别再让你的web页面在用户浏览器端裸奔
(点击上方公众号,可快速关注)
作者: 阿里巴巴国际UED团队/戊子
http://www.aliued.com/?p=4162
页面在用户那里运行,如果10%的用户页面出现问题而自己本地没有办法重现?
如何先一步了解到前端出现的问题,而不是等用户反馈?
能不能像查看服务端日志一样来定位前端页面运行的问题?
前端在业务复杂度越来越高的情况下,本地即使做了充分的测试,依照caniuse做了很多兼容,依然无法让人放心页面能否正常运行或者运行得怎么样。
当一个前端页面发布出去了之后,页面所运行的设备、浏览器、网络环境、用户操作习惯等等因素都可能是造成页面不正常的原因。
所以对前端页面需要做一定的监控,而最可行的前端监控方式就是将页面的日志选择上报到监控日志服务器中。
前端日志上报可以很简单
对业务逻辑的执行收集了日志数据之后可以参数的形式构造一个url,再通过一个Image请求发送到到服务器就完成了日志的上报。
(new Image).src = `/r.png?page=${location.href}¶m1=${param1}...`;
这样一行代码就搞定了日志的上报,然鹅,在生产环境中,日志上报所延伸的问题要复杂很多。
日志上报带来的问题
日志上报最终是为了服务业务,监控业务的运行状态,一般而言前端运行的场景中开发者最期望监控的不外乎页面&API请求是否正常响应和页面js逻辑是否正常执行。
为了覆盖这两个监控目标,需要通过很多类型的日志来覆盖,还有一些特殊场景下,开发者还希望能与具体业务灵活结合,实现自定义上报。所以常见的日志类型如下
– 页面&API请求是否正常响应
– API调用日志 – API调用成功与否及其耗时
– 页面性能日志 – 页面连接耗时、首次渲染时间、资源加载耗时等
– 访问统计日志 – PV/UV,短时间内断崖式的量变化很容易反应问题
– 页面js逻辑是否正常执行
– 页面稳定性日志 – 页面加载和页面交互产生的js error信息
– 业务相关日志
– 自定义上报 – 某些业务逻辑的结果、速度、统计值等自定义内容
随着前端业务的壮大,日志监控上报的量会快速增加,监控的逻辑也会越来越复杂,而在生产环境中,前端监控的最基本原则是日志获取和上报本身不能抛出异常或者影响页面性能。
这么多的日志类型代表了日志获取的逻辑复杂,同时各种各样的浏览器和环境会让这个问题变得更棘手,例如想用console.warn打印异常信息,但是可能会出现warn函数调用报错;例如捕捉到了error但是error.message全是Script error.…
浏览器的兼容性,前端业务逻辑依赖,日志上报方式,日志上报效率,用户操作习惯,网络环境等因素都可能让日志上报产生问题甚至影响业务。这些因素会给日志上报带来可靠和性能两方面的问题
日志上报的可靠性问题
浏览器兼容性
在不同端和浏览器中,因为兼容性的不同,日志获取逻辑的和上报方法需要兼容多种方式来进行,例如fetch方法方法是否可用,页面性能(performance)计算是否可以使用NT2标准,这些问题可能会带来上报逻辑本身报错污染业务日志统计;
上报可靠性
日志采集sdk可能因为网络原因无法加载,所以安全的方式是sdk注入的位置合理的靠后,那么页面打开到sdk初始化这段时间就会产生漏报;
后端为了业务分离,通常会独立设定一个日志采集服务器,这种情况下日志上报可能会遇到跨域问题;
用户的频繁操作和关闭页面会可能造成很多已经收集的数据漏报。
日志上报的性能问题
在一个复杂站点中,这些日志数据可能会非常多,上报可能会因为浏览器并发数量的限制阻塞业务的网络请求,或者影响页面性能。
更优雅的上报姿势
姿势一 隔离业务
资源隔离
为了避免影响业务,那么理所当然,为了不占用业务计算资源,日志上报需要单独设定后端服务。
同时也不能使用与业务相同的域名,这跟页面尽量使用CDN引入资源的原理相似,浏览器会对同一个域名有一定的并发数限制。
而页面性能、资源加载、初始化API、PV/UV、初始化js逻辑错误等日志都是页面初始化的时候触发上报,这种短时间大量的上报可能会造成网络请求延时。例如chrome对同一个域名的最大并发连接数为6个,如果日志同时上报了6次以上,就会对同域名的业务造成影响;更坏的情况如页面有一些错误、网络连接质量质量不高会让日志上报阻碍页面渲染。
因此日志上报可以像使用CDN服务一样,使用单独域名和日志处理服务。
既然使用了不同的域名,那么跨域问题随之而来,这需要前后端共同支持。服务器需要允许外部访问Access-Control-Allow-Origin:*;前端在进行日志上报的时候要添加避免跨域标识,如fetch方式:
var url = 'https://arms-retcode.aliyuncs.com/r.png';
fetch(
`${url}?t=perf&page=qar.alibaba-inc.com&load=1168`,
{mode:'no-cors'}
)
不同域名一个性能缺点是增加首次DNS解析时间,不过可以通过在页面添加DNS预解析来避免。
<link rel="dns-prefetch" href="https://arms-retcode.aliyuncs.com">
异常隔离
在资源隔离的基础上,日志上报的异常处理也需要隔离,日志本身抛出的异常绝对不能和业务异常混在一起上报。
进行充分测试的前提下,最简单粗暴的方式是在整个监控sdk外面添加try...catch...,好处是永远不会出现sdk本身错误上报,不过同时也让开发者失去了发现sdk问题的途径。所以两者兼得的方式是必要的。
这里提供一个关键模块埋点的方法,它对整个前端监控sdk多个关键点上埋点并且收集的结果中只标记是否成功。话不多说,直接上示例代码:
// 全局标记汇总,初始化为36个点位均为1的数组
var N = 36;
var sdkStat = Array.from({length: N}, () => 1);
/** 日志上报功能模块
* 对应模块报错设置对应点位为0,多个点位为0可以帮助找到错误发生链路
*/
try{/* sdk module 0*/}catch(){sdkStat[0] = 0;}
/* other modules */
try{/* sdk module 35*/}catch(){sdkStat[35] = 0;}
// 日志上报发送模块
var statStr = parseInt(sdkStat.join(''),2).toString(36);
(new Image).src = `/r.png?¶m1=${param1}&sdkStat=${statStr}...`;
姿势二 压缩请求响应报文
压缩之前重新审视一下(new Image).src的日志发送方式:
HTTP Request: 前端日志数据以多组key=value的字符串形式接在一个Image资源请求的url后面,前端发送Image请求。
HTTP Responce: 服务器返回响应结果或者空图片。
日志数据直接放到url中的好处是网络传输效率高。然而url长度是有限制的,例如IE浏览器是2083个字符,同时服务器也会对url长度进行限制。
类似如下的js error信息就没有办法完整上报,
$ is not defined@https://www.example.com.cn/catalog/?spm=a2o4k.customer.0.0.37c1379dmQwdrW&q=pediasure&searchclickposition=hint:3:231
...
Tg@https://www.googletagmanager.com/gtm.js?id=GTM-KTVS7D9&l=shadowDatalayerKi7l:64:32
...
不仅仅是js error的错误栈深还因为urlencode对特殊字符和汉字的转码,这两个因素会使url长度轻松突破限制。
另外业务逻辑实际上不关注而且也应关注日志上报的响应结果,所以这个请求的结果应该尽可能省去。
针对报文压缩有以下方式:
HTTP/2头部压缩
http请求中,每次请求都会传输一系列的请求头来描述请求的资源及其特性,然而实际上每次请求都有很多相同的值,如Host:,user-agent:,Accept等。这些数据能够占用到300-800byte的传输量,如果携带大的cookie,请求头甚至可以占用1kb的空间,而实际真正需要上报的日志数据仅仅只有10~50byte的大小。在HTTP 1.x中,每次日志上报请求头都携带了大量的重复数据导致性能浪费。
HTTP/2头部压缩采用Huffman Code压缩请求头,并用动态表更新每次请求不同的数据来把每次请求的头部压缩到很小。
HTTP/1.1效果

HTTP/2.0效果
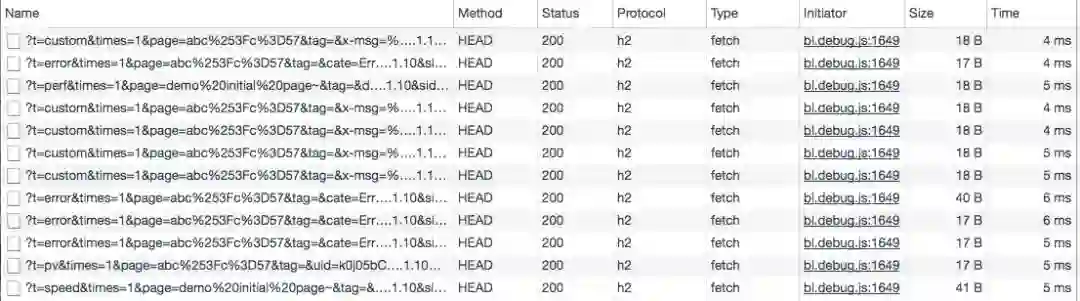
头部压缩后每条日志请求的size都大大减小,响应的速度也有提升。
压缩日志的长度
最需要压缩即js error的错误栈,错误栈当中占位最多是错误定位的文件地址,而很多错误栈有很多相同的文件,压缩空间就来源于stack中js文件的url重复。
一个典型的jserror stack经常会出现这种形式如下:
obj0.fn0 at (http://loooooooooonnnnnnnnnnng/loooooong/long.js 123:1)
obj1.fn1 at (http://loooooooooonnnnnnnnnnng/loooooong/long.js 234:1)
obj2.fn2 at (http://loooooooooonnnnnnnnnnng/laaaaaang/lang.js 345:1)
...
可考虑把文件url抽取出来单独作为一个字典,那么上报内容可缩减为
files={'f1':'http://loooooooooonnnnnnnnnnng/loooooong/long.js','f2':'...'}
obj0.fn0 at (f1 123:1)
obj1.fn1 at (f1 234:1)
obj2.fn2 at (f2 345:1)
...
即可大大缩减日志长度。
省去响应体
日志上报本身只关注日志有没有上报,而对上报请求的返回内容并不关注,甚至完全可以不需要返回内容。所以使用HTTP HEAD的方式上报,并且返回的响应体为空,避免响应体传输资源损耗。
这时候只需要设置一个nginx服务器来记录日志内容并返回200状态码即可。
fetch(`${url}?t=perf&page=lazada-home&load=1168`,
{mode:'no-cors',method:'HEAD'}
)
姿势三 合并上报
既然一个页面上报的次数那么多,一个更容易想到的idea应该是把日志合并上报来减小请求数量。
HTTP/2多路复用
用户浏览器和日志服务器之间产生多次HTTP请求,而在HTTP/1.1 Keep-Alive下,日志上报会以串行的方式传输,会让后面的日志上报延时。通过HTTP/2的多路复用来合并上报,节省网络连接的开销。

