如何科学交换信息?这篇ICML论文教你如何降低95%的通讯成本
机器之心原创
作者:思源
随着深度模型越来越强大,它的通讯成本和需要的算力也急剧增长。因此,设计一个高效的分布式训练框架非常重要。那么什么是分布式计算,它又是怎样利用多个工作站加速训练呢?在本文中,我们将概述分布式计算的核心概念,并讨论一篇优秀的 ICML 2019 论文,该论文提出一种压缩梯度算法,可以将通讯成本降低 95%。
分布式计算有很多研究问题:如何高效地为工作站分配计算任务;如何有效降低工作站间的通讯成本;如何确保单机和多机训练的收敛具有一致性等等。在 2016 年 TensorFlow 第一次支持分布式训练时,相比单 GPU 训练,其 100 块 GPU 只能提供 56 倍的加速。而随着各种分布式策略及技术的提出,这一加速倍数已经大大提升。
在 ICML 2019 中,快手西雅图 AI 实验室和 FeDA 实验室、罗切斯特大学、苏黎世理工以及香港科技大学等机构的研究者针对分布式计算提出了两个新算法。其中一个算法在节点之间随机出现通讯中断,也可以进行稳定训练。该论文为网络不稳定情况下的算法鲁棒性提供了理论上的支持和保证。
第二个算法 DoubleSqueeze 就是本文将重点介绍的。快手西雅图 AI 实验室负责人刘霁教授表示:「这项工作是近几年最喜欢的几个工作之一,DoubleSqueeze 这种双边压缩最多可以减少超过 95% 的通讯代价,它把并行计算中的通讯代价几乎节省到了极致。」
论文:Distributed Learning over Unreliable Networks(ICML 2019)
论文地址:https://arxiv.org/abs/1810.07766
论文:DoubleSqueeze: Parallel Stochastic Gradient Descent with Double-Pass Error-Compensated Compression(ICML 2019)
论文地址:https://arxiv.org/abs/1905.05957
什么是分布式训练?
当我们的模型越来越大,计算代价越来越高,分布式训练便成为必然。直观上,分布式训练只不过是由一块 GPU 扩展到多块 GPU,但随之而来的是各种问题:模型、数据怎么分割?梯度怎么传播、模型怎么更新?
在分布式计算中,一般我们可以将不同的计算机视为不同的计算节点,它们通过互联网相连而组成整个计算集群。现在重要的就是找到一种方法将计算力与模型训练相「结合」,这也就是分布式策略。最直观的两种策略可能就是模型并行与数据并行,它们从不同的角度思考如何分割模型训练过程。
其中模型并行指的是从逻辑上将模型分割为不同的部分,然后再部署到不同的计算节点。这种方式主要解决的是模型参数量过大等耗显存的情况。数据并行指的是将数据集分割为不同的子模块,然后馈送到不同的节点中。与模型不同,数据天然就是可并行的,因此实践中大部分问题都采用数据并行策略。
同步还是异步?
