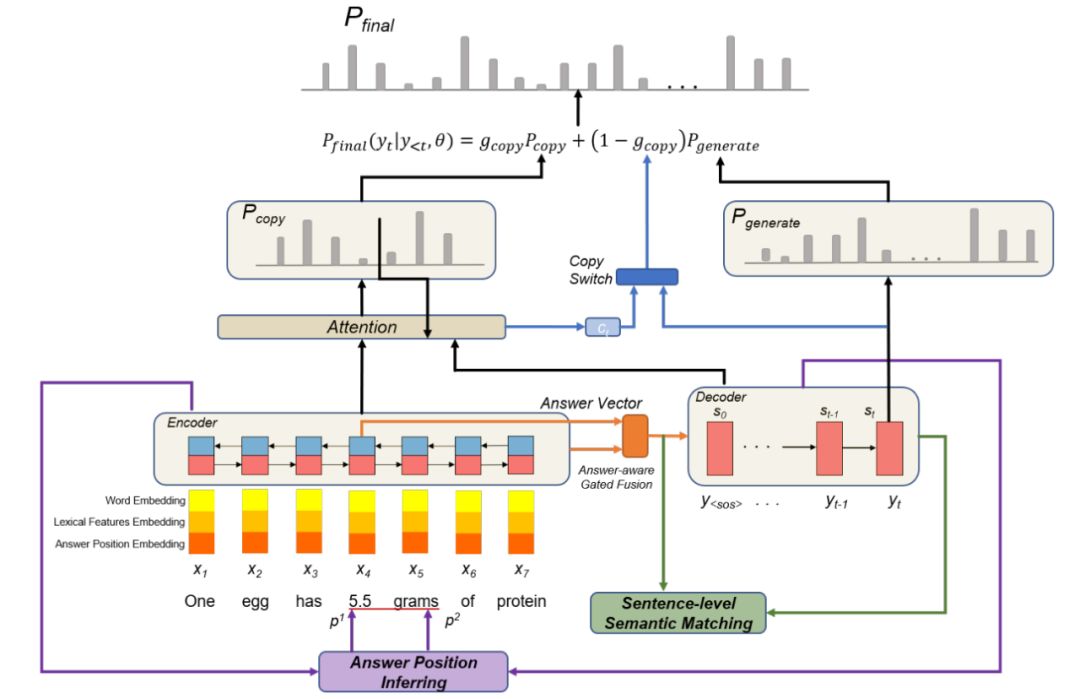
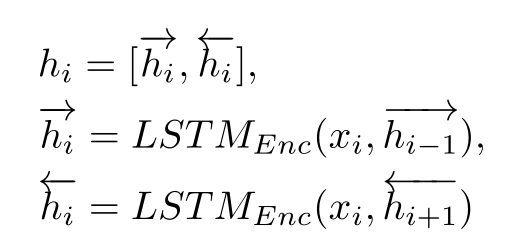
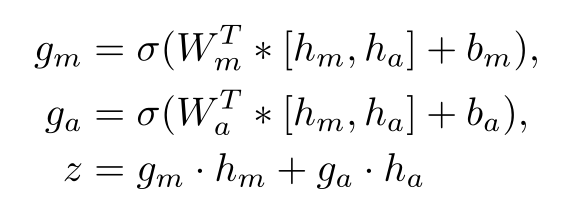
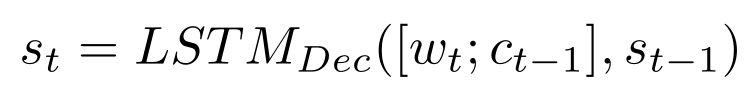
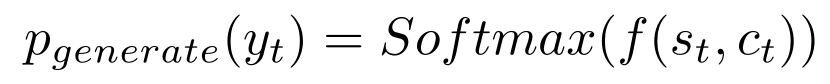