HTTP POST合并
POST请求因为request body可以有更大施展空间,在HTTP POST中只要一次包含多条日志的内容,那么相对于一条日志一次HTTP HEAD请求的方式会更加经济。
在HTTP POST的基础上,可以顺便解决用户关掉或者切换页面造成的漏报问题。
以前常见的解决方式是监听页面的unload或者beforeunload事件,并以通过同步的XMLHttpRequest请求或者构造一个特定src的<img>标签来延迟上报。
window.addEventListener("unload", uploadLog, false);
function uploadLog() {
var xhr = new XMLHttpRequest();
xhr.open("POST", "/r.png", false); // false表示同步
xhr.send(logData);
}
这种上报的缺点是会给下一个页面的性能造成影响。更优雅的方式是使用navigator.sendBeacon(),它能够异步地发送日志数据。
window.addEventListener("unload", uploadLog, false);
function uploadLog() {
navigator.sendBeacon("/r.png", logData);
}
合并前

合并后(navigator.sendBeacon)

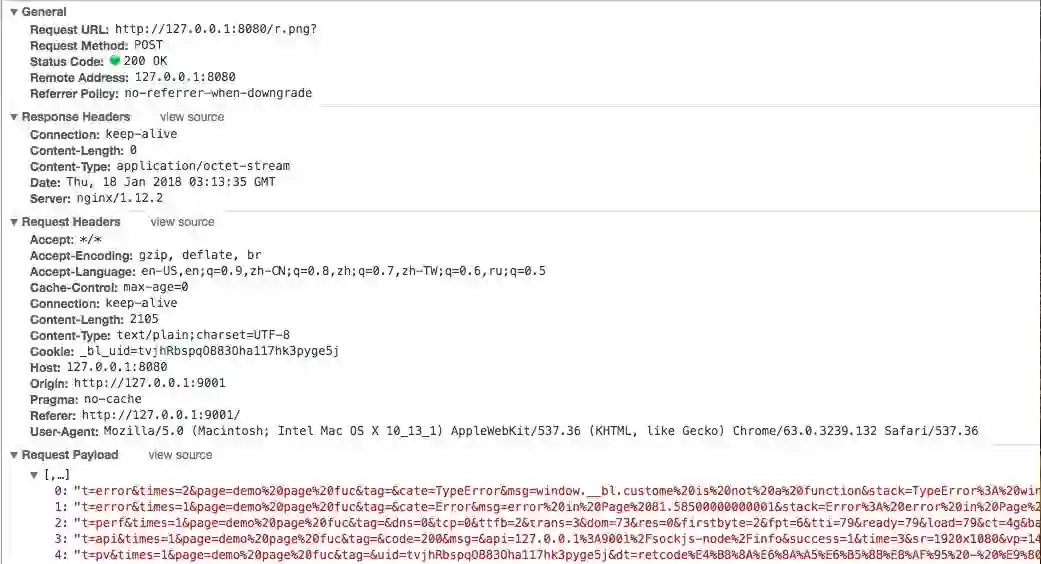
理想情况下,合并n个日志上报耗费的总时间能达到原来的1/n
小结
前端业务场景和浏览器的兼容性千差万别,所以日志上报要兼容多种方式;页面生命周期、业务逻辑影响了日志是否可获取和是否漏报,所以对应的日志类型和上报时机要严格把握;前端业务逻辑快速迭代且场景多样,所以日志上报要做到与业务解耦合同时可以自定义上报…
这些大大小小的坑促使我们把前端日志监控沉淀为一个独立且系统性的工程来做,在打磨这个工程的过程中我们同样还在探索是否有更加高效、稳定的日志上报方式。
请分享给更多人
关注「前端大全」,提升前端技能


淘口令:复制以下红色内容,再打开手淘即可购买
范品社,使用¥极客T恤¥抢先预览(长按复制整段文案,打开手机淘宝即可进入活动内容)





