推出 EfficientDet:助力可伸缩且高效的对象检测
文 / Google Research 软件工程师 Mingxing Tan 和研究员 Adams Yu
作为计算机视觉领域的核心应用之一,对象检测在如机器人和无人驾驶汽车等需要高准确率但计算资源有限的场景中变得日益重要。遗憾的是,当前的许多高准确率检测器受制于这些约束。更重要的是,现实中的对象检测应用在各种平台上运行,这往往需要不同的资源。这样很自然就引出一个问题:如何设计精准、高效,同时又能适应各种资源限制的对象检测器?
在《EfficientDet:助力实现可伸缩且高效的对象检测》(EfficientDet: Scalable and Efficient Object Detection)(已被 CVPR 2020 接收)一文中,我们介绍了一系列可伸缩且高效的全新对象检测器。EfficientDet 以我们之前的可伸缩神经网络 (EfficientNet) 成果为基础,结合了新型双向特征网络 (BiFPN) 和新的伸缩规则,从而实现了 SOTA 准确率,同时相较于之前最前沿的检测器,其体积缩小为原来的 1/9,计算量也大幅减少。下图展示了模型的整体网络架构:
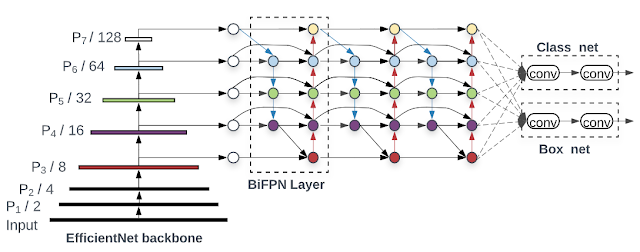
EfficientDet 架构:以 EfficientNet 作为骨干网络,并采用新推出的 BiFPN 特征网络
模型架构优化
为了寻求提高计算效率的解决方案,我们对之前的检测模型开展系统化研究,而 EfficientDet 的灵感正源于我们在此期间的不懈努力。一般说来,对象检测器拥有三个主要组件:骨干网,用于提取指定图像中的特征; 特征网络,用于将骨干网中多个级别的特征用作输入,然后输出一个融合特征列表,这些特征代表了图像的显著特点;最后是 类/盒网络,用于通过融合特征预测每个对象的类和位置。通过检查这些组件的设计选项,我们找到几个关键的优化方案来提升性能和效率:
先前的检测器主要依靠 ResNet、ResNeXt 或 AmoebaNet 充当骨干网,与 EfficientNet 相比,要么性能逊色,要么效率较低。EfficientNet 骨干网的首次实施便实现了效率的大幅提升。例如,从使用 ResNet-50 骨干网的 RetinaNet 基线开始,我们的消融研究显示,仅使用 EfficientNet-B3 替换 ResNet-50 就能将准确率提高 3%,同时将计算量减少 20%。
另一种优化方案是提高特征网络的效率。先前的大部分检测器只是采用自顶向下的特征金字塔网络 (FPN),而我们发现自顶向下的 FPN 天生会受到单向信息流的限制。替代 FPN 的方案(如 PANet)增加了自底向上的信息流,但代价是增加了计算量。最近,在进行神经架构搜索 (NAS) 研究时,我们发现了更为复杂的 NAS-FPN 架构。不过,虽然这种网络结构十分有效,但由于其不具规则性且针对特定任务进行了高度优化,因此很难适应其他任务。
为解决这些问题,我们提出了新的双向特征网络 BiFPN,它整合了 FPN/PANet/NAS-FPN 中的多级别特征融合思路,支持信息自顶向下和自底向上双向流动,同时采用规则的高效连接。
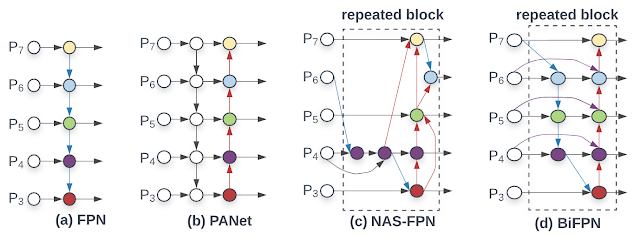
BiFPN 与先前特征网络的对比:BiFPN 支持特征(从低分辨率 P3 级别到高分辨率 P7 级别)自顶向下和自底向上双向重复流动
为进一步提升效率,我们提出了全新且快速的标准化融合技术。传统方法通常一视同仁地处理输入到 FPN 的所有特征,即便是不同分辨率级别。但我们注意到,分辨率级别不同的输入特征对输出特征带来的影响往往也不同。因此,我们对每个输入特征附加了权重,并允许网络学习每个特征的重要性。我们还将所有的常规卷积替换为成本较低的深度可分离卷积。经由这一系列的优化,我们进一步将 BiFPN 的准确率提高 4%,并将计算成本缩减 50%。
第三次优化的内容是在不同的资源限制下,让准确率和效率达成更好的平衡。我们先前的工作表明,联合伸缩网络的深度、宽度和分辨率可显著提升图像识别的效率。受这一想法的启发,我们提出了针对对象检测器的全新复合伸缩方法,可联合伸缩分辨率/深度/宽度。这样的话,每个网络组件(即骨干网、特征网络和盒/类预测网络)将具有单个复合缩放因子,该因子通过启发式规则来控制所有伸缩维度。借助此方法,人们可依据给定的目标资源限制计算伸缩因子,进而轻松确定模型的伸缩方式。
