

摘要
本文综述了在快速发展的领域中,如何通过强化学习(RL)增强大型语言模型(LLMs)的研究。强化学习是一种使LLMs能够通过基于输出质量的奖励反馈来提高其性能的技术,从而生成更准确、一致、并在语境上更合适的回应。本文系统回顾了最新的强化学习增强LLMs的研究,试图整合并分析这一快速发展的领域的研究成果,帮助研究人员理解当前的挑战和进展。具体来说,我们:(1)详细介绍了强化学习的基本原理;(2)介绍了流行的强化学习增强的大型语言模型;(3)回顾了基于奖励模型的两种广泛使用的强化学习技术:来自人类反馈的强化学习(RLHF)和来自AI反馈的强化学习(RLAIF);(4)探索了直接偏好优化(DPO)方法,这是一组绕过奖励模型、直接使用人类偏好数据来调整LLM输出以符合人类期望的方法。我们还将指出现有方法的挑战和不足,并提出一些进一步改进的方向。
1. 引言
大型语言模型(Jiang et al., 2023; OpenAI, 2023; Dubey et al., 2024)是经过大规模文本数据预训练的复杂语言模型,使其能够对多种输入生成连贯流畅的回应。然而,这些预训练的大型语言模型的互动能力可能不一致,有时会产生虽然技术上正确,但可能有害、偏见、误导或与用户需求无关的回应。因此,在将其应用于各种自然语言任务之前,将预训练大型语言模型的输出与人类偏好对齐至关重要(Wang et al., 2023b; Wan et al., 2023; Sun et al., 2023c,b; Giray, 2023; Zhang, 2023; Long, 2023; Sun, 2023; Gao et al., 2023; Paranjape et al., 2023; Sun et al., 2023a; Diao et al., 2023; Wang et al., 2023a; Zhang et al., 2023b; Sun et al., 2023d; Liu et al., 2024d; Yao et al., 2024; Liu et al., 2024c; Lee et al., 2024; Kambhampati, 2024; Wang et al., 2024c)。 此前,将预训练的大型语言模型的输出与人类偏好对齐的广泛采用的方法是监督微调(SFT)(Hu et al., 2021; Mishra et al., 2021; Wang et al., 2022; Du et al., 2022; Dettmers et al., 2023; Taori et al., 2023; Zhang et al., 2023a; Chiang et al., 2023; Xu et al., 2023; Peng et al., 2023; Mukherjee et al., 2023; Li et al., 2023; Ding et al., 2023; Luo et al., 2023; Wang et al., 2024d; Zhou et al., 2024)。这种方法通过(指令,答案)对进一步训练LLMs,其中“指令”代表给模型的提示,“答案”是符合指令的目标输出。SFT有助于引导LLMs生成符合特定特征或领域知识的回应,使得人类能够与LLMs进行交互。尽管SFT有效,但它也有局限性:在训练过程中,模型被限制为学习我们提供的特定答案,并且使用困惑度(PPL)等指标来惩罚同义词的使用。一方面,这可能阻碍LLM的泛化能力,因为任务如写作和总结有多种有效的表述方式。另一方面,它可能导致在与人类偏好对齐时表现不佳,因为训练过程中没有直接融入人类反馈。 为了缓解上述问题,采用了强化学习(RL)来将LLM的输出与人类偏好对齐,强化学习过程可分为三个步骤:(1)首先,在微调之前,训练一个奖励模型(或奖励函数),以近似人类偏好并为不同的LLM输出评分;(2)然后,在每次微调迭代中,给定一个指令,LLM生成多个回应,每个回应都由训练好的奖励模型评分;(3)最后,使用强化学习的优化技术——策略优化,基于这些偏好评分更新LLM的权重,以改进预测。用强化学习微调LLM可以同时解决上述问题。一方面,强化学习不再限制模型仅学习一个特定答案,而是根据各种偏好评分调整LLM,奖励任何有效且措辞恰当的回应。另一方面,奖励模型被设计为近似人类偏好,从而使得可以直接在人工偏好上训练,并增强LLM的创造力。 本文将整合强化学习(RL)在大型语言模型(LLMs)中的最新研究成果,试图分析并总结这一快速发展的领域,帮助研究人员理解当前的研究进展、挑战和前景。具体来说:
- 第二部分介绍强化学习(RL)的基本原理及关键术语,并概述强化学习如何适应LLM的管道。
- 第三部分介绍了强化学习增强的流行且强大的大型语言模型。
