【入门】想实现DCGAN?从制作一张门票谈起!
选自FreeCodeCamp
作者:Thalles Silva
来源:机器之心
生成对抗网络因为优雅的创意和优秀的性能吸引了很多研究者与开发者,本文从简洁的案例出发详解解释了 DCGAN,包括生成器的解卷积和判别器的卷积过程。此外,本文还详细说明了 DCGAN 的实现过程,是非常好的实践教程。
热身
假设你附近有个很棒的派对,你真的非常想去。但是,存在一个问题。为了参加聚会,你需要一张特价票——但是,票已经卖完了。
等等!难道这不是关于生成对抗网络(Generative Adversarial Network)的文章吗?是的,没错。但是请先忍忍吧,这个小故事还是很值得一说的。
好的,由于派对的期望值很高,组织者聘请了一个有资质的安全机构。他们的主要目标是不允许任何人破坏派对。为了做到这一点,场地的入口安排了很多警卫,检查每个人门票的真实性。
你并没有什么武打天赋能硬闯进去。所以,唯一的途径是通过一张非常有说服力的假票瞒天过海。
不过,这个计划存在一个很大的问题——你没见过真票长什么样。
即使根据自己的创造力设计了一张票,你是不可能在第一次尝试时能骗过警卫的。此外,如果没有一张足够真实的派对假票,带着自己做的假票进门无异于自投罗网。
为了解决这个问题,你决定打电话给你的朋友 Bob 帮你点忙。
Bob 的任务非常简单。他将用你做的假票尝试混进派对中去。如果他被拒之门外,他将为你带回有关票面样式的有用提示。
基于这个反馈,你可以再试着做一张新版假票交给 Bob,让他再试一次。这个过程不断重复,直到你能伪造一张完美的假票。
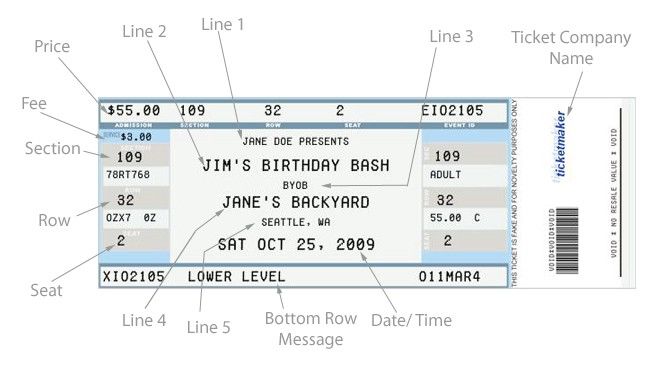
这个派对非去不可!实际上,上图是从一个假票生成器网站上复制下来的!
撇开「假票事件」,这几乎是生成对抗网络(GAN)所做的全部工作。
目前,GAN 的大部分应用都在计算机视觉领域。其中的一些应用包括训练半监督分类器,并利用低分辨率的图像生成高分辨率的图像。
本文通过亲手处理生成图像的问题来介绍 GAN。你可以在以下地址找到本文的 Github 代码。
项目地址:https://github.com/sthalles/blog-resources/blob/master/dcgan/DCGAN.ipynb
生成对抗网络
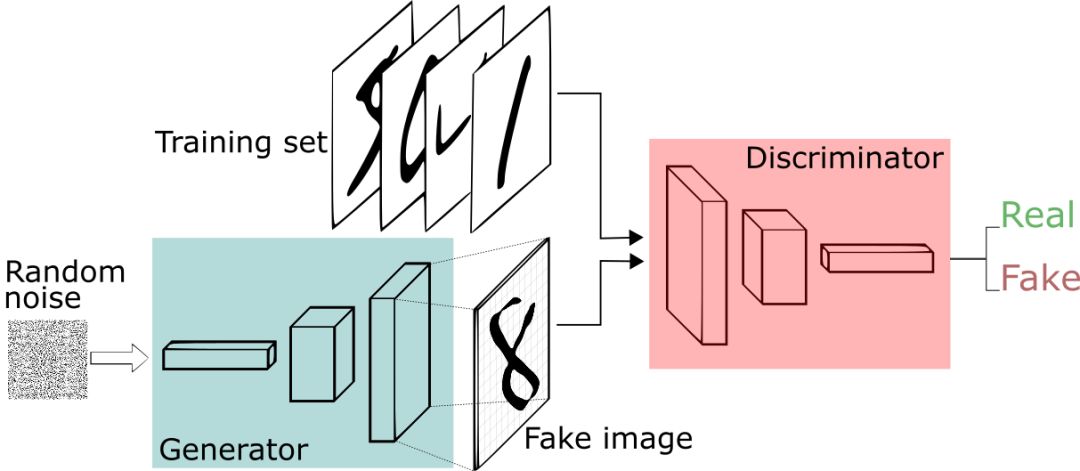
生成式对抗网络框架
GAN 是由 Goodfellow 等人设计的生成模型(参见论文
Generative Adversarial Networks,2014,Ian J. Goodfellow et al.)。在 GAN 的设计中,由神经网络表示的两个可微函数被锁定在这场极大极小博弈中。这两个参与者(即生成器和判别器)在这个框架中扮演着不同的角色。
生成器(generator)试图产生来自某种概率分布的数据。换句话说,它代表着上述故事中的你——企图生成派对的门票。
判别器(discriminator)像一个法官,它可以判定输入是来自生成器还是真正的训练集。这也就代表着故事中的警卫——将你的假票和真票进行对比,找出设计的缺陷。
我们用带有批归一化的 4 层卷积网络构建生成器和判别器,训练该模型将生成 SVHN 和 MNIST 图像。
总而言之,游戏规则如下:
生成器试图使判别器发生错误判断的概率最大化。
判别器引导生成器产生更逼真的图像。
在理想的平衡状态中,生成器将捕获训练数据的一般性分布。因此,判别器将总是不能确定其输入是否真实。
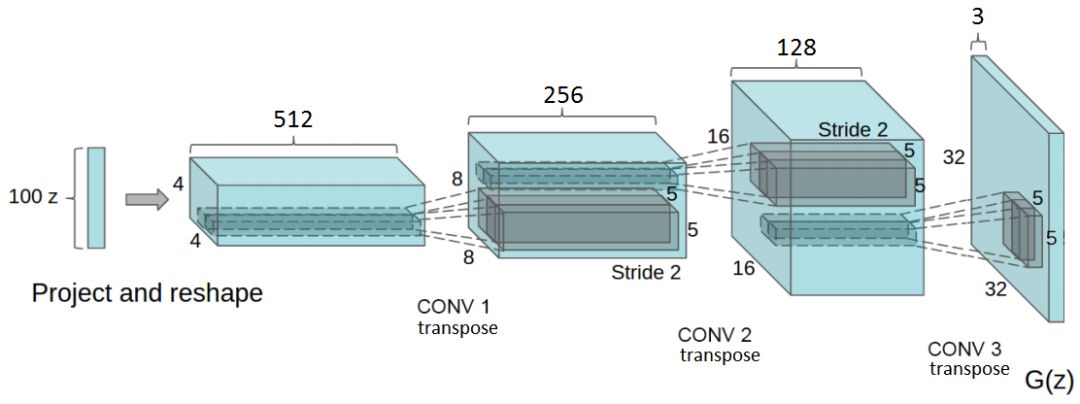
以上改编自 DCGAN 论文,是生成器网络的实现方式。请注意全连接层和池化层并不存在。