在数据并行中,具体还有多种并行策略,例如同步并行算法(PS 或 AllReduce)、异步并行算法等。它们是最常见的分布式训练方法,TensorFlow 或 PyTorch 等框架都可以直接调用这几种模式。这几种策略都有各自的优缺点,但如果加上刘霁等研究者提出的双向压缩技术,那么效率都还能提升很多。
因为这三种策略都是针对模型训练提出来的,所以如同一般机器学习,它们会有三大步骤:首先根据输入数据计算预测结果,其次根据损失函数判断预测的好坏,最后利用损失函数的梯度更新参数而完成一次迭代。
对于最直观的同步 SGD,我们会给不同的计算节点(Worker)分配相同的模型和不同的数据。具体而言,各节点根据不同的数据计算局部梯度并反馈给参数服务器,参数服务器整合局部梯度用于更新参数。最后,不同的计算节点再从参数服务器获取当前最新参数就行了,整个过程就如下图所示。整体而言,同步 SGD 类似于将数据分到各个节点,这样单个节点的计算压力就小很多了。
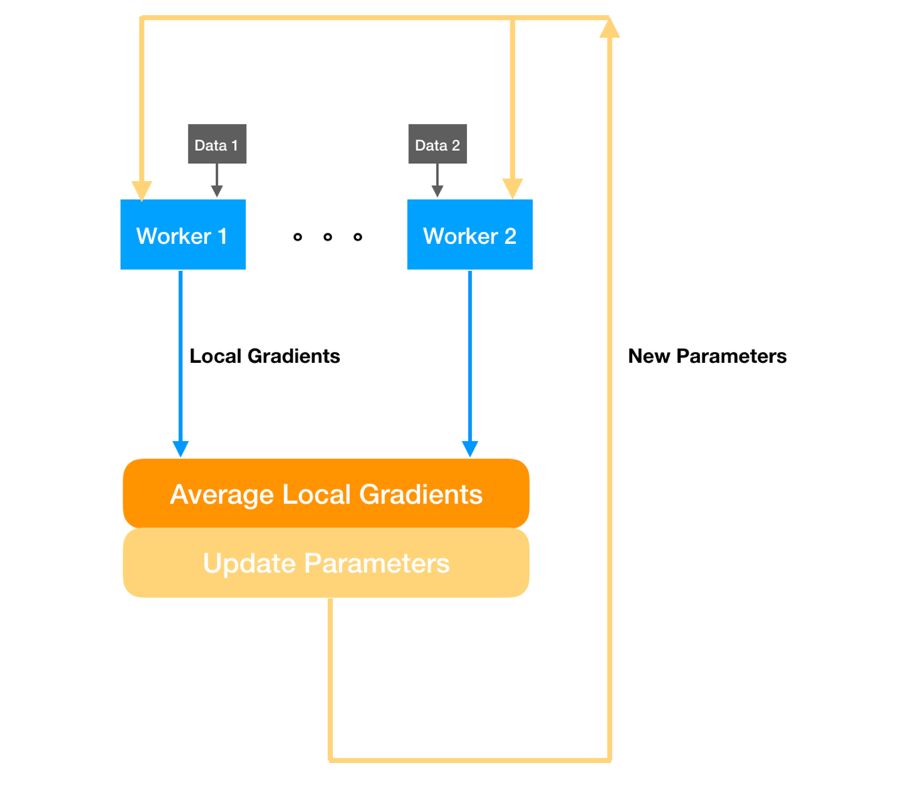
但同步 SGD 的缺陷在于,更新模型必须先等所有局部梯度都完成计算。因此当某一台工作站遇到一批很难算的数据,其它工作站就必须等它算完,这个缺点也引发了我们对异步 SGD 的兴趣。如下图所示,异步 SGD 不需要等待时间。当某个节点完成计算后就可直接传递局部梯度,参数服务器也会直接利用局部梯度更新模型,并将更新后的模型返回该节点。
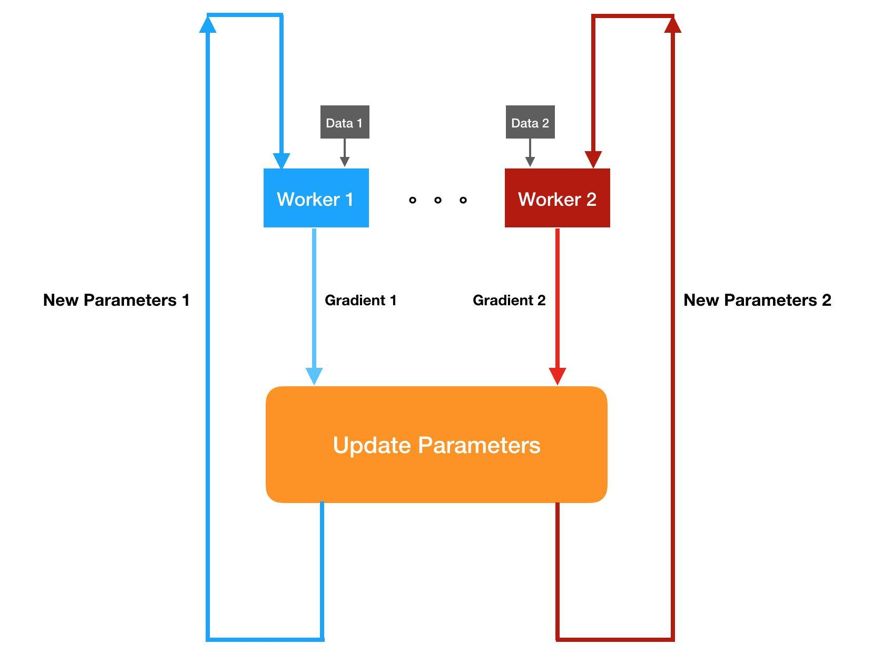
