如何帮企业数据库“从马车升级到汽车”?深入解读POLARDB v2.0
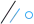


回顾POLARDB 1.0
POLARDB1.0 主要的改进包括采用了计算存储分离的架构,完全兼容MYSQL,性能是原生MySQL的6倍。一个用户集群可以在分钟级弹性扩展到16个计算节点,对业务完全透明的计算和存储分离代理,从库延迟仅毫秒级。存储为分布式块存储,可以弹性扩展至100TB的规模。存储层面采用多副本技术,使得数据库的RPO做到了0,完全没有丢失数据的风险。
POLARDB 1.0 完美的解决了传统数据库的如下痛点:
1、升级硬件需要迁移数据,升级周期长,无法从容应对突如其来的业务高峰。
如何解决:POLARDB的计算节点可以分钟级扩容,任何时刻发现业务量突变即可快速扩容。
2、金融级可靠性要求RPO=0,传统架构使用实例层同步多副本,性能损耗巨大。
如何解决:POLARDB的存储为多副本,底层使用RDMA、Parallel Raft、3D Xpoint等最新的软硬件技术,性能比传统架构最高提升6倍。
3、实例层复制HA架构,主从切换时间长,无法满足金融级连续性要求。
如何解决:POLARDB采用共享存储,主从切换可以做到秒级,同时在计算与业务层之间有一层代理层,代理层可以帮助用户识别计算节点的异常,自动切换,在大多数时候业务感知不到计算节点的切换,保证了业务连续性。
4、传统HA架构采用主从异步复制,切换后从库可能需要重建,耗费资源多,重建时间长,存在长时间单点故障。
如何解决:POLARDB采用共享存储架构,主从切换不需要数据重构。
5、每个只读节点都需要一份与主完全一样的副本,成本高。
如何解决:POLARDB采用共享存储架构,增加计算节点,不需要增加存储副本数,使得整体成本相比传统架构低很多。
6、读写分离采用逻辑REDO复制,主从延迟高。
如何解决:POLARDB的数据存储为共享存储,不需要同步REDO数据,只需要同步REDO的位点,主从延迟在毫秒级。
7、sharding架构没有想象的好,功能阉割、对业务有巨大侵入(限制SQL较多)。
如何解决:POLARDB完全兼容MYSQL,对业务没有任何侵入,用户不需要修改一行代码即可使用POLARDB。
8、TB以上实例备份慢,往往数十小时。
如何解决:POLARDB使用快照备份技术,无论数据量多大,秒级备份
POLARDB 1.0 已经发布两年以来,赢得了很多企业级客户的青睐。POLARDB 1.0已经很完美了,为什么我们还要研发2.0呢?
为什么要研发POLARDB 2.0?
1、用户的去O需求旺盛,却屡试屡败
为什么很多用户去O会屡试屡败呢?
I. 企业有非常严重的历史包袱
企业通常技术栈为Oracle技术栈(团队),适应其他产品的周期长,调头难
迁移如果涉及大量代码改造,周期长、风险高、收益低
通常目标引擎数据库Oracle兼容性非常差,用户需要大量的改造
II. 缺乏有效的迁移方法、工具
迁移改造工作量很难评估,迁移周期很难评估,周期通常非常长,别人的成功去O经验无法复制。
没有有效的数据迁移、数据校验、仿真工具。拍脑袋去O风险非常大。
III. 目标数据库引擎众多、选择难
有些企业为了去O而去O,没有产生业务价值,企业没有动力
目标引擎的可靠性、安全性、扩展性、兼容性、稳定性、性能、可用性等指标可能无法达到用户的需求
2、企业要求数据库既要SQL通用性,又要NoSQL扩展性,还要多模数据处理便捷性。既要高并发、又要实时复杂分析。
然而传统数据库无法满足既要又要还要的需求。
传统数据库往往采用数据同步多份,就像蜘蛛网。不同场景使用不同产品解决的方案。导致的问题非常多,用户苦不堪言:
软硬件成本高,同步延迟,同步数据不一致,
开发成本高,排错复杂等头痛的问题阻碍企业业务发展
3、企业的历史数据像五指山一样 压得喘不过气
企业的数据库通常生命周期非常的长,在整个生命周期的过程中,会产生很多被遗忘的“临时”数据。例如业务的历史数据库,开发或DBA在数据库中操作或产生过的临时数据,这些临时数据历经数年,可能已经无法分辨是属于什么业务的,还要不要被用到,还能不能删除等等。
慢慢就像“鸡肋”一样食之无味、弃之不行。大量“鸡肋”一样的冷数据占用大量空间,又不能删,逐渐成为数据库沉重的包袱。而数据库存储价格昂贵、备份消耗大、大量占空间、恢复慢。

4、专业的GIS处理场景,使用开源版本性能、功能无法满足?
