从800个GPU训练几十天到单个GPU几小时,看神经架构搜索如何进化
选自Medium
作者:Erik Lybecker
机器之心编译
参与:NeuR
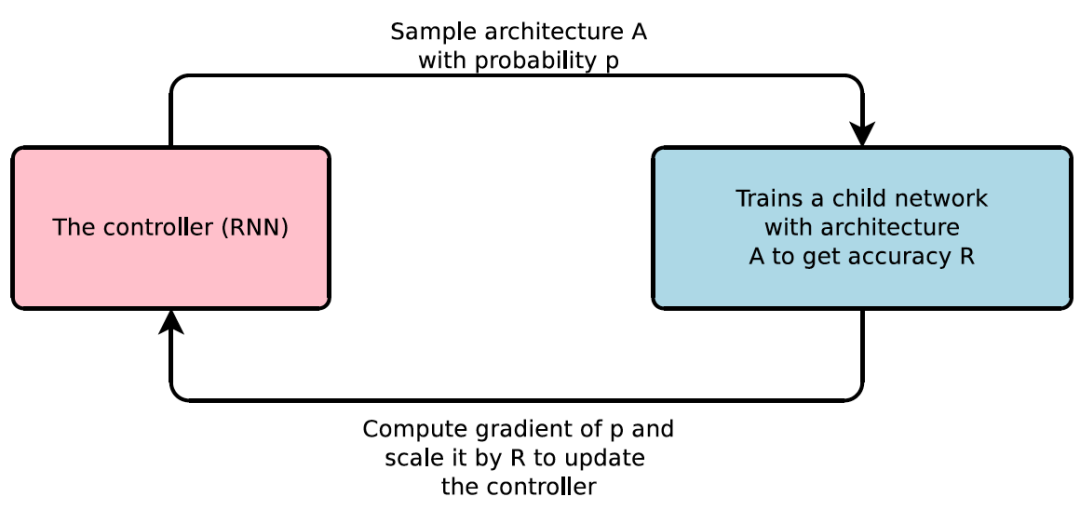
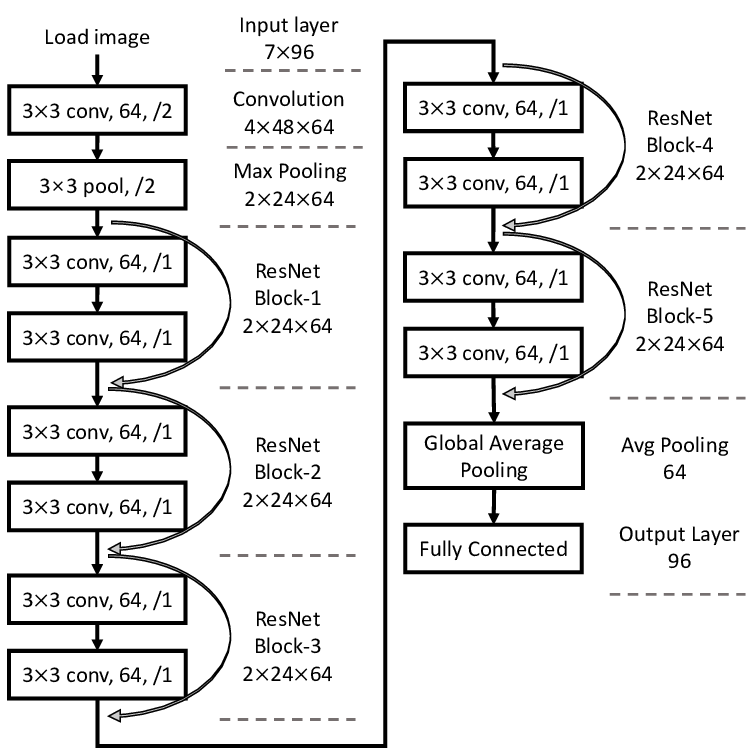
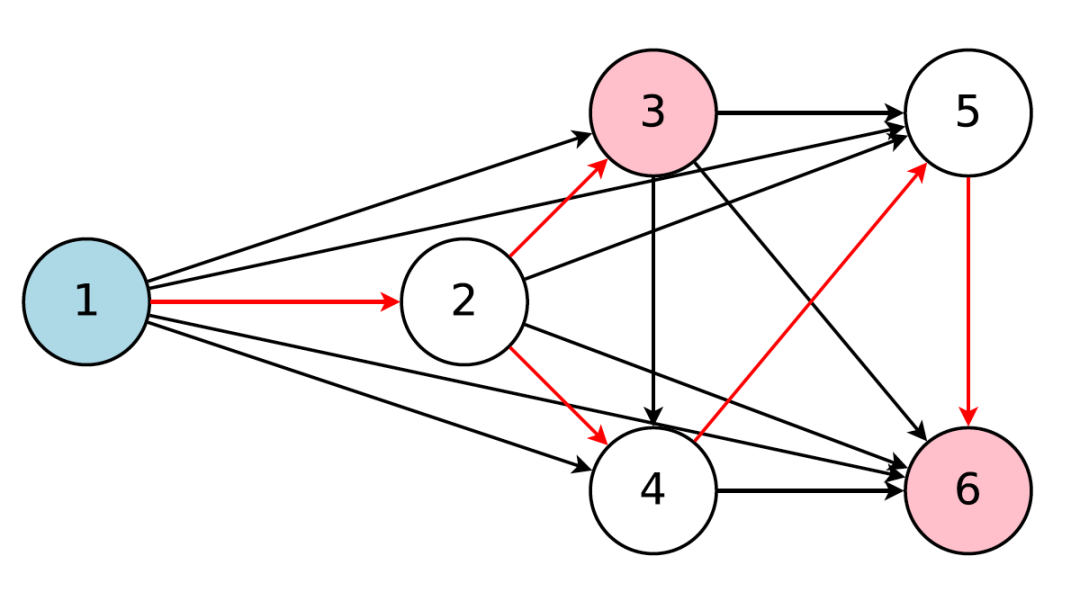
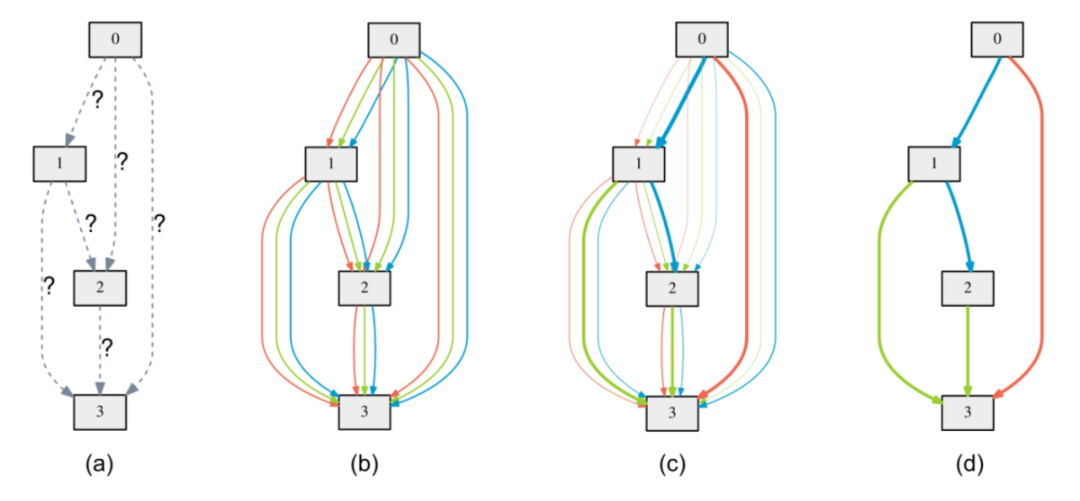
神经架构搜索(NAS)取代了人类「第二阶」的调参工作,使我们能以两层黑箱的方式寻找最优神经网络。这一模式如果能物美价廉地应用,自然是很诱人,要知道「800 个 GPU 训练 28 天」基本不是个人承受得起的。在本文中,作者为我们介绍了 NAS 的进化史,即如何利用多种改进手段,将训练成本压缩到「凡人皆可染指」的程度。

登录查看更多
相关内容
Arxiv
7+阅读 · 2018年5月25日




相关VIP内容
相关资讯
相关论文
Arxiv
7+阅读 · 2018年5月25日