在 DCGAN 论文(Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks)中,作者描述了深度学习技术的结合,这是训练 GAN 的 关键。这些技术包括:(i)全卷积网络和(ii)批归一化(BN)。
前者强调 Strided Convolutions(以替代池化层):增加和减少特征空间的维度。而后者归一化特征向量,从而显著地减少多层之间的协调更新问题。这有助于稳定学习,并能帮助处理糟糕的权重初始化问题。
不必多说,让我们深入实施细节,在细节中同时多谈谈 GAN。下面,我们展示了深度卷积生成对抗网络(DCGAN)的实现方法。我们遵循 DCGAN 论文中描述的实践方法,使用 Tensorflow 框架进行实现。
生成器
生成器网络有 4 个卷积层。除输出层外,其他所有层后都紧接着批归一化(BN)和线性修正单元(ReLU)进行激活。
它将随机向量 z(从正态分布中抽取)作为输入。把向量 z 进行四维重塑后,将其送入生成器,启动一系列上采样层。
每个上采样层都代表一个步长为 2 的转置卷积运算。转置卷积运算与常规卷积运算类似。
一般而言,常规卷积运算的层从宽而浅到窄而深。而转置卷积运算恰好相反:其层从窄而深到宽而浅。
转置卷积运算操作的步长定义了输出层的大小。在使用'same'填充、步长为 2 时,输出特征图的尺寸将是输入层大小的两倍。
这是因为,每当我们移动输入层中的一个像素时,我们都会将输出层上的卷积核移动两个像素。换句话说,输入图像中的每个像素都被用于在输出图像中绘制一个正方形。
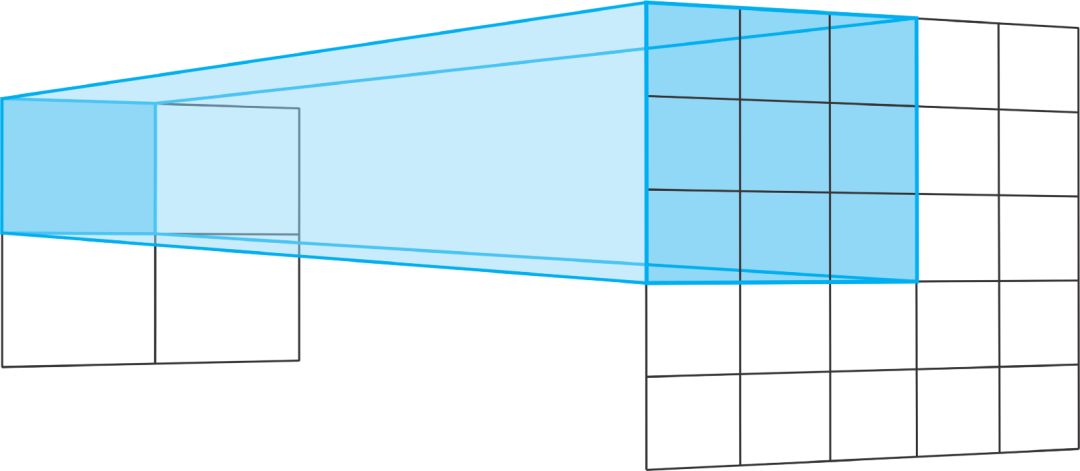
将 3x3 的卷积核在 2x2 的输入上进行步长为 2 的转置卷积运算,相当于将 3x3 的卷积核在 5x5 的输入上进行步长为 2 的常规卷积运算。对于二者,均使用不带零填充的「VALID」。
简而言之,窄而深的的输入向量是生成器的开始。在每次转置卷积之后,z 变得更加宽而浅。所有转置卷积运算都使用 5x5 大小的卷积核,其深度从 512 逐渐降到 3——此处的 3 代表 RGB 彩色图像的 3 个通道。
def transpose_conv2d(x, output_space):
return tf.layers.conv2d_transpose(x, output_space,
kernel_size=5, strides=2, padding='same',
kernel_initializer=tf.random_normal_initializer(mean=0.0,
stddev=0.02))
最后一层输出一个 32x32x3 的张量并使用 tanh 函数将值压缩在 -1 和 1 之间。
最终的输出尺寸由训练集图像的大小定义。在这种情况下,如果对 SVHN 进行训练,生成器将产生 32x32x3 的图像。但是,如果对 MNIST 进行训练,则会生成 28x28 的灰度图像。
最后,请注意,将输入矢量 z 传送到生成器前,需要将其缩放到 -1 到 1 的区间,以遵循 tanh 函数的使用规则。
def generator(z, output_dim, reuse=False, alpha=0.2, training=True):
"""
Defines the generator network
:param z: input random vector z
:param output_dim: output dimension of the network
:param reuse: Indicates whether or not the existing model variables should be used or recreated
:param alpha: scalar for lrelu activation function
:param training: Boolean for controlling the batch normalization statistics
:return: model's output
"""
with tf.variable_scope('generator', reuse=reuse):
fc1 = dense(z, 4*4*512) # Reshape it to start the convolutional stack
fc1 = tf.reshape(fc1, (-1, 4, 4, 512))
fc1 = batch_norm(fc1, training=training)
fc1 = tf.nn.relu(fc1)
t_conv1 = transpose_conv2d(fc1, 256)
t_conv1 = batch_norm(t_conv1, training=training)
t_conv1 = tf.nn.relu(t_conv1)
t_conv2 = transpose_conv2d(t_conv1, 128)
t_conv2 = batch_norm(t_conv2, training=training)
t_conv2 = tf.nn.relu(t_conv2)
logits = transpose_conv2d(t_conv2, output_dim)
out = tf.tanh(logits) return out
判别器
判别器也是一个带有 BN(输入层除外)的 4 层 CNN,并使用 leaky ReLU 进行激活。在基本的 GAN 结构中,有许多激活函数能正常工作。但是 leaky ReLU 尤为受欢迎,因为它可以使得梯度在结构中更容易传播。
常规 ReLU 函数通过将负值截断为 0 起作用。这可能有阻止梯度在网络中传播的效果。然而,在输入负值时,leaky ReLU 函数值不为零,因此允许一个小的负值通过。也就是说,该函数计算的是输入特征和一个极小因子之间的最大值。
def lrelu(x, alpha=0.2):
# non-linear activation function
return tf.maximum(alpha * x, x)
Leaky ReLU 试图解决 ReLU 的梯度消失问题。如果神经元陷入这种情况,即对任意输入,ReLU 单元总是输出为 0,就会出现梯度消失。对于这些情况,梯度完全消失,网络无法进行反向传播。
这对于 GAN 来说尤其重要。这是因为,生成器学习的唯一方式是接收判别器的梯度。
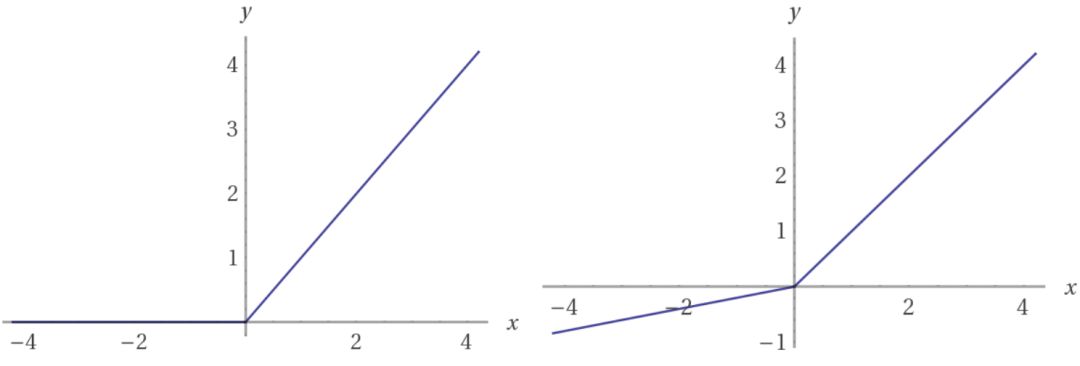
激活函数:ReLU(左),Leaky ReLU(右)。请注意,当 x 为负值时,Leaky ReLU 有一个很小的斜率。
一开始,判别器会收到一个 32x32x3 图像张量。与生成器相反,判别器执行一系列步长为 2 的常规卷积运算。每经过一次卷积,特征向量的空间维度就会减少一半,而训练的卷积核数量会加倍。
最后,判别器需要输出概率。为此,我们在最后一层使用 Sigmoid 激活函数。
def discriminator(x, reuse=False, alpha=0.2, training=True):
"""
Defines the discriminator network
:param x: input for network
:param reuse: Indicates whether or not the existing model variables should be used or recreated
:param alpha: scalar for lrelu activation function
:param training: Boolean for controlling the batch normalization statistics
:return: A tuple of (sigmoid probabilities, logits)
"""
with tf.variable_scope('discriminator', reuse=reuse): # Input layer is 32x32x?
conv1 = conv2d(x, 64)
conv1 = lrelu(conv1, alpha)
conv2 = conv2d(conv1, 128)
conv2 = batch_norm(conv2, training=training)
conv2 = lrelu(conv2, alpha)
conv3 = conv2d(conv2, 256)
conv3 = batch_norm(conv3, training=training)
conv3 = lrelu(conv3, alpha) # Flatten it
flat = tf.reshape(conv3, (-1, 4*4*256))
logits = dense(flat, 1)
out = tf.sigmoid(logits) return out, logits
请注意,在此框架中,判别器的角色是一个常规二元分类器。在一半时间里,它从训练集接收图像,另一半时间从生成器接收图像。
现在再回到我们的派对门票事件。为了伪造假票,唯一的信息来源是朋友 Bob 的反馈。换句话说,在每次尝试中,Bob 提供的反馈质量对于完成工作至关重要。
同样地,每当判别器注意到真实图像和虚假图像之间的差异时,它就向生成器发送一个信号。该信号是从判别器向生成器反向传播的梯度。通过接收它,生成器能调整其参数,从而接近真实数据的分布。
这就显示了判别器的重要性。事实上,生成器生成的数据有多棒,判别器区分它们的能力就有多强。
损失函数
现在,让我们来描述这个结构中最棘手的部分——损失函数。首先,我们知道,判别器从训练集和生成器中接收图像。
我们希望判别器能区分真实和虚假的图像。每当我们通过判别器运行一个小批量值时,我们都会得到 logits。这些是来自模型未经缩放的值。
不过,我们可以将判别器接收的小批量分成两种类型。第一种仅由来自训练集的真实图像组成,第二种仅由生成器创造的虚假图像组成。
def model_loss(input_real, input_z, output_dim, alpha=0.2, smooth=0.1):
"""
Get the loss for the discriminator and generator
:param input_real: Images from the real dataset
:param input_z: random vector z
:param out_channel_dim: The number of channels in the output image
:param smooth: label smothing scalar
:return: A tuple of (discriminator loss, generator loss)
"""
g_model = generator(input_z, output_dim, alpha=alpha)
d_model_real, d_logits_real = discriminator(input_real, alpha=alpha)
d_model_fake, d_logits_fake = discriminator(g_model, reuse=True, alpha=alpha) # for the real images, we want them to be classified as positives,