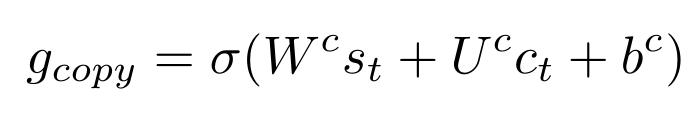
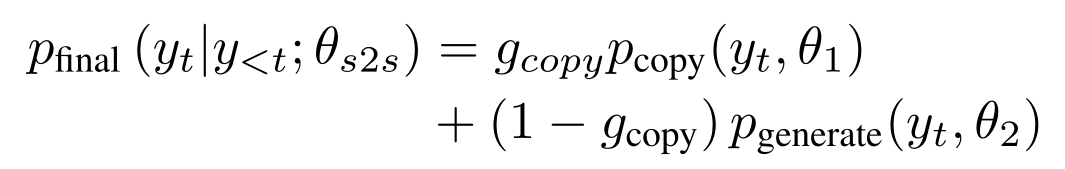
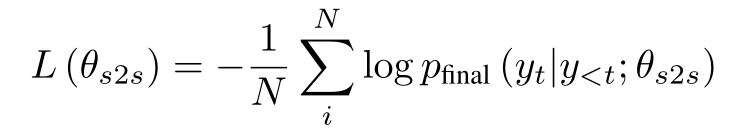
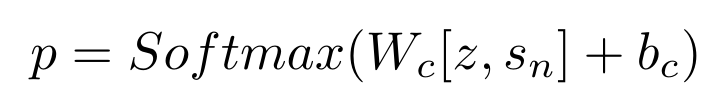
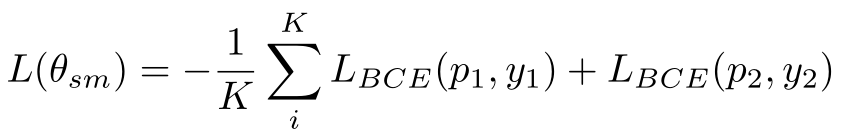
