为什么是 Flink?Apache Member 如何理性看待一项新技术?

文章作者:章剑锋 ( 简锋 ),开源界老兵,Github ID:@zjffdu,Apache Member,曾就职于 Hortonworks,目前在阿里巴巴计算平台事业部任高级技术专家,并同时担任 Apache Tez、Livy 、Zeppelin 三个开源项目的 PMC ,以及 Apache Pig 的 Committer。有幸很早就接触了大数据和开源,希望可以在开源领域为大数据和数据科学做点贡献。
导读:笔者从 2008 年开始工作到现在也有 11 个年头了,一路走来都在和数据打交道,做过很多大数据底层框架内核的开发 ( Hadoop,Pig,Tez,Spark,Livy ),现在是多个 Apache 项目的 PMC。
相信大家都看过不少 Flink 的文章了,今天我想借此机会来聊聊一个朴实的问题:为什么我们要学习 Flink,也即如何理性看待一项新技术是否值得跟风学习。
那么,是因为一项技术火,你才学的吗?是因为你老板决定用这项技术,你才学的吗?那你有没有想过为什么这项技术会火,为什么你老板决定用这项技术。今天我们就以 Flink 为例,来好好聊为什么要学习 Flink,以及如何看待一项新技术是否有潜力,希望对你有所启发。
▌Flink:大数据 + AI 全栈的核心
大部分人对 Flink 的第一印象是大数据引擎,但我想说 Flink 不只是 Big Data,Flink 的目标是星辰大海。
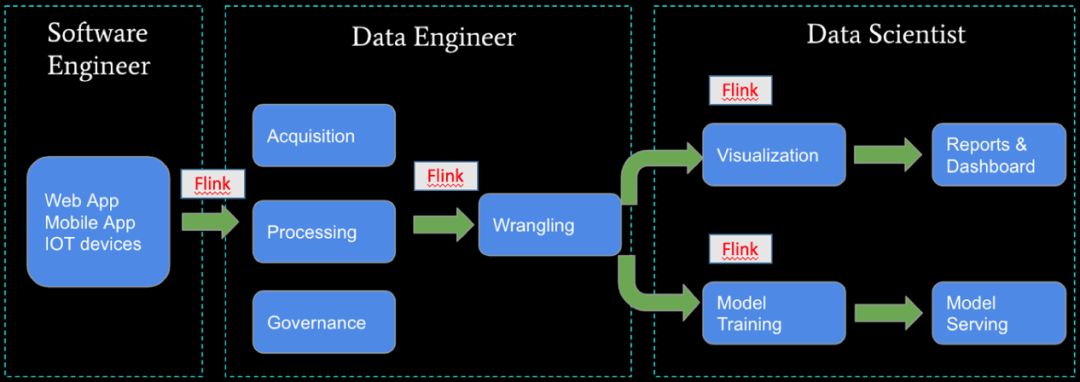
我们首先来看下这张大数据场景图。这张图基本上把你日常需要处理的大数据场景都包括进来。从最左边的数据生产者,到数据收集,数据处理,然后再到数据应用 ( BI + AI )。你会发现 Flink 可以应用在每一个步骤。不仅涉及到大数据,也涉及到 AI,所以说学习 Flink 等于学到了大数据 + AI 全栈。
Flink 会上接 IOT,下接 AI,打通端到端的数据价值挖掘全链路。
Flink 的上游数据规模会继续增长,特别是由于 IOT 技术的发展和成熟,以及未来 5G 技术的铺开。在可预测的未来,数据规模仍将继续快速增长。Flink 丰富的 connector 生态可以让 Flink 对接几乎所有的数据源。
Flink 的下游数据产业还有很多发展的空间。BI 技术已经非常成熟,但是近年来对实时 BI 的需求越来越强烈,Flink 在实时 BI 的场景有非常强的用武之地。另外是 AI 技术的快速发展,会带动大数据引擎的发展。Flink 自身也在发展 Machine Learning 相关的技术,去年刚开源的 Alink [1] 就是基于 Flink 的机器学习 library,Alink 可以让没有机器学习理论知识和工程经验的普通软件工程师也可以方便的使用机器学习技术。
▌批流融合,大势所趋
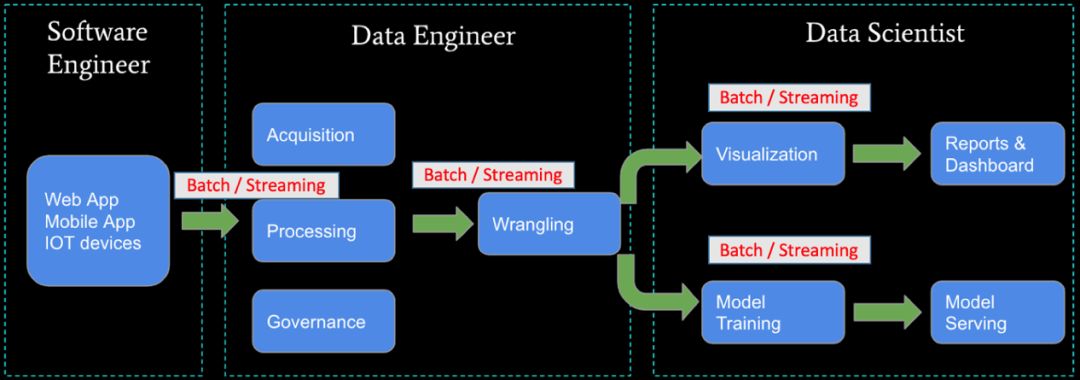
Flink 引以为傲的是它的超强流计算能力。不过 Streaming Processing 只是 Flink 的看家本领,并不是他的全部,Flink 真正厉害的地方是它的批流统一。
我们还是可以拿上面那张图来解释。你可以看到每个阶段都可以用批流2种方式来解决。我们可以用 Flink 来解决批处理方式的数据收集任务,也可以用流处理的方式来解决已达到更快的实时性。数据处理也是一样,我们可以用 Streaming ETL,也可以做 Batch ETL。到数据应用这层也是,我们不仅可以用批处理来制作日常的 dashboard,也可以用流计算来做实时 dashboard。在 AI 这块,我们不仅可以用批处理的方式基于历史数据做模型训练,也可以用流处理的方式做在线学习,实时更新模型。总之,你会发现 Flink 的批流融合完美契合了整个大数据端到端的应用。
▌多语言支持,拥抱 AI 社区