# so we want their labels to be all ones.
# notice here we use label smoothing for helping the discriminator to generalize better.
# Label smoothing works by avoiding the classifier to make extreme predictions when extrapolating.
d_loss_real = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_real, labels=tf.ones_like(d_logits_real) * (1 - smooth))) # for the fake images produced by the generator, we want the discriminator to clissify them as false images,
# so we set their labels to be all zeros.
d_loss_fake = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_fake, labels=tf.zeros_like(d_model_fake))) # since the generator wants the discriminator to output 1s for its images, it uses the discriminator logits for the
# fake images and assign labels of 1s to them.
g_loss = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(logits=d_logits_fake, labels=tf.ones_like(d_model_fake)))
d_loss = d_loss_real + d_loss_fake return d_loss, g_loss
由于两个网络同时训练,GAN 也需要两个优化器。它们分别用于最小化判别器和生成器的损失函数。
我们希望,判别器对真实图像输出接近 1 的概率,对虚假图像输出接近 0 的概率。为了做到这一点,判别器需要两类损失,其总损失函数是两部分损失函数之和。其中之一用于最大化真实图像的概率,另一个用于最小化虚假图像的概率。

比较实际(左)和生成(右)的 SVHN 样本图像。虽然有些图像看起来很模糊,有些图像很难辨认,但显而易见的是,数据分布是由模型捕获的。
训练开始时,会出现两个有趣的情况。其一,生成器不知如何创建和训练集类似的图像。其二,判别器不知如何将其接收的图像进行分类为「真」或「假」。
因此,判别器接收两类有显著差异的批数据。一个由训练集的真实图像组成,另一个则包含高噪声的信号。随着训练的进行,生成器开始输出更接近训练集图像的图像。这是因为生成器不断训练,学习了组成训练集图像的数据分布。
与此同时,判别器开始越来越好,它变得很擅长将样品分类为真或假。结果,这两种小批量数据在结构上开始变得相似。因此,判别器无法识别图像的真假。
我们使用原版的交叉熵作为损失函数,且 Adam 作为该函数的优化器也是一个不错的选择。

比较实际(左)和生成(右)的 MNIST 样本图像。因为 MNIST 图像数据结构更简单,所以与 SVHN 相比,该模型能够产生更逼真的样本。
总结
GAN 是机器学习中目前最热门的话题之一。这些模型也许可以打开无监督学习的大门,将机器学习扩展到新的视野中。
自 GAN 创立以来,研究人员已经开发出许多用于训练 GAN 的技术。在这些用于训练 GAN 的改进技术中,作者描述了用于图像生成和半监督学习的最新技术。
如果你想深入了解这些主题,我推荐你阅读生成模型(Generative Models)相关的内容:https://blog.openai.com/generative-models/#gan。
同时,你也可以看看半监督学习与 GAN(https://towardsdatascience.com/semi-supervised-learning-with-gans-9f3cb128c5e),以此获得半监督学习上的应用。

原文链接:https://medium.freecodecamp.org/an-intuitive-introduction-to-generative-adversarial-networks-gans-7a2264a81394
☞ 【学界】ParallelEye:面向交通视觉研究构建的大规模虚拟图像集
☞ 【CFP】Virtual Images for Visual Artificial Intelligence
☞ 【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
☞ 【智能自动化学科前沿讲习班第1期】王飞跃教授:生成式对抗网络GAN的研究进展与展望
☞ 【智能自动化学科前沿讲习班第1期】王坤峰副研究员:GAN与平行视觉
☞ 【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
☞ 【学界】谷歌大脑提出Adversarial Spheres:从简单流形探讨对抗性样本的来源
☞ 【解析】当这位70岁的Hinton老人还在努力推翻自己积累了30年的学术成果时,我才知道什么叫做生命力(附Capsule)
☞ 【资源】Style2paints:专业的AI漫画线稿自动上色工具
☞ 【教程】用生成对抗网络给雪人上色,探索人工智能时代的美学