尽管异步 SGD 不再需要等待,但它引入了新问题:很可能节点使用的参数是过时的。例如 Worker 1 和 Worker 2 同时获取了参数,且 Worker 1 先完成计算并更新了参数。那么 Worker 2 本来是基于旧版参数计算出更新方向,但却要将这个更新方向应用到新版参数上,这就会造成一种「过期梯度」的情况。
刘霁教授表示:「以前大部分分布式训练都用同步 SGD,它的优势在于并不需要对算法做任何改变,只是简单地把每一步的计算量分配给多个机器。但是异步要更复杂一些,有很多性质都没有确定。因此在 2015 年的时候,我们有一篇论文讨论了异步 SGD 的正确性和效率。该论文从理论和实践上验证了同步和异步的计算复杂度是一致的,但异步的优势在于每个计算节点都能保证连续工作。」
论文:Asynchronous Parallel Stochastic Gradient for Nonconvex Optimization,NIPS 2015,Spotlight
地址:https://arxiv.org/abs/1506.08272
中心化还是去中心化?
在通常的同步或者异步 SGD 中,参数服务器的通讯代价容易过高。因为所有工作站的梯度信息都要发给它,它的当前参数也要不停地发送给工作站,所以参数服务器的带宽也就成为了分布训练的瓶颈。刘霁教授表示:「去中心化的分布式计算,主要优势在于通信上带来的提升,特别是在模型非常大或网络带宽不够好的时候。总体而言,去中心化的总计算复杂度和通讯代价并不高于中心化策略,且总通讯成本可以平均分配给各计算节点而提升效率。」
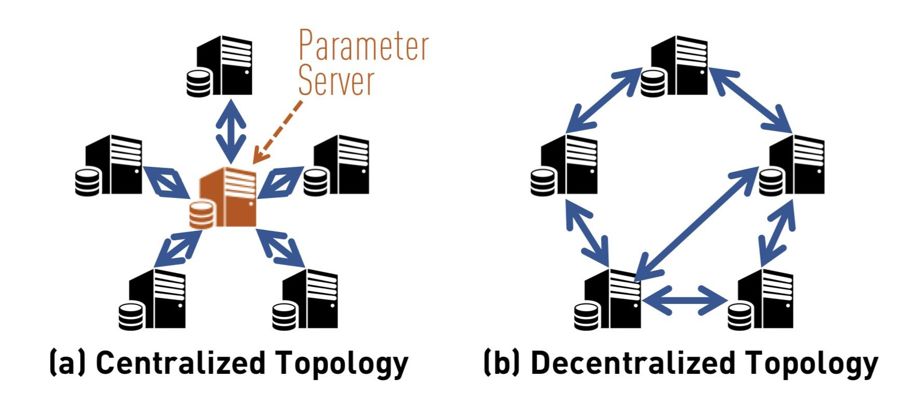
通讯又有什么问题?