用过 Flink 的人一般都知道 Flink 有 Java 和 Scala API,很多人都知道那个经典的 WordCount 例子。Java 和 Scala API 对于一般的软件工程师来说是很友好的编程语言工具,但是对于其他领域的人来说 ( 比如数据分析师,数据科学家 ),Java 和 Scala 就不是一种很友好的语言。为了能够吸引这些人来使用 Flink,Flink 推出了 SQL 和 Python 两种语言的API,进一步降低 Flink 的使用门槛。数据库技术发展这么多年,每隔几年都有新的技术创新,唯独 SQL 成为亘古不变的数据库系统入口语言。SQL 是一个生命力非常强盛的语言,围绕 SQL 语言有非常强大的生态圈,大部分 BI 工具,数据分析软件都可以对接 SQL。由于 AI 的流行,Python 语言最近的增长势头也非常强势,用户量与日俱增,可以说是 AI 领域的第一语言。PyFlink 的推出,拉通了 Flink 社区和 Python 社区,使得数据科学家以较低的学习成本来利用 Flink 的计算能力。
▌不仅仅是一个 Library,更是一个 Platform
Flink 作为一个 Apache 项目,我们可以认为它是一个 Library,用户可以基于这个 Library 开发各种程序。但是作为 Library 只是我们对 Flink 的一个狭隘的理解,更确切的理解应该是一个 Platform。用户可以基于这个 Platform 进行功能扩展,对接外部系统,从而建立一个更完善的解决方案。比如 Zeppelin notebook [3] 集成了 Flink,用户可以在 Zeppelin 上编写 Flink SQL,UDF,运行 Flink Job ( Batch & Streaming ),而且还可以可视化数据,中小企业完全可以用 Zeppelin 来搭建大数据平台。Ververica Platform 是一个企业级的多租户 Flink Job 管控平台,你可以在上面方便的提交管理 Flink Job,而且 Ververica Platform 很容易对接各种云平台,可以与你现有的基于云平台的应用系统完美无缝对接。

▌不只是 China
众所周知,阿里巴巴持续重磅投入 Flink,使得 Flink 在国内的发展非常迅速,去年 Flink Forward 大会亚洲场在北京召开,吸引了2000人次参会。但可能很多人不知道 Flink 在国外也发展的非常迅猛。Flink 大会也有欧洲场,美洲场。Flink Forward 已经成为为数不多的能在三大洲召开的技术大会,大数据领域除了 Flink,恐怕就只有 Spark 和 Kafka 了。

▌全面拥抱云计算
刚开始 Flink 是为数据中心环境准备的,用户需要自己搭建集群环境,比如 Standalone,Yarn 或者 Mesos,这对用户的运维能力提出了非常大的挑战,每一次扩缩容,版本升级都是一件很头疼的事情。而现在 Flink 已经全面拥抱云环境,对 K8s 的支持日趋完善,不久的将来我们可以期待云原生的 Flink 应用会越来越多。同时这也对开发人员对云技术提出了新的要求,只有掌握云技术才能更好的发挥 Flink 的能力。

