人工智能(AI)近年来取得了巨大的成功。然而,这些框架的决策逻辑通常不透明,导致利益相关者难以理解、解释或说明其行为。这一局限性阻碍了对机器学习系统的信任,特别是在医疗保健和自动驾驶等关键任务领域,导致人们对其实际应用的普遍抗拒。可解释人工智能(XAI)技术有助于机器学习模型的可解释性或可解释性,使用户能够辨别决策的依据,并可能避免不良行为。
本综述详细介绍了可解释人工智能方法的进展,从本身具有可解释性的模型到实现各种黑盒模型可解释性的现代方法,包括大语言模型(LLM)。此外,我们还回顾了利用大语言模型和视觉-语言模型(VLM)框架来自动化或改善其他机器学习模型的可解释性的方法。
使用大语言模型和视觉-语言模型作为可解释性方法,特别能够提供模型决策和行为的高级语义意义解释。本文中,我们重点介绍了最先进方法的科学原理、优缺点,并概述了不同的改进领域。在适当的地方,我们还展示了各种方法的定性和定量比较结果,以展示它们的对比。最后,我们讨论了可解释人工智能的关键挑战和未来研究的方向。
关键词 可解释人工智能 · 大语言模型 · 大语言模型的可解释性 · 可解释性方法综述
1 引言
1.1 机器学习与可解释人工智能(XAI)
近年来,人工智能(AI)因其强大的能力和解决各种现实世界问题的巨大潜力,受到了广泛关注。机器学习使得AI系统能够通过训练过程从数据中提取相关关系,然后利用这些知识在操作过程中对新实例进行准确推理。已经开发并广泛应用了多种机器学习方法。在一些应用中(例如[1, 2, 3, 4]),机器学习模型的准确性已经与甚至超越了人类专家。深度学习方法通常比其他机器学习模型获得更高的准确性。不幸的是,这一性能提升也伴随着对数据的过度需求以及整体模型复杂性,这使得机器学习系统的决策逻辑变得不透明。因此,大多数数据驱动的深度学习方法通常是黑盒性质的,其中输入直接映射到预测,而没有任何附带信息说明决策是如何得出的。然而,在医疗保健、金融和机器人等高风险应用中,利益相关者必须理解人工智能系统决策背后的基本原理。因此,越来越需要使用透明或可解释的模型,其预测可以被开发者和其他相关利益方(如监管者、经理和最终用户)理解。在模型本身不可解释的情况下,通常需要设计方法来解释其行为或预测。可解释人工智能(XAI)旨在实现这一目标。 1.2 可解释性与可解释性?
可解释性和可解释性是密切相关的概念,这些术语经常互换使用。然而,若干作者(例如[5, 6, 7, 8, 9])尝试澄清它们各自的含义和微妙差异。尽管目前尚未就这些术语的准确技术定义达成普遍共识,但其模糊含义并非争议所在。具体来说,可解释的模型被认为是那些能够突出输入与输出空间之间某种联系的模型,或者其预测机制是显而易见的,可以通过其内部架构或工作原理来理解。例如,稀疏决策树以直观的方式将输入映射到输出。相反,可解释性通常被理解为模型(或其代理)通过逻辑规则、问答或类似的丰富方式提供明确描述,以说明决策依据是什么。尽管两者含义有所不同,但我们在本文中将这些术语松散地交替使用,这在文献中是常见的做法。 1.3 可解释人工智能的好处
使用XAI方法在机器学习中的一些重要好处包括: 1. 透明性 [10, 11, 12]:可解释人工智能提高了机器学习系统的透明度,促进了人类利益相关者的理解。理解人工智能系统的运作使得开发者和用户能够最大化其优势,同时最小化潜在风险。 1. 信任 [13], [14]:理解机器学习模型的决策增强了对这些系统的信任,并增加了决策者在关键任务应用中采用它们的意愿。 1. 公平性 [15]:可解释性方法可以帮助揭示模型预测中的偏差,从而确保结果决策对所有利益相关者公平,不论其性别、种族、宗教或是否属于弱势群体。 1. 安全性 [16], [17]:可解释人工智能可以揭示机器学习系统中不符合安全要求的行为,允许在部署前或部署后解决这些问题,从而最终提高安全性。类似地,可解释性可以帮助确保机器学习模型遵循道德标准和良好实践。 1. 问责制 [18]:当机器学习模型的决策导致灾难性结果时,模型的解释可以帮助确立这些决策的合理性,或者理解为何模型失败,是否由错误或任何利益相关方的疏忽所致。最终,这使得有过错的一方能够对由设计不当或滥用导致的损失承担责任。 1. 模型调试 [19], [20]:机器学习系统的可解释性可以使得不良行为得到检测并通过后续优化加以纠正。这些优化可以提高预测准确性,并防止模型从数据中学习到虚假的相关性,进而导致不良的预测结果。这一问题通常被称为Clever Hans问题[21],在机器学习中时常遇到。
1.4 重要的XAI概念
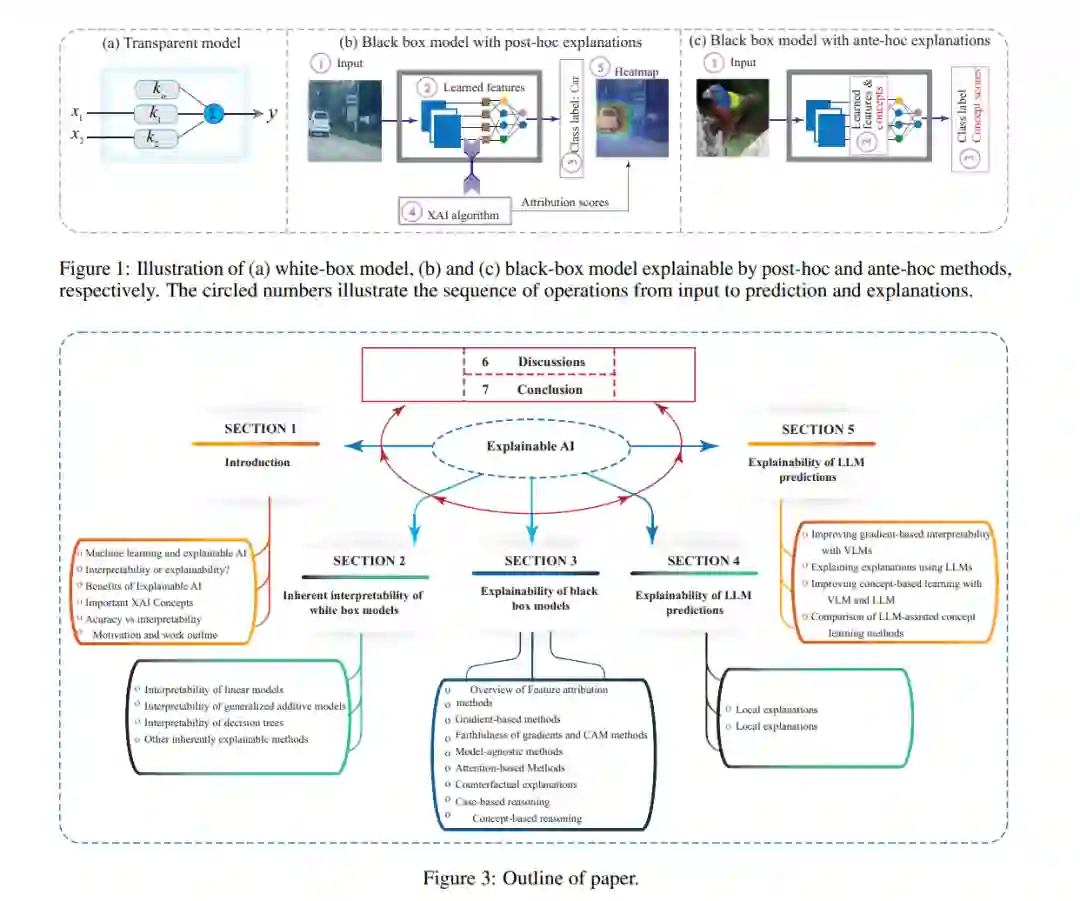
我们在本小节中简要描述了可解释人工智能中的一些重要概念。这些概念在文献中被广泛使用,并贯穿于本文。 1. 范围:解释可以具有全局或局部范围,具体取决于其覆盖面。全局解释提供了模型行为的一般性见解,而局部解释则专注于解释单一预测。一些可解释性方法可以同时解释全局行为和局部实例。 1. 适用性:如果一个解释方法的实现独立于其解释的模型,则该方法被描述为模型无关的。另一方面,模型特定的方法使用的技术是针对特定机器学习模型设计的。模型特定的可解释性方法的一个优势是,方法可能允许结合机器学习模型的细节,以获得更好和更量身定制的解释。然而,这些技术可能会以损害预测性能的方式干扰原始的黑盒模型。通常,模型无关的可解释性方法更加通用,可以应用于任何黑盒模型而无需“打开”它。 1. 实施阶段:可解释性方法可以在机器学习系统的不同阶段进行集成。这导致了两种广泛的研究方法:事后可解释性和事前可解释性。事后可解释性方法应用于模型训练后。大多数XAI技术都属于这一组。事后可解释性的核心思想是以非干扰的方式解释模型行为。然而,这种方法可能会影响忠实度,因为解释可能并不总是遵循预测的真实依据。事前可解释性技术(例如概念瓶颈模型[22])试图通过同时学习用于分类的特征和影响预测的特征,在训练或设计时为模型赋予可解释性。该方法提高了忠实度,但某些技术可能会施加额外的约束,最终影响预测准确性。一些作者将事前可解释性方法归类为天生可解释的,然而,尽管这些模型在设计时获得了可解释性,但它们需要在设计时进行明确干预,以实现这一点,与真正的天生可解释模型不同。