我们将新的骨干网和 BiFPN 相结合,先制定出小型 EfficientDet-D0 基线,然后应用复合伸缩来获取 EfficientDet-D1 至 EfficientDet-D7。从 D0 到 D7,模型需要的计算成本逐步增高,同时也实现了更高的正确率,因此资源限制从 30 亿 FLOP 到 3000 亿 FLOP 不等。
模型性能
我们使用对象检测领域广泛使用的基准数据集:COCO 数据集对 EfficientDet 进行了评估。EfficientDet-D7 达到了 52.2 的平均精度均值 (mAP),超出了以往最前沿的模型 1.5 个点,同时参数量减少了 400%,计算量减少了 940%。
在相同设置下,针对 COCO Test-Dev 数据集,EfficientDet 实现了 52.2 mAP 的最高水准,与以往最前沿的模型相比超出 1.5 个点;在相同的准确率限制下,与以往的检测器相比,EfficientDet 模型的体积缩小 400% 至 900%,所需计算量也减少 1300% 至 4200%
* 由于运算量高达了 3045B FLOP 所以没有在上图中画出。
我们对比了 EfficientDet 与先前模型间的参数大小和 CPU/GPU 延迟时间。在类似的准确率限制下,与其他检测器相比,EfficientDet 模型在 GPU 上的运行速度提高 2 至 4 倍,在 CPU 上的运行速度提高 5 至 11 倍。
虽然 EfficientDet 模型的设计主要目的是进行对象检测,但我们也针对其他任务(如语义分割)检测了其性能。为了执行分割任务,我们要对 EfficientDet-D4 稍作修改,将检测头和损失函数替换为分割头和损失,同时保留相同的伸缩骨干网和 BiFPN。我们利用分割基准中广泛使用的数据集 Pascal VOC 2012,将此模型与以往最前沿的分割模型进行了对比。
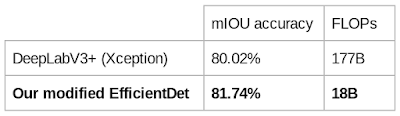
在相同的设置下,无需 COCO 预先训练,EfficientDet 便在 Pascal VOC 2012 上达到了比 DeepLabV3+ 更好的效果,且计算量减少 980%
开源
鉴于 EfficientDet 出色的性能,我们期望它能够为未来的对象检测相关研究打下新的基础,并期待高准确率对象检测模型在诸多实际应用中切实发挥作用。因此,我们已将所有代码开源,并对此 GitHub 链接中的模型检查点进行了预训练。
致谢
感谢论文的共同作者 Ruoming Pang 和 Quoc V. Le。感谢 Daiyi Peng、Golnaz Ghiasi 和 Tianjian Meng 在基础架构方面提供的帮助,也感谢他们积极参与讨论。同时也要感谢 Adam Kraft、Barret Zoph、Ekin D. Cubuk、Hongkun Yu、Jeff Dean、Pengchong Jin、Samy Bengio、Tsung-Yi Lin、Xianzhi Du、Xiaodan Song 以及 Google Brain 团队。
如果您想详细了解 本文讨论 的相关内容,请参阅以下文档。这些文档深入探讨了这篇文章中提及的许多主题:
机器人
https://ai.googleblog.com/2020/03/visual-transfer-learning-for-robotic.html无人驾驶汽车等
https://blog.waymo.com/2020/03/announcing-waymos-open-dataset-challenges.html高准确率检测器
https://arxiv.org/abs/1906.11172EfficientDet:助力实现可伸缩且高效的对象检测
https://arxiv.org/abs/1911.09070EfficientDet
https://github.com/google/automl/tree/master/efficientdetEfficientNet
https://ai.googleblog.com/2019/05/efficientnet-improving-accuracy-and.html深度可分离卷积
https://www.tensorflow.org/api_docs/python/tf/keras/layers/DepthwiseConv2D
先前的工作
https://ai.googleblog.com/2019/05/efficientnet-improving-accuracy-and.html以往最前沿的模型
https://arxiv.org/abs/1906.11172GitHub 链接
https://github.com/google/automl/tree/master/efficientdet
更多 AI 相关阅读: