【首次超越人类】阿里巴巴人工智能机器阅读理解能力创新纪录
近日,阿里巴巴iDST-NLP团队提出的模型SLQA+ (ensemble) (Semantic Learning Question Answering)在斯坦福大学发起的SQuAD(Stanford Question Answering)挑战赛中,取得了第一名并历史性地首次超越人类阅读理解,打败了包括腾讯、微软亚洲研究院、艾伦研究院、科大讯飞与哈工大联合实验室(HFL)、Salesforce、浙江大学、Facebook、谷歌、卡内基·梅隆大学和复旦大学等在内的全球学术界和产业界的研究团队。
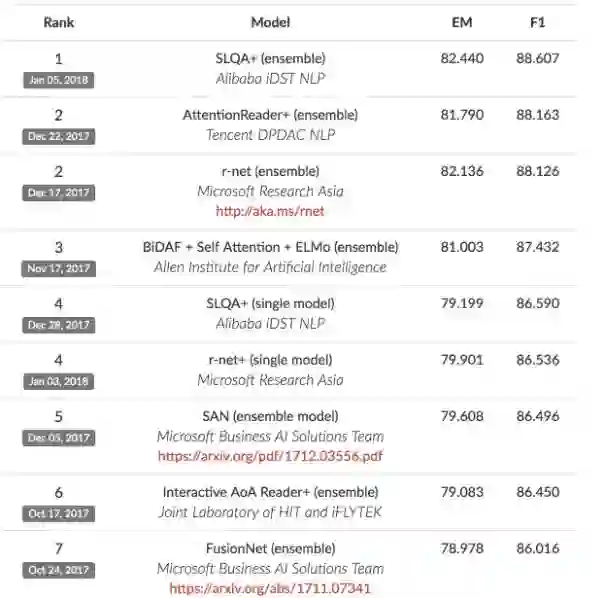
下图是 SQuAD 榜单排名,其中 EM 表示预测答案和真实答案完全匹配,而 F1 用来评测模型的整体性能。人类在 SQuAD 数据集上的性能分别为 82.304 和 91.221,阿里巴巴提出的模型在EM 值上达到82.440超过82.3的人类水平。 在成绩榜单上,可以看到就在不久前的12月28日,同样是阿里巴巴iDST-NLP提交的模型SLQA+ (single model)在单一模型中效果也最好的, 经过短短一周的迭代集成算法版本的模型SLQA+ (ensemble)就取得了超越人类的水平。

在SQuAD官方斯坦福大学挑战赛负责人在推特发文称:
A strong start to 2018 with the first model to exceed human-level performance on SQuAD's EM metricl Next challenge:the F1 metric.where humans still lead by~2.5points!
一个强劲的开始,在2018年机器模型首次在精确匹配超越人类,下一个目标就是要在模糊匹配上超越人类。

▌SQuAD比赛简介

教机器学会阅读是自然语言处理领域的研究热点之一,也是人工智能在处理和理解人类语言进程中的一个长期目标。 SQuAD挑战赛被誉为“机器阅读理解界的ImageNet”,比赛通过众包的方式构建了一个大规模的机器阅读理解数据集(包含10万个问题),可将一篇几百词左右的短文给人工标注者阅读,让标注人员提出最多5个基于文章内容的问题并提供正确答案;短文原文则来源于500多篇维基百科文章。参赛者提交的系统模型在阅读完数据集中的一篇短文之后,再来回答若干个基于文章内容的问题,然后与人工标注的答案进行比对,得出精确匹配(Exact Match)和模糊匹配(F1-score)的结果。
SQuAD是一个持续性的挑战赛,参赛者可以进行调优提交。然后主办方再定期更新成绩。SQuAD向参赛者提供训练集用于模型训练,以及一个规模较小的数据集作为开发集,用于模型的调优和选型。与此同时,SQuAD还提供了一个开放平台供参赛者提交自己的算法,由SQuAD官方利用隐藏的测试集对参赛系统进行评分,并在SQuAD官方确认后将相关结果更新到官网上。
在该轮测试中,阿里巴巴iDST NLP团队提交的系统模型——SLQA+(ensemble) (Semantic Learning Question Answering+,语意理解问答),主要是使用“基于分层融合注意力机制”的深度神经网络模型,大体上分为这几步,第一步做问题文档编码(Question Document Encoding),第二步进行问题文档注意力机制(Question Document Attention),第三步可以进行Document Self-Attention,最后一步就是预测输出层,采取pointer network指导答案区域选择和分类交叉墒损失(Cross Entropy Output Prediction)。这里面最核心的问题就是设计这个Attention或者Fusion函数。阿里巴巴iDST-NLP团队在Attention这部分做得很细致,积累了很多经验,从而在全球自然语言理解研究领域脱颖而出跃居头名。

得益于SQuAD所提供的庞大数据规模,参与该项挑战赛的选手不断地对成绩进行刷新,SQuAD挑战赛也逐步成为行业内公认的机器阅读理解标准水平测试。在今年的ACL大会(自然语言处理领域最顶尖的会议之一)的投稿里,有非常多的论文就是关于这项挑战赛的研究,其影响力可见一斑。从ACL 2017论文主题的可视分析中可以看到,“reading comprehension(阅读理解)”是ACL录取论文中最热门的关键词和任务,广受自然语言处理领域研究人员的关注。
阿里巴巴iDST(数据科学研究院)是阿里巴巴专门负责人工智能的研究机构,隶属于刚刚成立的阿里巴巴达摩院。其中,iDST 自然语言技术 (NLP) 团队致力于学术界、工业界一起创新自然语言技术,团队内的成员普遍拥有10年以上自然语言处理研发经验,40%以上有博士学历(如CMU,伯克利,普林斯顿,清华,北大等)。 团队多次在国际自然语言技术竞赛中取得冠军成绩(2016年CIKM Cup 电商搜索,2017年IJCNLP语法纠错,2017年美国标准计量局信息提取等),在每年的顶级国际会议上都会有一些paper产生。
参考链接:
1. https://www.leiphone.com/news/201707/jWVmsN0JICSOzdkp.html
2. https://www.msra.cn/zh-cn/news/features/machine-text-comprehension-20170508
-END-
专 · 知
人工智能领域主题知识资料查看获取:【专知荟萃】人工智能领域26个主题知识资料全集(入门/进阶/论文/综述/视频/专家等)
同时欢迎各位用户进行专知投稿,详情请点击:
【诚邀】专知诚挚邀请各位专业者加入AI创作者计划!了解使用专知!
请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请扫一扫如下二维码关注我们的公众号,获取人工智能的专业知识!

请加专知小助手微信(Rancho_Fang),加入专知主题人工智能群交流!
点击“阅读原文”,使用专知!