1.5 准确性与可解释性
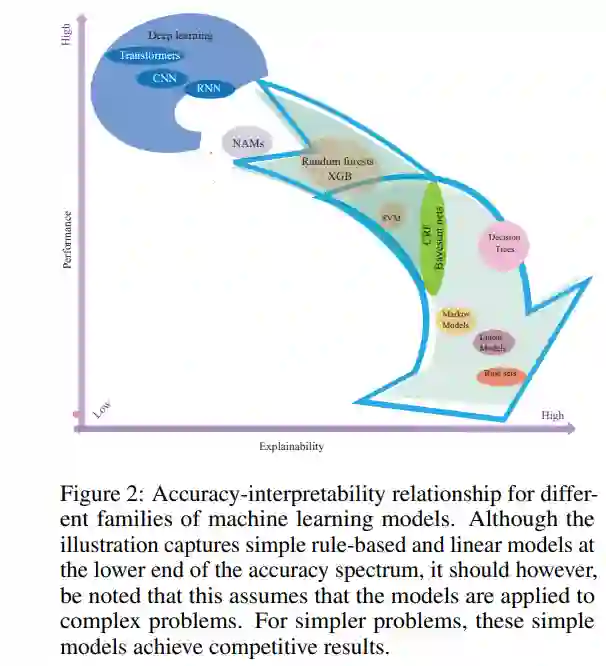
天生可解释模型是相对简单的框架,正因如此,它们的预测依据可以直观地理解。不同模型家族在天生可解释性方面表现不同,正如图2所示。最具可解释性的模型家族包括规则集、决策树和线性模型。由于其简单性,它们通常在复杂任务中表现出适度或相对较低的准确性。 另一方面,像深度神经网络这样更大更复杂的模型具有从高维训练数据中捕捉有用信息的能力,从而实现令人印象深刻的准确性,但它们的决策通常难以为利益相关者理解。因此,它们被称为不透明或黑盒模型。如图2所示,机器学习模型的可解释性和准确性通常呈相反趋势,即准确性越高,可解释性越低。这种准确性与可解释性的权衡关系是一个广泛研究的现象[23],[24],[25],并且已有一些努力[26],[27]试图在这两个目标之间进行精心平衡。 1.6 动机与工作概述
由于可解释人工智能的实际重要性和日益增加的研究工作,关于这个主题存在许多权威的综述(例如[28],[29],[30],[31],[32])。还有一些专门针对大语言模型[33],[34]或医疗保健等特定领域应用的综述[35],[36],[37]。此外,另一项最近的研究[38]回顾了利用各种形式的先验知识表示(包括逻辑规则、知识图谱)和大语言模型(LLMs)来提高深度学习模型可解释性的方法。该研究还讨论了利用先验知识来提高对抗鲁棒性和零样本泛化的技术。尽管关于该主题已有大量高质量的综述,现有的大多数工作集中在可解释性的一般概念上,往往以高层次描述相关方法。只有少数几项工作(例如[29],[32])提供了充分的深度或具体技术的详细介绍(包括解释工作原理或明确强调其优缺点)。此外,据我们所知,在这项工作的提交时,尚未有任何综述——即使是最近发布的研究——覆盖该领域一些新兴但极为重要的发展。特别是,尚未有任何工作强调大语言模型和视觉语言模型在增强和自动化其他黑盒模型可解释性方面的日益重要应用。基于这些原因,我们的动机是填补这一空白,通过全面呈现和讨论这些方法中的相关问题。我们全面回顾了涵盖所有类别的可解释性方法,特别是在第5节中,我们重点讨论了利用视觉语言模型和大语言模型提高可解释性的技术。与众不同的是,我们还提供了关于一些最流行方法的详细定量结果。 本文结构如下:第1节介绍了本研究的总体背景;第2节涵盖了内在可解释框架及其关键原则、挑战和解决方案;第3节讨论了如何解释一般的黑盒模型;第4节详细介绍了大语言模型的可解释性;第5节讨论了利用视觉语言模型和大语言模型提高和自动化可解释AI的技术;第6节讨论了重要问题、当前状态以及未来可能的发展;第7节通过总结本文的重要要点来结束本工作。图3提供了本工作更详细的结构纲要。