

随着在线内容中图像数量的激增,语言引导的图像检索(Language‑Guided Image Retrieval,LGIR)在过去十年间成为研究热点,涵盖了输入形式多样的若干子任务。虽然大型多模态模型(Large Multimodal Models,LMMs)的发展显著推动了这些任务的进步,但现有方法往往将各子任务割裂处理,需要为每个任务单独构建系统。这不仅增加了系统复杂度与维护成本,还因语言歧义与图像内容复杂性而加剧检索不准确、结果不可靠的问题。
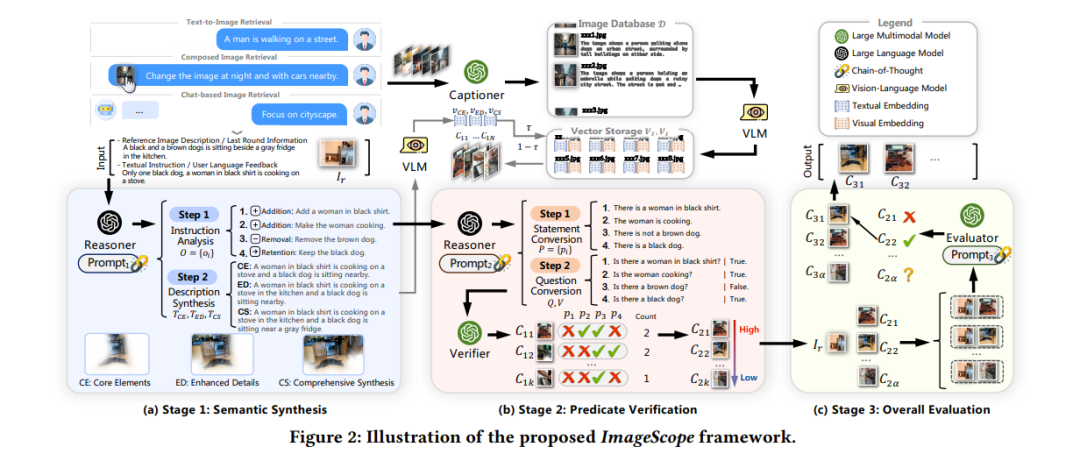
为此,我们提出 ImageScope ——一个无需额外训练的三阶段框架,通过集体推理(collective reasoning)统一解决 LGIR 任务。其核心洞见在于利用语言的组合性:先将各种 LGIR 任务转化为通用的文本‑到‑图像检索流程,再借助 LMM 的推理作为统一验证环节来精炼结果。 * 阶段一:基于思维链(Chain‑of‑Thought, CoT)推理,在不同语义粒度层面综合生成检索意图,从而提升框架的鲁棒性。 * 阶段二与阶段三:先对检索结果进行局部谓词命题验证,然后在全局范围内执行成对比较评估,实现反思式优化。
在六个 LGIR 数据集上的实验表明,ImageScope 的性能全面超越竞争性基线。进一步的综合评估与消融实验亦充分验证了我们设计的有效性。
成为VIP会员查看完整内容
相关内容
Arxiv
204+阅读 · 2023年4月7日

相关VIP内容
相关资讯
相关论文
Arxiv
204+阅读 · 2023年4月7日