之所以要将 Flink 放在 Kubernetes 之上,是因为这样做有以下几点优势:
第一,Kubernetes 能够在多租户场景下为 Flink 带来更好的体验。
第二,目前各大公司都在逐步采用 Kubernetes 做 IT 设施的管理,如果 Flink 能够运行在 Kubernetes 之上,对于用户而言就能够实现更大规模的资源共享和统一管理,降低成本的同时能够提高效率。
第三,Kubernetes 云原生生态发展非常迅速,如果 Flink 能够与 Kubernetes 生态实现很好的整合,就能够让 Flink 享受到 Kubernetes 生态的技术红利,使得 Flink 能够在生产环境下提供运维保障。
▌不只是现在
—— 学习 Flink 对你职业生涯的帮助
最后我想说下决定学习某项技术可能不仅仅是个技术问题,更现实的是它可能会是个影响你职业生涯的问题。
由于 Flink 技术的发展,企业对 Flink 相关技术人员的需求也在与日俱增。根据去年参加 Flink Froward Asia 的情况下来看, 国内几乎所有的一、二线互联网公司都已经采用了 Flink,我们可以预期其他互联网公司以及一些非互联网公司在未来几年肯定会陆续采用 Flink,Flink 相关的人才在未来几年应该会成为众多公司哄抢的对象。下面例举了使用了 Flink 的国内外的一些代表性公司。

学习 Flink 也并不仅仅为了现在,而是为了将来的技术积累和储备。如上所述,Flink 不仅在流计算这块有坚实的基础,也在其他领域发力,也在拥抱面向未来的技术 ( 特别是 AI 和云计算 ),所以学习 Flink 不仅仅是现在,也是在为未来做准备。
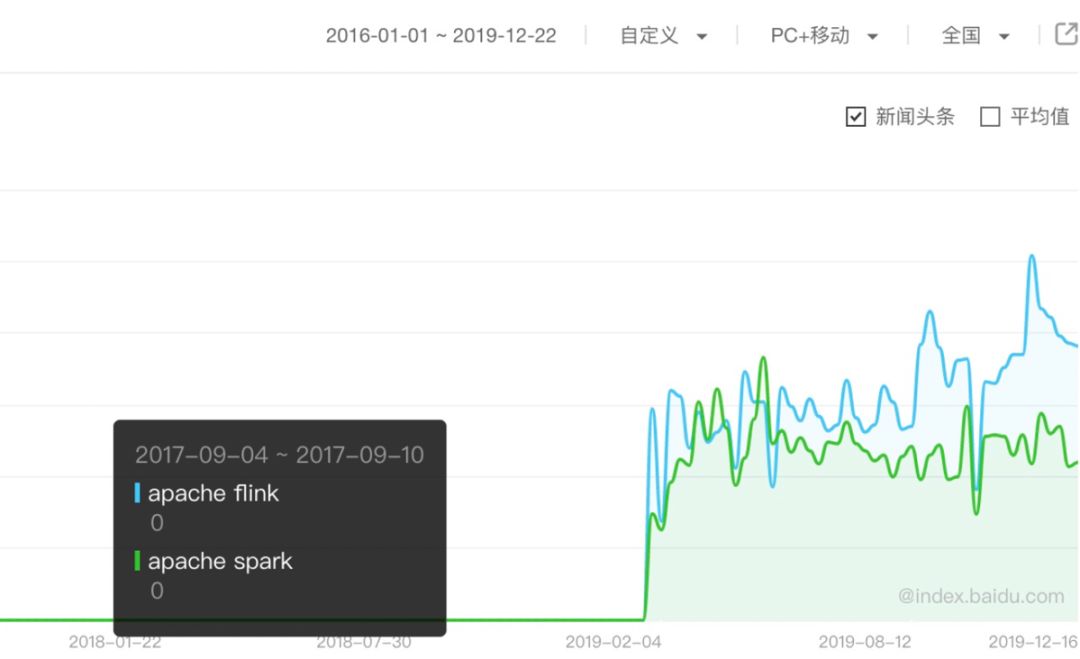
还有一点我想说的是学习 Flink 并不只是学习 Flink 本身,你还可以扩宽眼界,学习到其他的技术,交到很多志同道合的朋友。由于 Flink 本身的生态系统的强大,你可以学习到其他领域的知识,比如 IOT,云原生,AI 等等。此外 Flink 社区蓬勃发展,在国内已经积蓄了大量的学习资料和人才,Flink 的钉钉群人数已经超过了1万5千人,百度指数上的 flink 指数已经超过了 spark。在 Flink 社区,你可以从别人身上学习到很多有优秀的东西,我相信你在 Flink 社区会有多意想不到的惊喜。
综上所述,是笔者对为什么学习 Flink 的分析。新兴技术的涌现昼夜不停,本文的初衷是不希望大家盲目的学习一项技术,更希望大家在未来的日子里多思考,多收获。本次的分享就到这里,谢谢大家。
▌References