- 第四部分概述了基于人类反馈的强化学习(RLHF)的过程,这是一种将强化学习与人类反馈结合的训练方法,用以将LLMs与人类的价值观、偏好和期望对齐。
- 第五部分回顾了基于AI反馈的强化学习(RLAIF)的研究,RLAIF作为RLHF的有力补充,利用AI系统提供反馈,提供了可扩展性、一致性和成本效益的优势。
- 第六部分分析了RLHF和RLAIF所面临的挑战。
- 第七部分讨论了直接偏好优化(DPO)研究,这是一系列绕过奖励模型、直接利用人类偏好数据将LLM输出与人类期望对齐的方法。
- 第八部分总结了当前的挑战,并讨论了进一步改进的机会。
强化学习在大型语言模型中的应用
我们已经概述了强化学习(RL)的基本框架;现在,我们将深入探讨如何使用RL微调大型语言模型(LLMs)的过程。此方法旨在将LLM与期望的行为对齐,提升其性能,并确保其输出既有效又可靠。
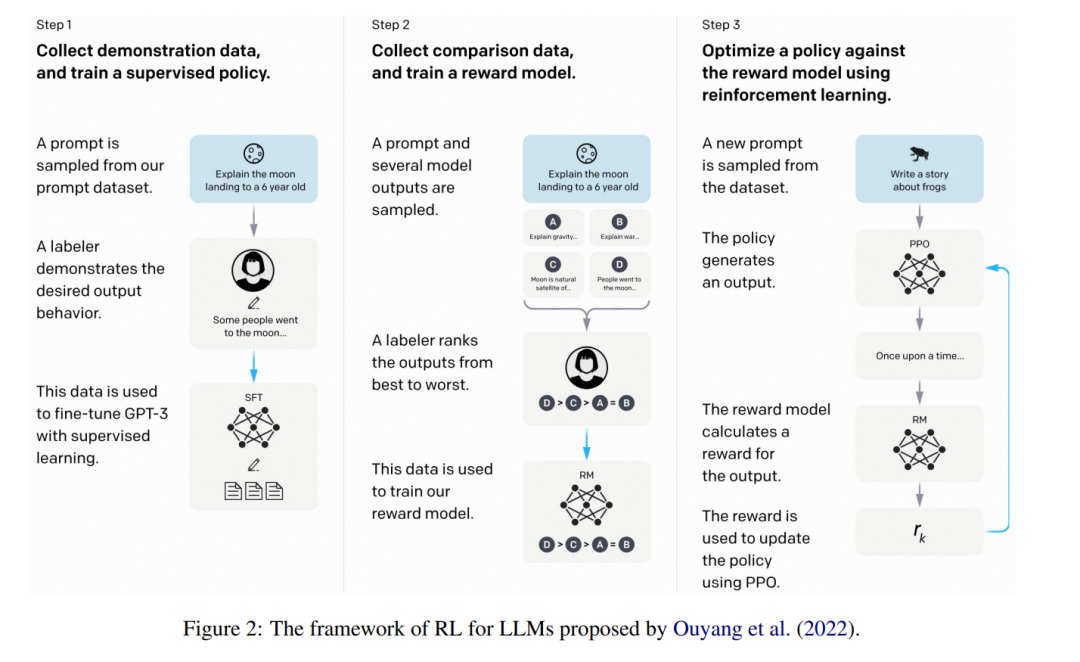
在强化学习(RL)中,有六个关键组件:代理(Agent)、环境(Environment)、状态(State)、动作(Action)、奖励(Reward)和策略(Policy)。要将RL应用于微调大型语言模型(LLMs),第一步是将这些组件映射到LLM框架中。 LLMs在预测下一个词元(next-token prediction)方面非常高效,它们将一系列词元作为输入,并根据给定的上下文预测下一个词元。从RL的角度来看,我们可以将LLM本身视为策略(Policy)。当前的文本序列代表状态(State),根据这个状态,LLM生成一个动作(Action)——即下一个词元。这个动作会更新状态,形成一个新的状态,其中包含新增的词元。在生成完整的文本序列后,使用预训练的奖励模型来评估LLM输出的质量,从而决定奖励(Reward)。 图2 展示了Ouyang等人(2022)提出的LLM强化学习框架。Ouyang等人(2022)首先使用通过监督学习训练的指令微调模型,使其能够生成结构化的响应。接着,Ouyang等人(2022)应用了以下两个步骤: 步骤1:收集比较数据并训练奖励模型
Ouyang等人(2022)收集了一个数据集,包含指令微调模型输出之间的比较,标注者指出对于给定输入,他们更喜欢哪个输出。然后,收集到的数据集用于训练一个奖励模型(Reward Model, RM),以预测人类偏好的输出。 步骤2:使用PPO优化策略对抗奖励模型
Ouyang等人(2022)将奖励模型的输出作为标量奖励,并通过PPO算法(Schulman等人,2017)对指令微调模型进行微调,优化该奖励。
强化学习增强的流行大型语言模型
近期流行的强大功能的大型语言模型(LLMs)几乎都利用强化学习(RL)来进一步增强其在后期训练过程中的表现。这些模型所采用的强化学习方法通常可以分为两大类: 1. 传统的RL方法,如基于人类反馈的强化学习(RLHF)和基于AI反馈的强化学习(RLAIF)。这些方法需要训练一个奖励模型,并且涉及复杂且通常不稳定的过程,使用如近端策略优化(PPO)(Schulman 等人,2017)等算法来优化策略模型。像InstructGPT(Ouyang 等人,2022)、GPT-4(OpenAI,2023)和Claude 3(Anthropic,2024)等模型都采用了这一方法。 1. 简化的方法,如直接偏好优化(DPO)(Rafailov 等人,2024)和奖励感知偏好优化(RPO)(Adler 等人,2024)。这些方法摒弃了奖励模型,提供了一种稳定、性能强大且计算效率高的解决方案。像Llama 3(Dubey 等人,2024)、Qwen 2(Yang 等人,2024a)和Nemotron-4 340B(Adler 等人,2024)等模型都采用了这一方法。
在这一部分,我们将详细描述每个模型,首先简要概述这些强化学习增强的大型语言模型,并解释强化学习如何在它们的后期训练过程中应用。有关这些强化学习增强的LLMs的概览见表1。

RLHF:基于人类反馈的强化学习
基于人类反馈的强化学习(RLHF)是一种训练方法,它将强化学习(RL)与人类反馈相结合,以将大型语言模型(LLMs)与人类的价值观、偏好和期望对齐。RLHF包含两个主要组件: 1. 收集人类反馈以训练奖励模型:在人类评估者提供反馈时,他们通过根据质量、相关性等因素对LLM的输出进行评分或排名。这些反馈随后用于训练一个奖励模型,该模型用于预测输出的质量,并作为RL过程中的奖励函数。 1. 使用人类反馈进行偏好优化:训练好的奖励模型指导LLM输出的优化,以最大化预测奖励,从而使LLM的行为与人类的偏好对齐。
接下来,我们将通过近期的研究来阐述这两个组件。

