

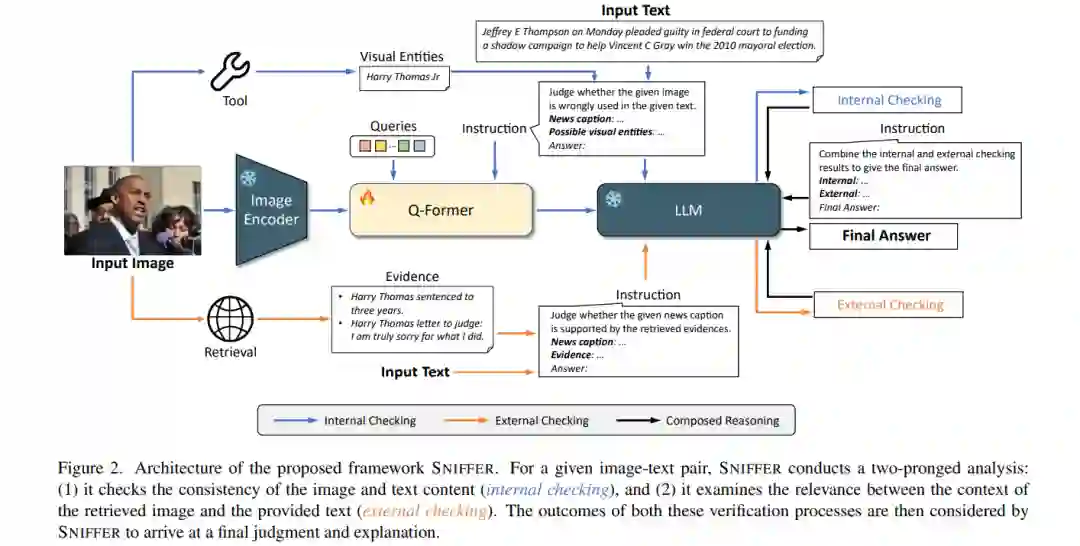
谣言是一个普遍的社会问题,因其潜在的高风险而受到关注。脱离上下文(OOC)的谣言,即将真实图片与虚假文本结合,是误导受众的最简单也是最有效的方式之一。现有方法侧重于评估图文一致性,但缺乏令人信服的解释来支持其判断,这对于揭穿谣言至关重要。尽管多模态大型语言模型(MLLMs)具有丰富的知识和天生的视觉推理及解释生成能力,但它们在理解和发现微妙的跨模态差异方面仍然缺乏成熟。在本文中,我们介绍了SNIFFER,这是一个专为检测和解释OOC谣言而特别设计的新型多模态大型语言模型。SNIFFER采用了基于InstructBLIP的两阶段指导微调。第一阶段细化模型对通用对象与新闻领域实体的概念对齐,第二阶段利用仅限语言的GPT-4生成的OOC特定指令数据来微调模型的鉴别能力。通过外部工具和检索增强,SNIFFER不仅能够检测文本和图像之间的不一致性,而且还利用外部知识进行情境验证。我们的实验表明,SNIFFER的性能超过了原始MLLM 40%以上,并且在检测准确性方面超过了最先进的方法。SNIFFER还提供了准确和有说服力的解释,经过量化和人类评估验证。
成为VIP会员查看完整内容
相关内容
Arxiv
225+阅读 · 2023年4月7日
相关VIP内容
相关资讯
相关论文
Arxiv
225+阅读 · 2023年4月7日