即便是去中心化可以让各个 worker 分摊通讯代价,当模型太大或者网络状况不佳的时候(比如带宽太小或者延迟太高),通讯仍然可能成为瓶颈。例如一个 BERT 语言模型有 3.4 亿的参数量,如果用常规的 float-32 单精度浮点数表示参数,那么算下来每一次的通信量就约有 1297MB。很显然对于大规模机器学习模型而言,通信成本就成为了主要的瓶颈。
因此由于通信成本或并行策略等限制,加速比并不是成线性增长的,以下是 TensorFlow 中的多 GPU 基准的加速情况,ResNet 使用 60 块 GPU 相当于提供了 50 倍的加速。
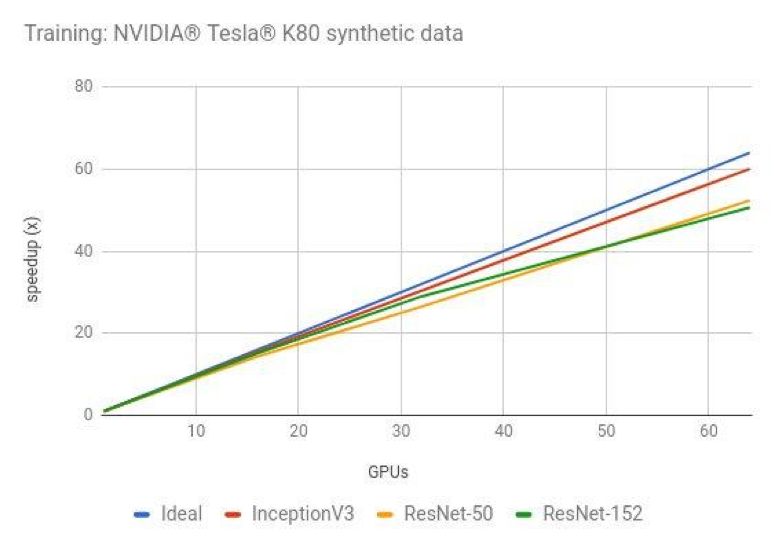
图片选自:https://www.tensorflow.org/guide/performance/benchmarks
如果我们在节点之间传递梯度,同样每一个参数都需要一个对应的梯度来指导更新。梯度要是也用 32 位浮点数表示,那么通信成本是一样的。不过每一次更新的精度其实可以不那么高,因此我们可以用低精度的数据类型表示梯度,从而大幅度降低通信成本。
为了降低通信成本,已经有研究者通过量化或稀疏化等方法压缩梯度,再用压缩后的梯度更新参数。不过因为梯度信息被压缩了,那么随之而来的是收敛速度的降低。为了解决这些问题,快手西雅图 AI Lab 等机构的研究者提出一种名为 DoubleSqueeze 的梯度压缩算法,它带有误差补偿机制而能在保证收敛的情况下极大降低通信成本。
DoubleSqueeze
刘教授表示,以中心化同步 SGD 为例(异步以及去中心化的情况也在论文中以及讨论了),在并行计算交互信息的时候,各计算节点会将梯度都传递到中心节点,中心节点再将更新后的信息传递回各计算节点。整个分布式的优化问题可以表示为:
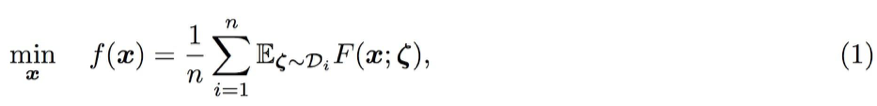
其中 x 表示模型参数,F 表示给定 x 和批量数据 ζ 下的损失函数。因为整个更新过程有 n 个计算节点参加,那么每一个节点的每一个批量数据都应该从对应的局部分布 D_i 中采样。如果需要更新参数 x,那么使用下式求得的梯度来更新就行了:
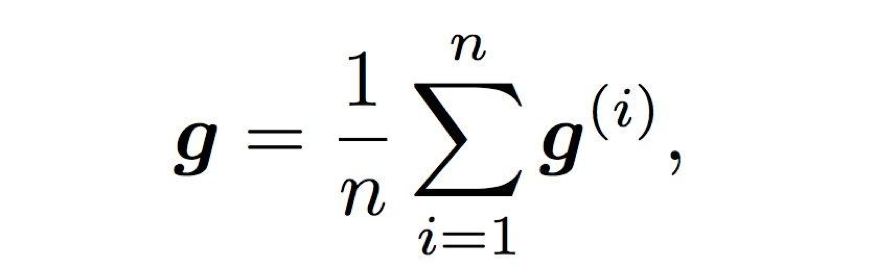
其中 g^i 表示各节点的局部梯度,g 也就是参数服务器求得的全局梯度。这里在将 g^i 传递到参数服务器时,我们可以用稀疏化或量化等压缩方式进行处理,即表示为 C[g^i]。但是在压缩梯度后,它肯定会丢失一些信息,对收敛性以及收敛效率都会产生影响。
刘霁教授表示现在重要的是,我们应该在压缩梯度的同时,尽量不丢失压缩产生的误差信息,且同时还需要保证模型最终的收敛速率。为此,他们采用的信息压缩方法会保留压缩产生的误差,并希望在后续阶段把这种误差补回去。
具体而言对于误差补偿机制,它的核心思想即希望通过向量 δ 保留压缩误差,并且每一次传递压缩梯度 C[g^i + δ^i] 给参数服务器,而不是 C[g^i]。也就是说我们希望通过 δ 补偿压缩误差,因此 δ 就应该是压缩前与压缩后的「差别」,具体更新式可以表示为:
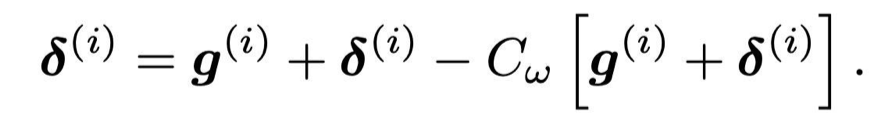
假设δ为零向量,那么就表示局部梯度 g^i 与压缩版 C[g^i] 是一样的,这也就没误差了。只要两个梯度有差别,那么误差 δ 就为非零向量,它就是我们希望补偿给梯度的信息。
双边补偿
前面已经简要讨论了误差补偿机制的核心思想,而 DoubleSqueeze 这篇论文重点在于双边补偿。刘霁教授表示,以前的压缩方法基本都是单边压缩,即只压缩局部梯度,它最多只能节约 50% 的通讯成本。DoubleSqueeze 是一种双边压缩,传递到参数服务器的局部梯度和传递到工作站的全局梯度都能得到压缩,它最多可以减少超过 95% 的通讯代价而不会显著增加计算复杂度。
例如树结构的参数服务器,其叶节点为工作站,非叶节点为参数服务器:
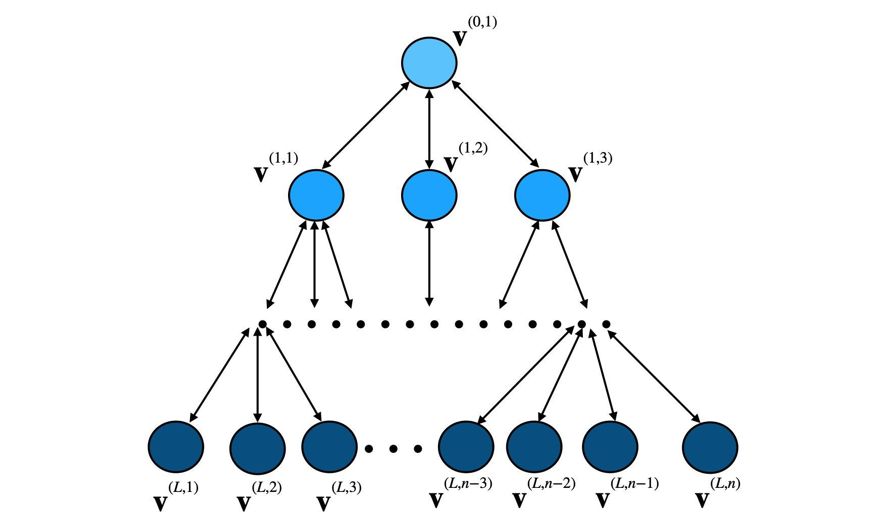
整个参数更新可以分为前向与后向两步,前向是根节点收集叶节点的局部梯度,后向是根节点计算全局梯度并返回叶节点。对于前向过程,梯度压缩和传递可以表示为:
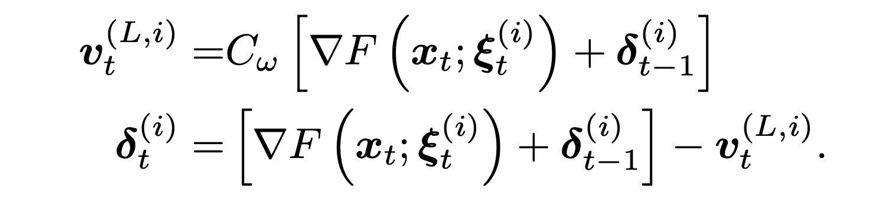
其中∇F 表示损失函数对参数的梯度,δ 为误差补偿向量。计算出来的压缩局部梯度 v 最终会向父节点传递,且叶节点同时根据它更新误差补偿向量 δ。
在叶节点的压缩梯度传递到中间节点时,中间节点也会如同叶节点那样做一次带误差补偿的压缩。只不过它压缩的对象是所有对应子节点传上来的局部梯度。从中间节点到根节点,梯度会经过多次压缩,最终计算出的全局梯度也就是经过压缩的了。
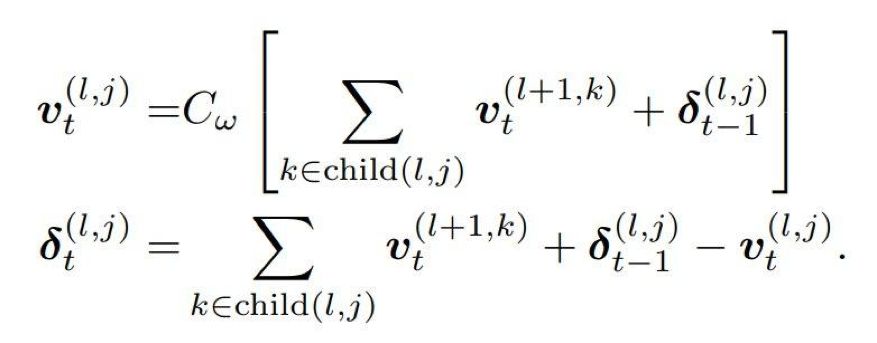
如上所示,中间节点会对所有子节点梯度进行带误差补偿的压缩。在后向传递中,压缩的全局梯度可以直接传递到叶节点,然后叶节点再根据它更新参数就行了。
总体而言,不仅局部梯度会进行带补偿的压缩,全局梯度也会一步步压缩。这是一种双边压缩,通信量相比以前能更大幅度地降低。
在快手做研究
这些研究都是快手西雅图实验室等机构完成的,该实验室自去年年底成立,目前已经在 ICLR、CVPR、ICML,AISTATS 等顶会上发表了若干篇论文。刘霁教授表示,在快手做研究非常有优势的一点在于,目前快手有很多任务和机会,实验室愿意为好的研究者量身打造业务问题和场景,因此人才有比较大的自由度和发展空间。
因为有大量实际业务,那么它们就能催生出非常好的研究。刘霁教授说:「我在学术界和工业界都呆过,我认为最好的研究工作一定是从现实场景中生成出来的,因此我们做的解决方案、理论分析或算法升级才能真正服务于某个具体的问题。这种对具体问题的帮助可以体现在两方面,即实实在在地提升某个指标的性能,或潜在地加深我们对某个问题的理解。」
所以总的而言,快手西雅图 AI 实验室的目标在于解决行业内迫切的一些业务需求,并从这些业务中提取非常有价值的前沿学术问题。从这个角度出发,实践中提取的研究问题才能解决生产中的关键性瓶颈,这也是在快手做研究的重要优势。
本文为机器之心原创,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com