随着物联网、智能终端、移动互联网的发展,越来越多的移动数据接入,应用对GIS数据的处理需求会越来越旺盛,据分析GIS已经是千亿级的市场规模,然而开源的GIS产品可能无法满足日渐丰满的需求。
5、高级DBA太难找,且价格昂贵
高级DBA是大型企业才会设置的职位,价格昂贵、人才缺失。他们的日常可能是喝喝茶、聊聊人生,一切尽在掌握中,问题已经防范于未然。而且这种DBA通常可遇不可求。
大多数的企业通常是SA或开发兼职DBA的工作,他们的日常可能是既要又要还要了。往往是数据库出了事情再来处理,所谓术业有专攻,SA或开发人员处理数据库问题(不管是性能问题还是管理问题),通常时间也可能很久。

POLARDB 2.0 重磅发布新特性
POLARDB 2.0 完全继承了1.0的架构体系,同时兼容了另外两个流行数据库Oracle与PostgreSQL
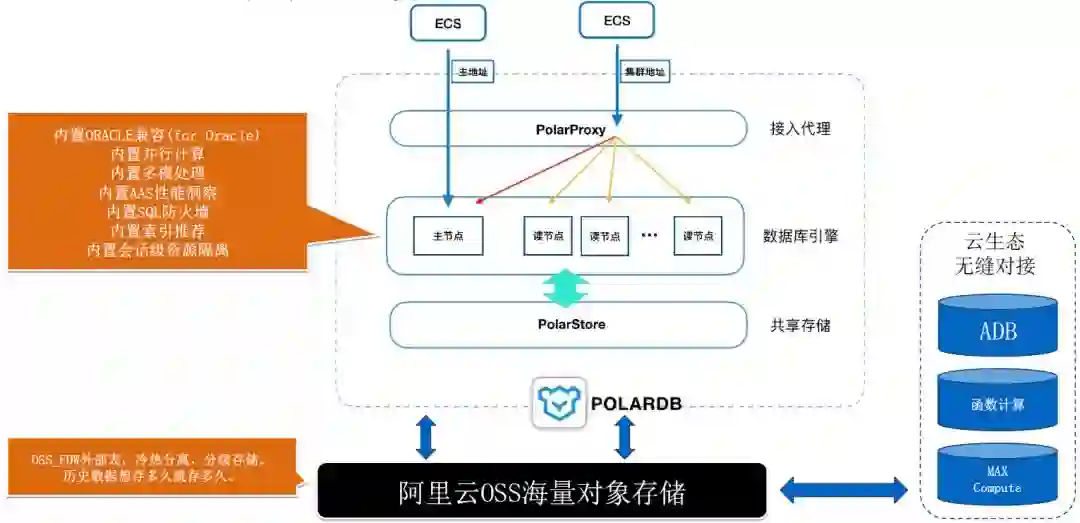
POLARDB for PostgreSQL
完全兼容PostgreSQL,支持计算与存储分离、独立伸缩,存储按量付费。适合中大型企业核心业务。
OLTP+OLAP混合负载
支持混合负载业务,支持百万级高并发,支持并行计算,支持会话级资源隔离。
一个实例,一份数据,同时支持在线业务、实时分析混合业务。
原来用户需要将数据从在线数据库同步到数仓,问题非常多,POLARDB v2.0解决了跨产品数据同步带来的延迟、一致性、成本、使用习惯等问题。
技术指标:
最多支持16个计算节点,每个阶段节点88核;
每计算节点可提供百万级QPS;
支持对业务完全透明的并行计算,平均提速20倍以上,无惧复杂SQL;
多模计算
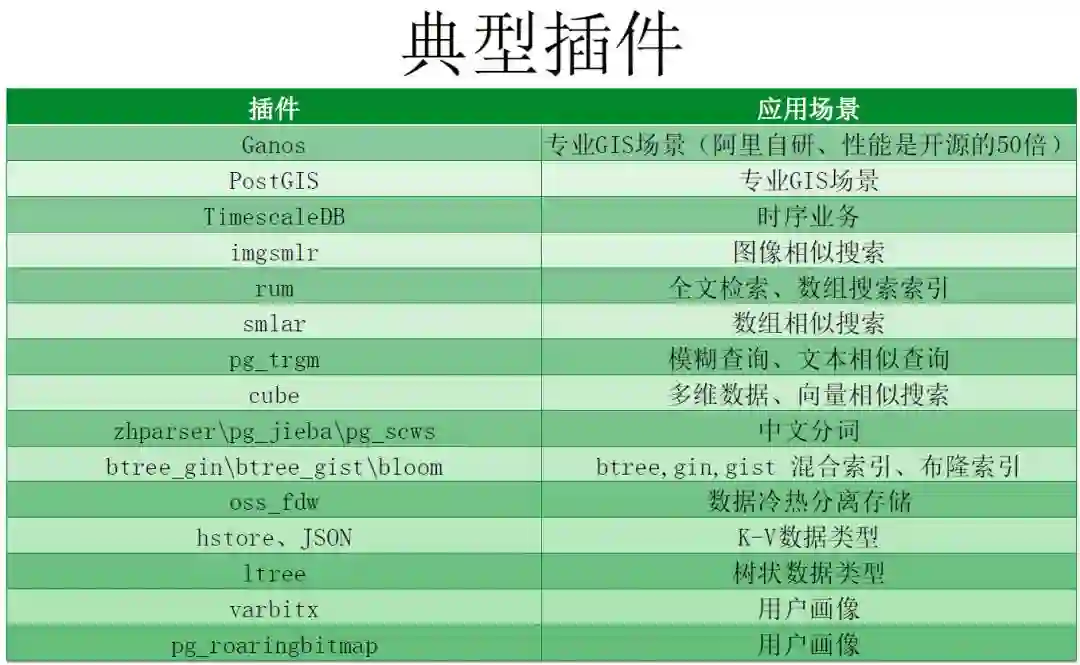
多模计算全面覆盖GIS、时空、时序、全文检索、图像识别、多维查询、向量相似、机器学习。
原来用户需要诸多产品来解决以上不同业务场景遇到的问题,数据需要在各个产品之间同步,异构同步带来延迟、一致性、成本、使用习惯等问题。
POLARDB v2.0新增引擎解决了以上问题。
技术指标:
ganos专业级时空组件,兼容GIS标准,MOD模型比PostGIS 50-100倍性能提升;
内置全文检索、图像识别、多维查询、向量计算、工业时序等多模组件;
内置schemaless、KV等nosql特性;
支持多达8种索引接口(btree,hash,gin倒排索引,GiST空间索引,SP-GiST空间分区索引,BRIN时序索引,rum全文索引,bloom布隆索引),满足各种多模数据的高速检索需求;
POLARDB for Oracle
高度兼容Oracle,降低Oracle迁移风险、缩短迁移周期,助力企业快速替换Oracle,进入云智能时代。
深度兼容Oracle
大幅降低用户去O风险、缩短去O周期。用户去O从数年降低到数周。
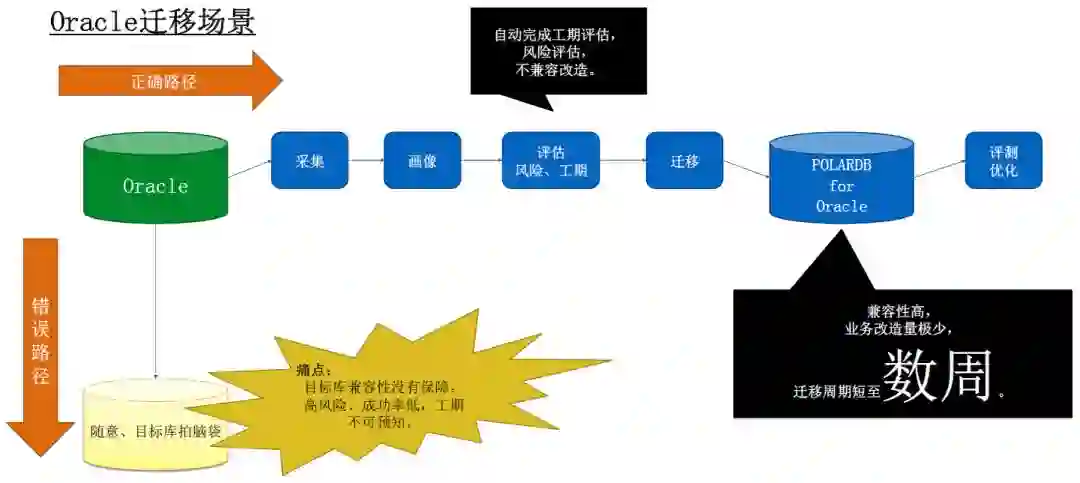
技术指标:
SQL语法、类型、函数、PL/SQL、包、系统视图、OCI、PRO*C等全方位兼容Oracle;
兼容Oracle分区表、异构查询、HINT等高级功能;
支持3155个函数,26个包,317种包内方法,88个系统视图;
智能驾驶
POLARDB v2.0 for Oracle版:
内置SQL防火墙:可以防SQL注入与SQL误操作。解决企业的数据库安全问题。
内置索引推荐功能:是企业数据库优化的好帮手,一键解决索引优化难题
支持AAS性能洞察:在没有专业DBA的情况下,可以一键洞悉宏观、微观业务问题。帮助企业及时发现业务问题。
技术指标:
SQL学习模式,防SQL注入与SQL误操作;
索引推荐,一键解决索引优化难题;
AAS性能洞察,一键洞悉宏观、微观业务问题;
云原生
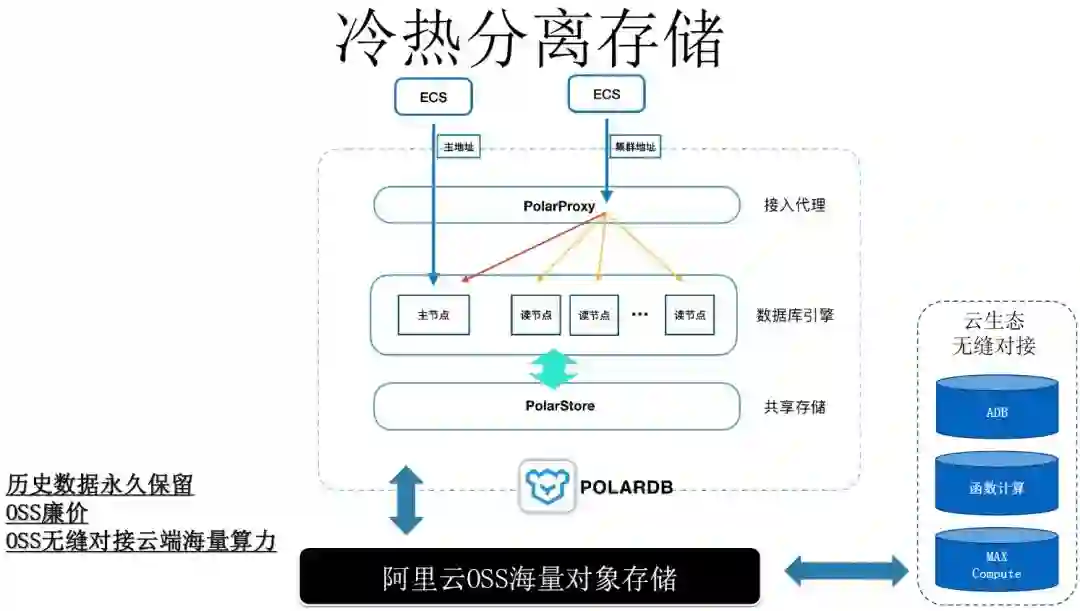
使用POLARDB v2.0替代ORACLE,可以获得POLARDB强大的云原生能力。通过oss_fdw接口可以读写OSS数据,支持冷热分离,对接云端海量算力(函数计算、MAXCompute),获得强大的数据处理能力。企业加快推向DT时代。
技术指标:
OSS外部表,冷热数据分离存储,历史数据想存多久都可以;
无缝对接云端海量算力(ADB、MaxCompute、OSS函数计算等);
POLARDB 2.0 适合哪些业务场景和客户
1、适用场景:
替换Oracle数据库
企业核心数据库
GIS时空数据库
2、适合客户:
企业级客户(党政军、医疗、新零售、新制造、科研机构、金融、互联网、物联网、交通、航空、地图,气象,测绘,LBS,国土,GIS等专业领域)
POLARDB 2.0 关键技术点解读
1、智能驾驶
I. SQL防火墙,防SQL注入,防误操作
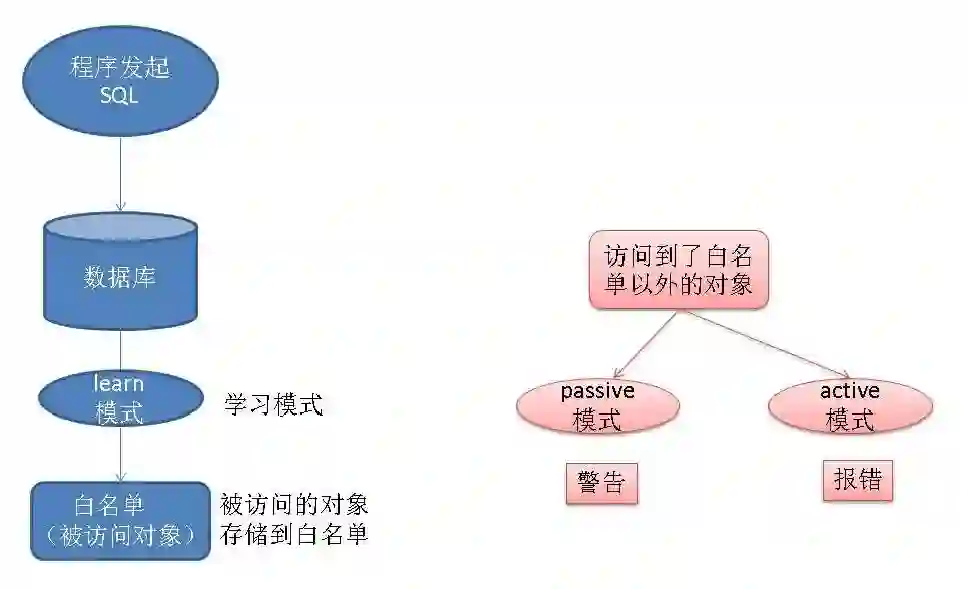
SQL防火墙背后的原理,POLARDB v2.0 for Oracle 通过开启SQL学习模式来学习业务发起的SQL请求,数据库将SQL请求变量化,转换为SQL HASH,存储起来作为SQL白名单。
当学习模式结束后,可以开启permission模式,如果有非白名单内的SQL请求,则发出警告。DBA可以关注到这个警告,判断是否为异常请求。
用户也可以将模式改为强制模式,如果有非白名单内的SQL请求,则会拒绝这样的请求,从而根本上防止SQL注入,防止用户误操作。
除此以外,POLARDB v2.0 forOracle 还支持规则配置,例如可以拒绝不带WHERE条件的DML请求,拒绝WHERE 条件始终为TRUE的DML请求,从而防止SQL注入攻击或人为的误操作。
II. 索引推荐,即使是数据库小白用户,也能一键优化数据库
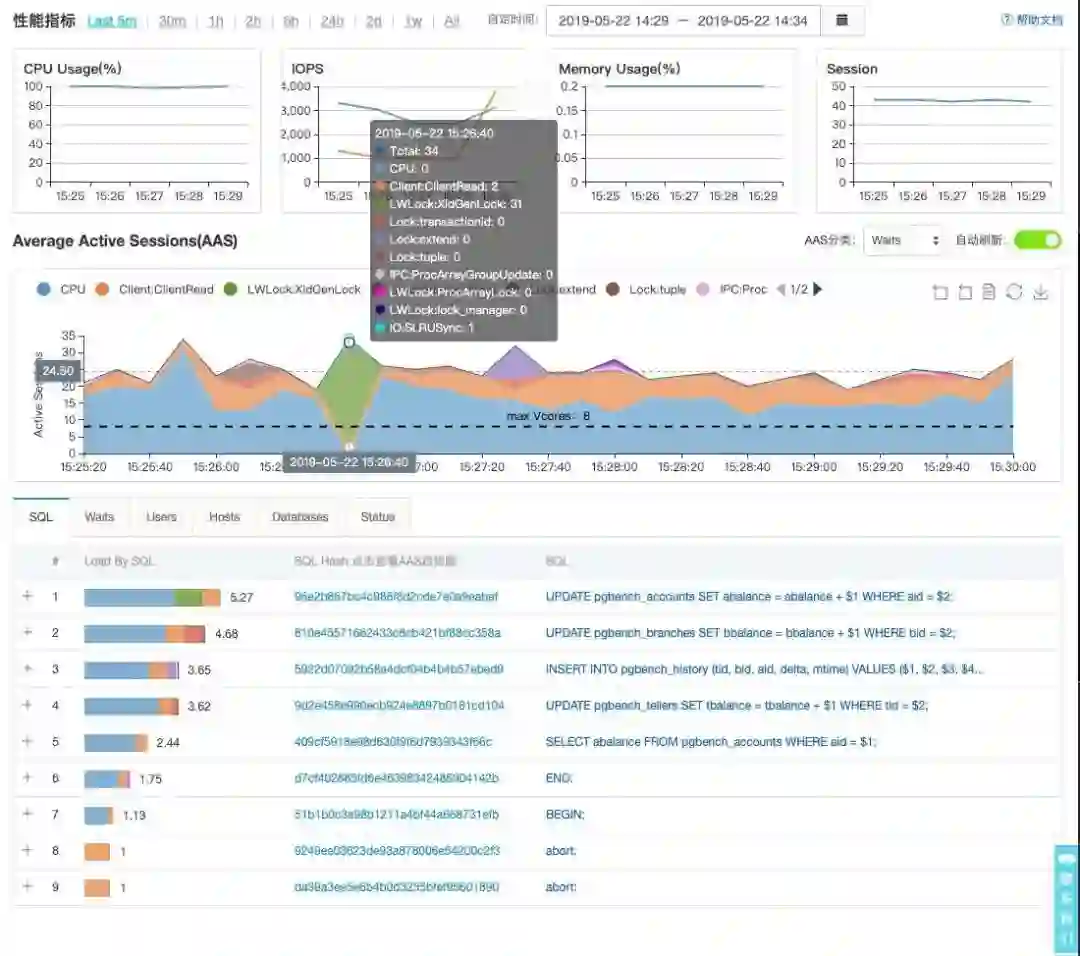
用户可以在会话中开启索引推荐的模块,一旦开启,这个会话发起的SQL请求会被后台分析,在运行一段时间后,调用索引推荐函数,我们可以看到数据库已经对到当前会话执行过的SQL进行了索引推荐的优化。
III、性能洞察:这个功能是非常强大的,通过等待时间的采集,打点,我们可以观察到数据库在过去的任意时刻是否遇到性能瓶颈,性能瓶颈是什么?即使企业中没有专业的DBA,也能轻而易举的发现数据库的性能问题。
2、并行计算,多达几十种场景,平均20倍性能提升
并行计算解决了复杂查询慢的问题,在企业中,我们通常会有数据分析的需求,以往由于关系数据库的分析计算能力差,需要将关系数据库的数据同步到大数据平台进行分析,而同步会有延迟、会有成本开销、会有同步问题等等。用户苦不堪言。
POLARDB v2.0 内置了并行计算的功能,并行度会根据SQL的成本(复杂度的衡量)来规划,复杂SQL会启用并行计算,同时并行度也是自动计算的。使得用户不需要将数据同步到外部,也能实现实时分析。
POLARDB v2.0 的并行计算覆盖了数十种场景,实测性能提升平均20倍以上。
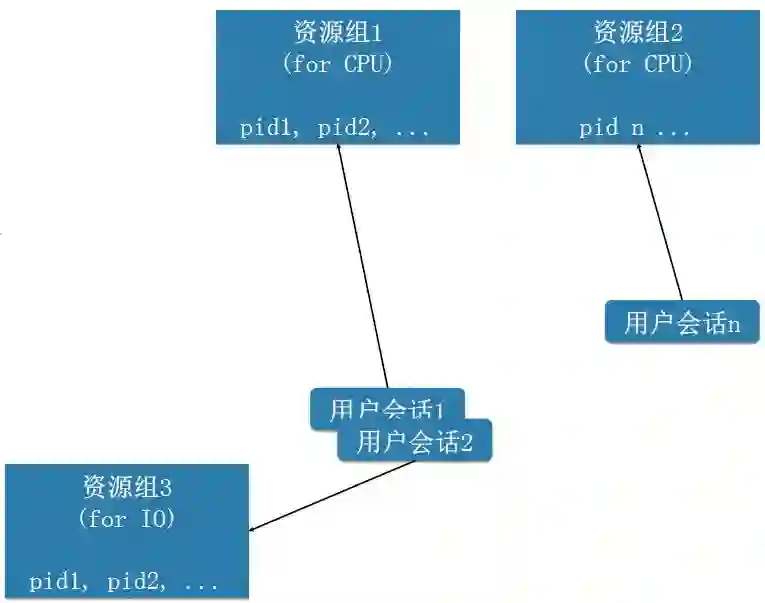
3、会话级资源隔离
当用户有OLTP业务同时混合了OLAP业务时,OLTP的并发高,要求的RT低。OLAP的并发低,但是对计算要求很高,跑OLAP业务会占用大量的资源。
POLARDB 支持16个计算节点,我们可以采用不同的计算节点来隔离OLAP,OLTP业务。
但是,如果用户的TP、AP业务在同一个计算节点时,还有更好的方法,会话级资源隔离,目前支持CPU和IO的资源隔离。
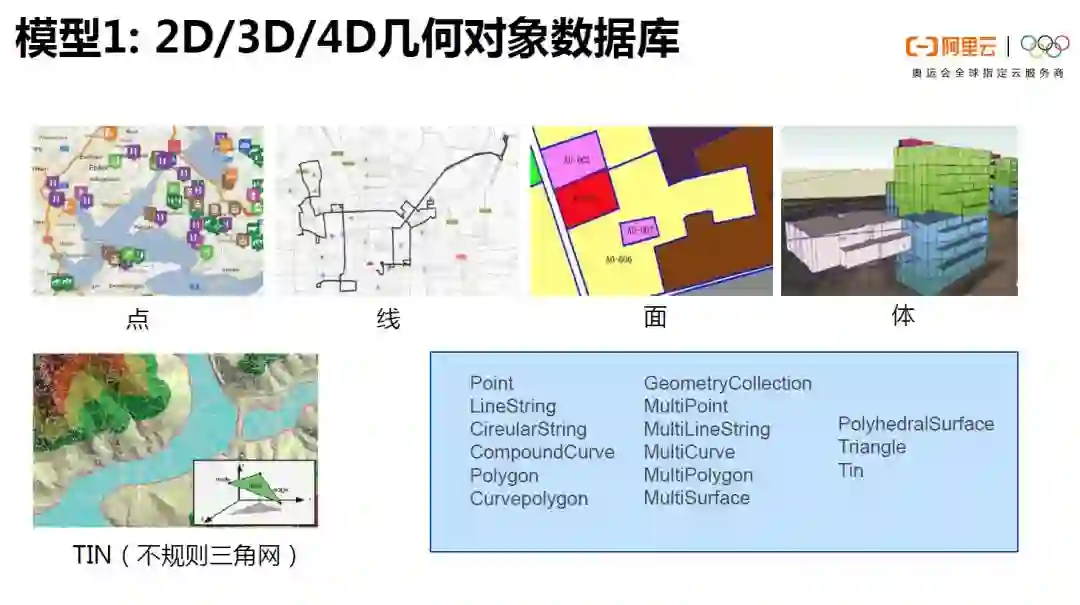
4、ganos时空多模组件
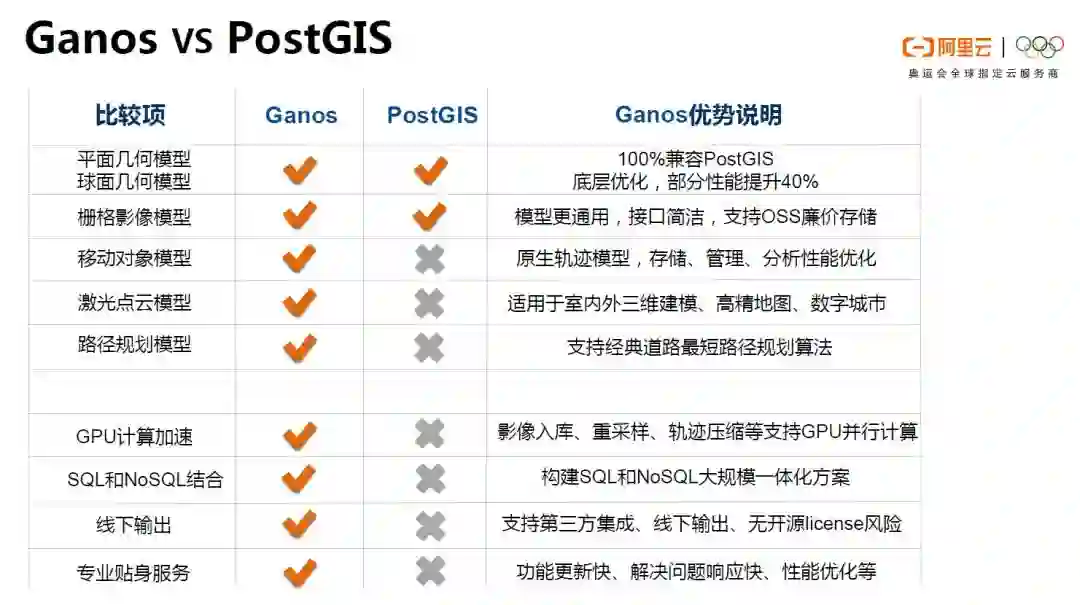
ganos是阿里巴巴自研的3S引擎,兼容GIS标准,支持平面几何模型、球面几何模型、栅格模型、时空轨迹模型、点云模型、拓扑网络模型等。

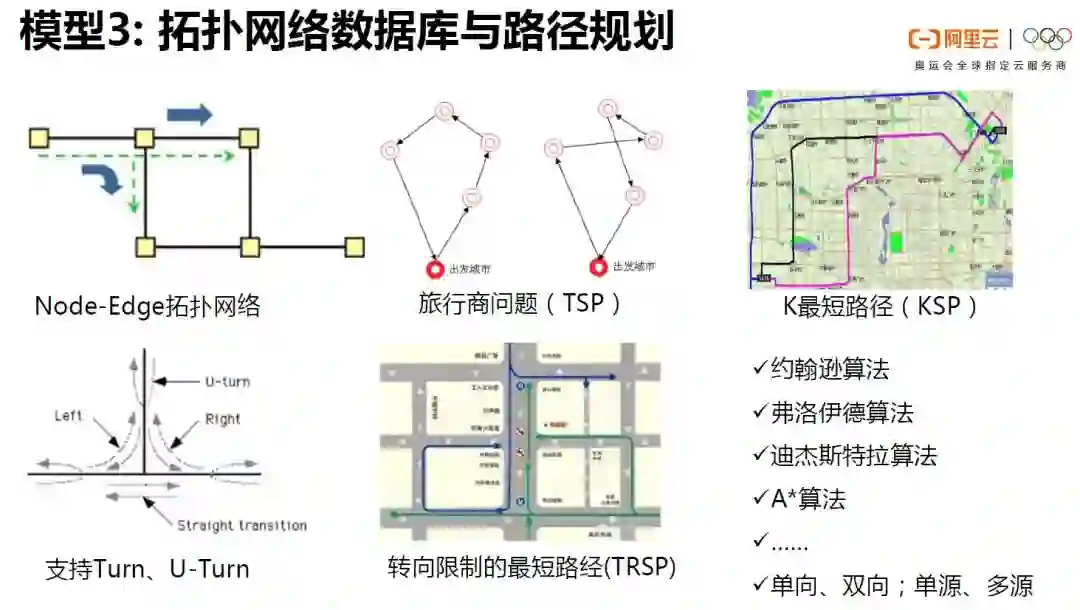


ganos相比开源GIS的优势也非常明显。
5、云原生的冷热分离
POLARDB v2.0 可以将OSS作为数据存储,用户通过创建oss_fdw外部表插件,建立OSS外部表,可以将数据写入OSS,也可以从OSS读取。采用标准的SQL接口。
因此对于访问较少的冷数据,用户可以将数据存储在OSS,降低数据库的分布式块存储的成本,得到无限的存储空间。
同时由于OSS与云端的MAXCompute, ADB, 函数计算等都是打通的,所以当用户是非常大型的企业,需要对多个数据库实例进行横向的大数据分析时,OSS_FDW无疑是一种非常好的数据共享方法,将多个实例的数据通过OSS进行分析,打通大计算。
6、为什么POLARDB 2.0支持多模
I. 传统数据库通常只支持1种索引,而POLARDB v2.0 支持8种索引:
btree、hash、gin、brin、gist、spgist、bloom、rum
II. 传统数据库通常仅支持几种数据类型,而POLARDB v2.0支持大量数据类型
时间、字符串、数值;货币;字节流;比特;枚举;布尔;几何;网络;全文检索