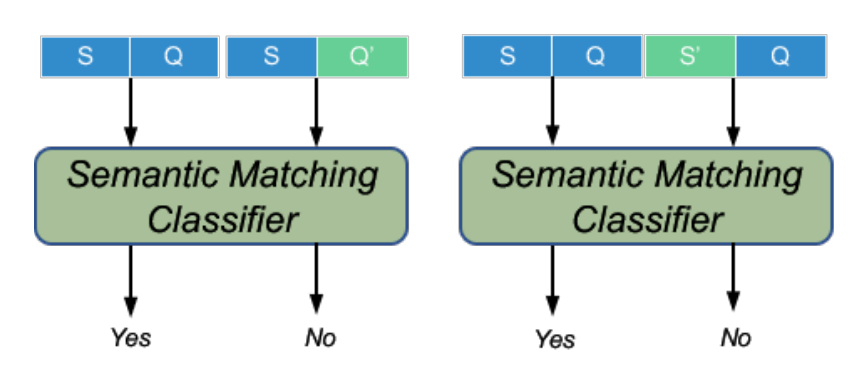
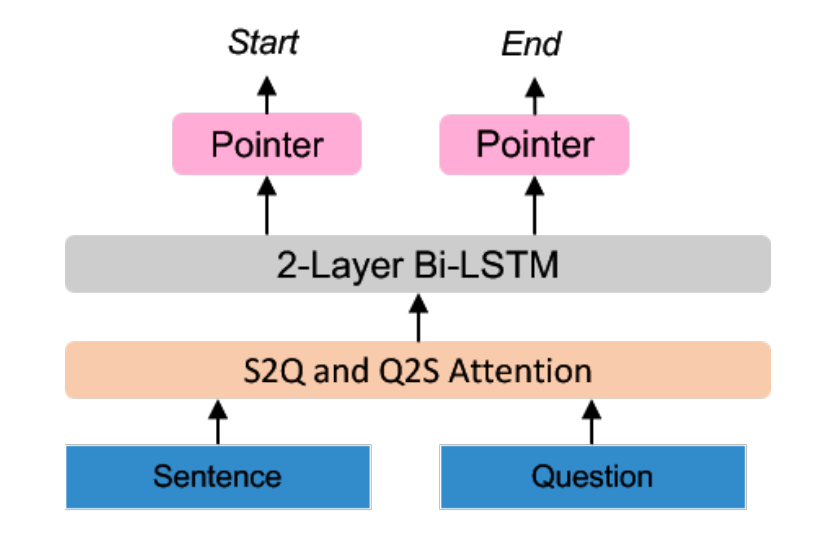
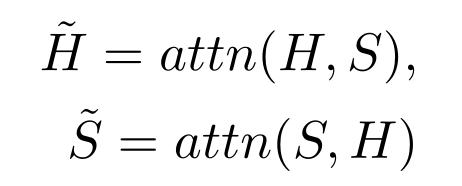
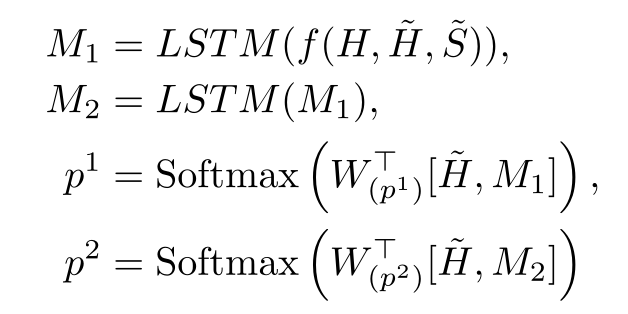
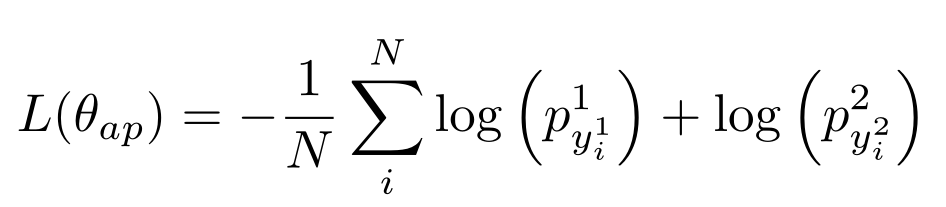
