
【导读】伦敦帝国理工学院教授Michael Bronstein等人撰写了一本关于几何深度学习系统性总结的书,提出从对称性和不变性的原则推导出不同的归纳偏差和网络架构。非常值得关注!
重磅!《几何深度学习》新书发布,帝国理工/DeepMind等图ML大牛共同撰写,160页pdf阐述几何DL基础原理和统一框架
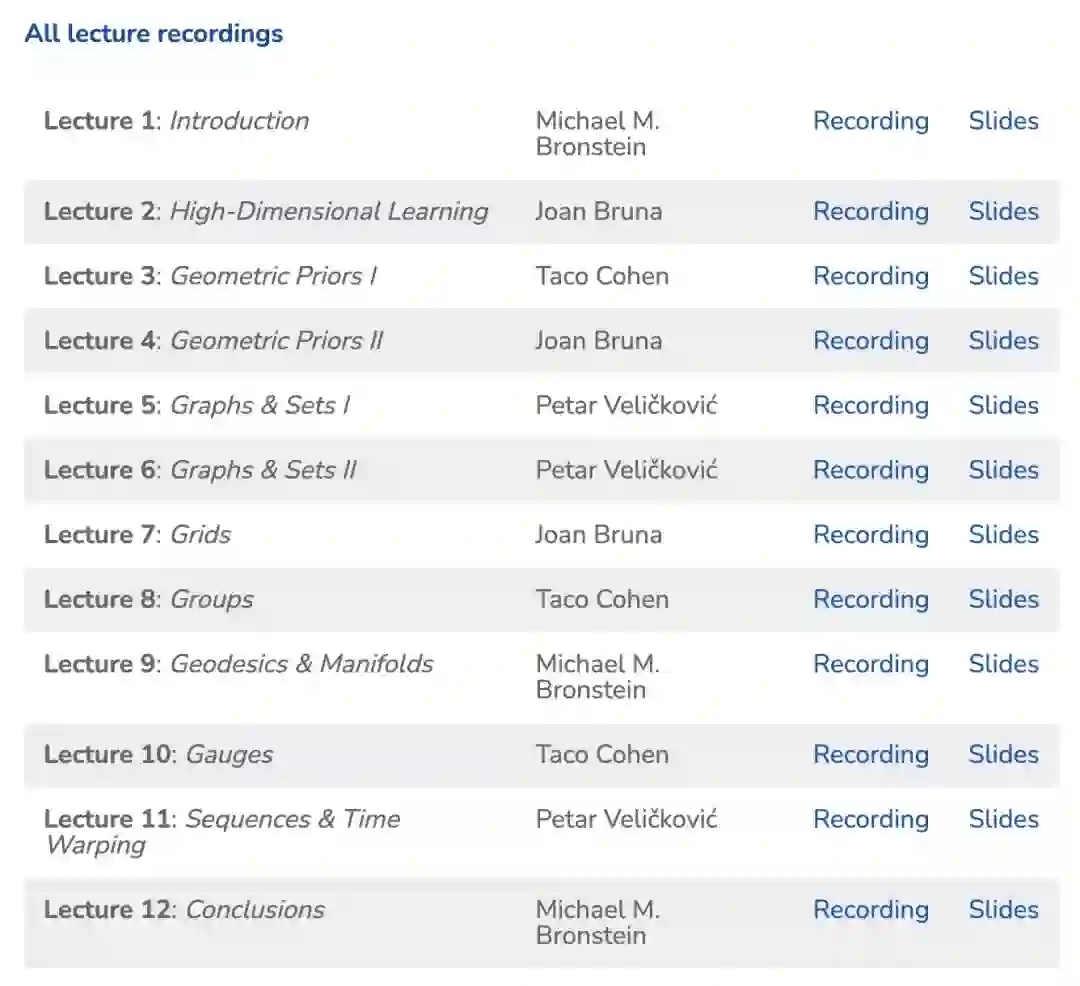
作为非洲机器智能硕士课程(AMMI 2021)的一部分,我们提供了一门关于几何深度学习(GDL100)的课程,它紧跟我们的GDL原型书的内容。我们使所有的材料和课件从这门课程公开可用,作为我们的原型书的同伴材料,以及一种方式深入到一些内容的未来迭代的书。
几何深度学习是从对称性和不变性的角度对广泛的ML问题进行几何统一的尝试。这些原理不仅是卷积神经网络的突破性性能和图神经网络的近期成功的基础,而且还为构造新型的特定于问题的归纳偏差提供了一种有原则的方法。
深度(表示)学习领域的现状让我们想起了19世纪的几何情况:一方面,在过去的十年中,深度学习在数据科学领域带来了一场革命, 以前认为可能无法完成的许多任务-无论是计算机视觉,语音识别,自然语言翻译还是alpha Go。另一方面,我们现在拥有一个针对不同类型数据的不同神经网络体系结构的动物园,但统一原理很少。结果,很难理解不同方法之间的关系,这不可避免地导致相同概念的重新发明。
几何深度学习是我们在[5]中引入的总称,指的是最近提出的ML几何统一的尝试,类似于Klein的Erlangen计划。它有两个目的:首先,提供一个通用的数学框架以推导最成功的神经网络体系结构;其次,给出一个建设性的程序,以有原则的方式构建未来的体系结构。
成为VIP会员查看完整内容
相关内容


相关VIP内容
相关资讯
相关论文