UUID;JSON;XML;数组;复合;范围;域;图像;树;多维立方;
GIS;rb;HLL;K-V;还支持扩展类型
III. POLARDB v2.0还支持了非常多的多模插件,大幅度的帮助用户提高开发生产效率。
小结
POLARDB v2.0 for Oracle,高度兼容Oracle,同时支持了SQL防火墙、自动索引推荐、性能洞察、资源隔离等智能驾驶功能,支持了冷热分离的云原生能力,解决了企业去O难题,帮助企业快速去O。
POLARDB v2.0 for PostgreSQL,完全兼容PostgreSQL,支持并行计算,混合负载,GIS时空等多模计算,具备冷热分离的云原生能力,是企业级客户(党政军、医疗、新零售、新制造、科研机构、金融、互联网、物联网、交通、航空、地图,气象,测绘,LBS,国土,GIS等专业领域)核心数据库上云的很好选择。
公测申请方法

扫描上方二维码⬆️或通过下方网址均可申请
https://page.aliyun.com/form/act977150651/index.htm
欢迎加入POLARDB 技术群


全球唯一深度兼容Oracle的云原生数据库——POLARDB V2.0重磅发布!6月19日 15:00-17:00,诚邀您和我们一起见证计算和存储分离架构提供的澎湃性能和业务场景!
快来点击“阅读原文”
报名观看吧!
时间:2019年6月19日 15:00-16:00

阿里巴巴数据库技术
微信:alibabadba

分享数据库前沿
解构实战干货
长按二维码关注