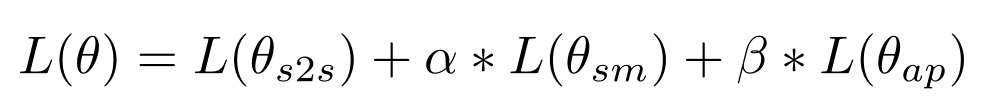


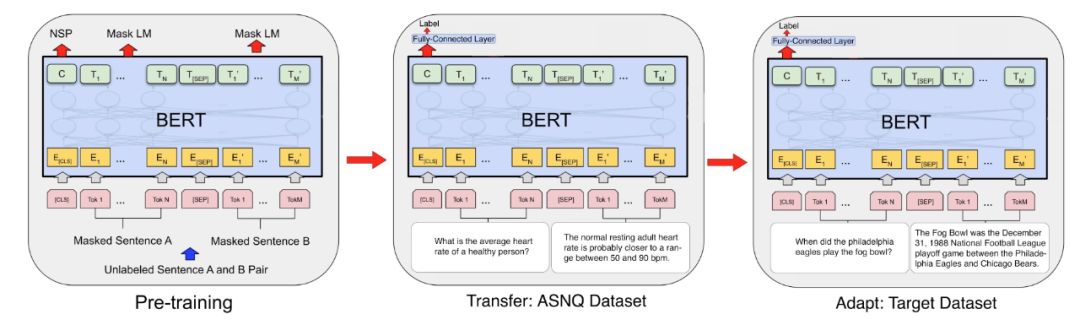
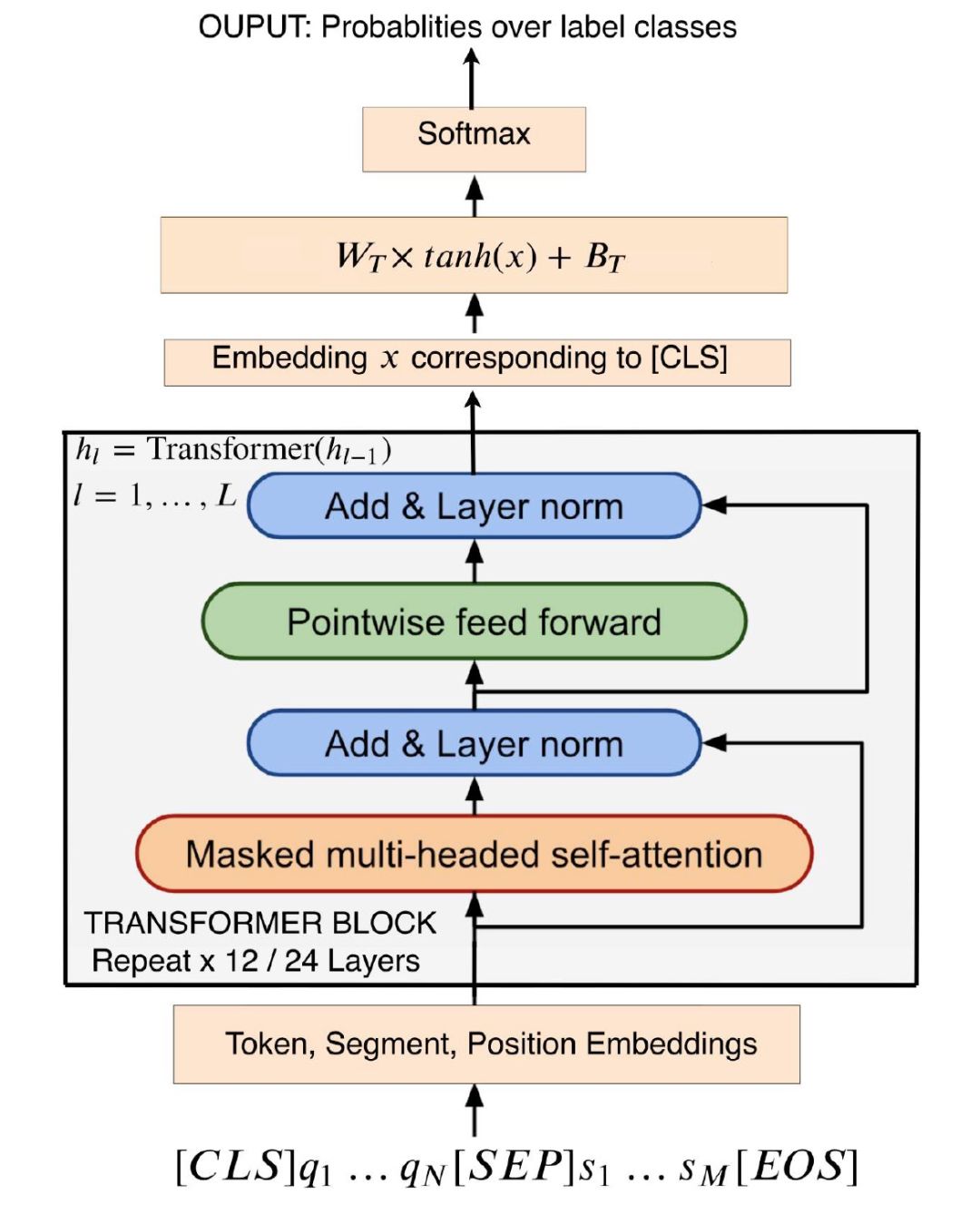
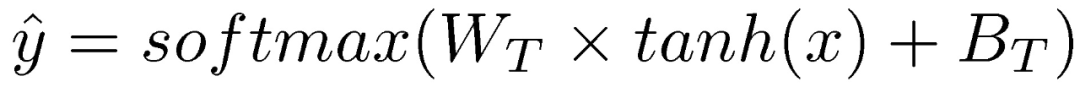
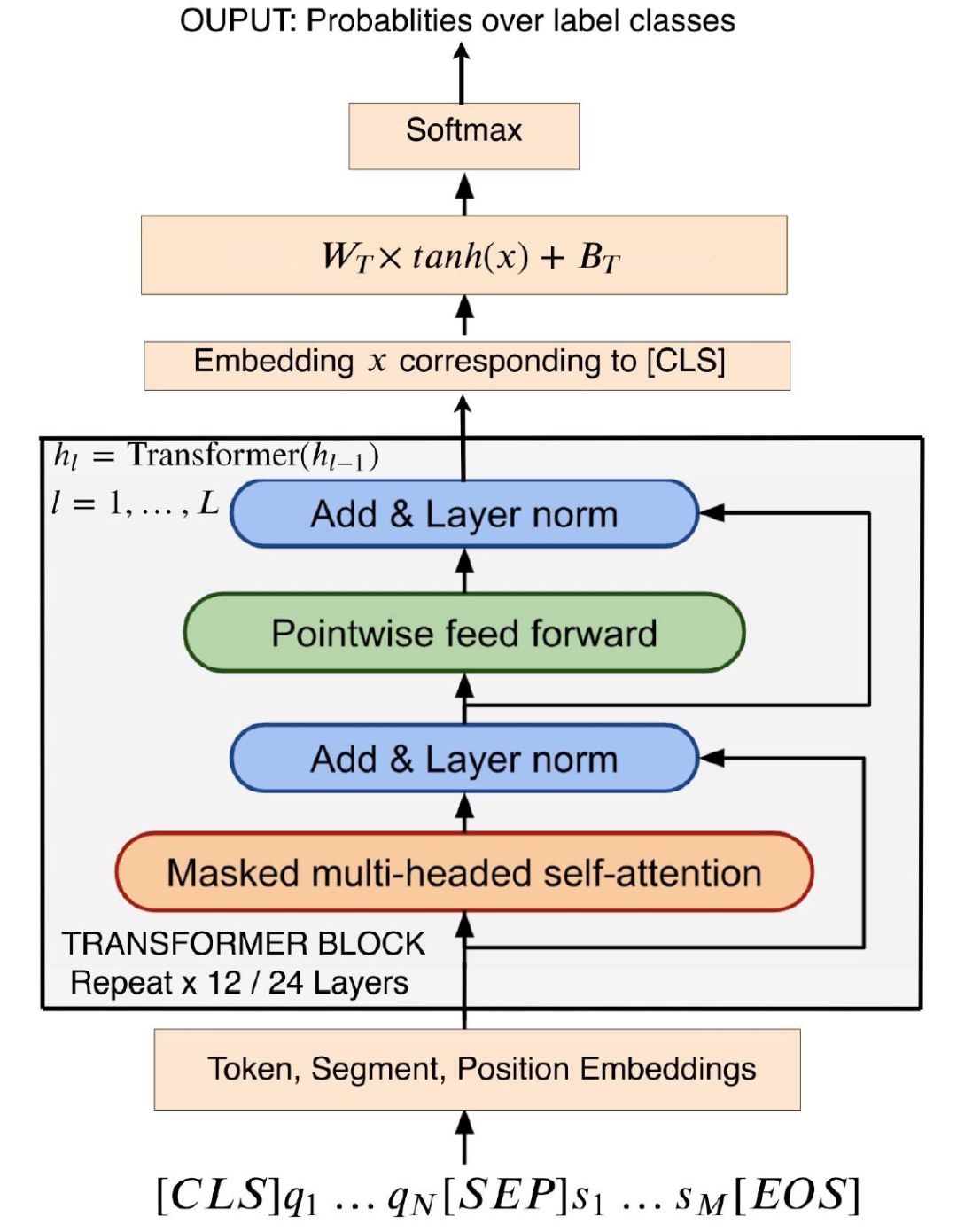
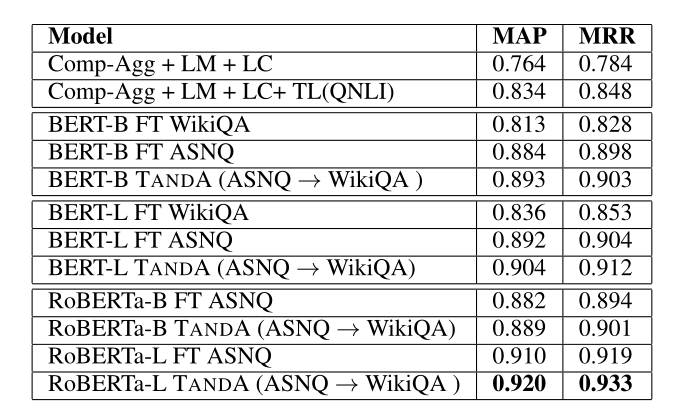
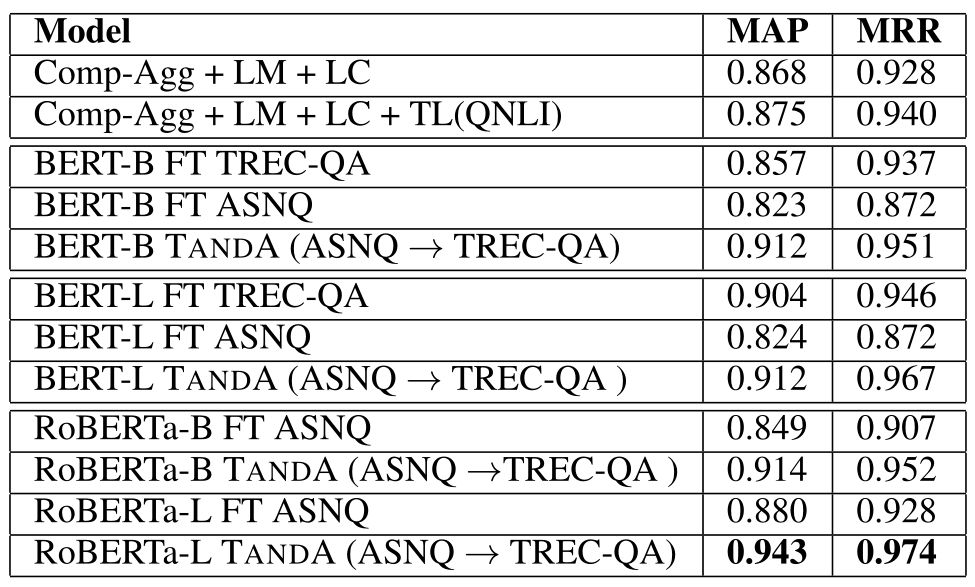
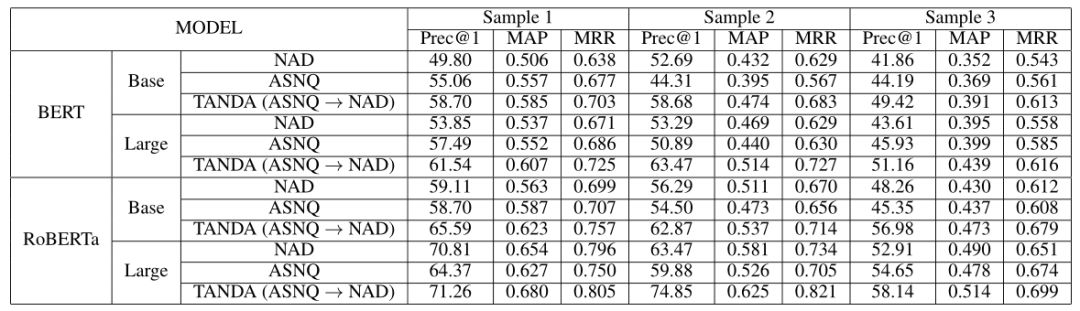
TANDA 的处理方式是在通用数据库和目标域数据库中分别做精调(一次 fine-tuning → 二次 fine-tuning)。这里有一个很直观的质疑,同时在通用数据库和目标数据库中训练+精调是否也可以达到同样的效果且节省处理时间?但是实际上,这样的组合很难优化,因为在精调模型步骤中,处理目标数据与处理通用数据所需要的权重并不相同。作者在后续的实验中专门针对这个问题进行了验证,即在通用、目标数据库中做两次精调处理的效果优于在合并的通用+目标数据库做一次精调处理的效果。



登录查看更多
相关内容




相关VIP内容
相关资讯
相关论文