

随着视觉与语言基础模型在多模态理解、推理与生成方面取得显著进展,越来越多的研究致力于将这类智能拓展至物理世界,推动了视觉-语言-动作(Vision-Language-Action, VLA)模型的蓬勃发展。尽管现有方法看似多种多样,我们观察到当前的VLA模型实际上可以统一于一个通用框架:视觉与语言输入经过一系列VLA模块处理,生成一串“动作 token”(action tokens),这些 token 逐步编码出更加具象、可执行的信息,最终产出可执行的动作。我们进一步发现,区分不同VLA模型的主要设计差异在于其“动作 token”的构建方式。具体而言,这些 token 可被归类为语言描述、代码、可供性(affordance)、轨迹、目标状态、潜在表示、原始动作以及推理等类型。然而,目前对动作 token 缺乏系统性理解,这在很大程度上阻碍了VLA模型的有效发展,也使未来的研究方向变得模糊。因此,本文旨在从动作离散化(action tokenization)的视角对现有VLA研究进行分类与解读,提炼各类 token 表达方式的优势与局限,并指出亟待改进的关键环节。通过本综述的系统梳理与分析,我们希望为VLA模型的发展提供整合性视角,突显当前研究中尚未充分探索但具有潜力的方向,并为未来研究提供指导,从而推动通用智能的实现。
执行摘要
• VLA统一框架与动作 token 分类体系:当前的视觉-语言-动作(VLA)模型可统一于一个通用框架:视觉与语言输入经由一系列VLA模块处理,生成一串动作 token,这些 token 逐步编码出更具现实对应性和可执行性的信息,最终产出可执行的动作。在该框架中,动作 token 可被划分为八类:语言描述、代码、可供性(affordance)、轨迹、目标状态、潜在表示、原始动作以及推理。VLA中的动作 token 是类比于大语言模型(LLM)中语言 token 的通用扩展形式。 • 动作 token 趋势:VLA模型的未来不在于某一类动作 token 的主导地位,而在于各类 token 的战略性融合。语言运动表达能力有限,难以成为主流;而语言规划则在任务分解中仍然至关重要。代码是一种强大的替代形式,其潜力将在构建整合感知与动作原语的函数库后得到释放,能够解决复杂的、长时序的任务。可供性(指“做什么”)与轨迹(指“如何做”)之间的协同正日益显现,二者的组合可由世界模型(world models)支撑,通过预测视觉目标状态为上述两类 token 的生成提供依据。潜在表示虽具前景,但面临训练挑战;原始动作代表端到端学习的理想形式,但受限于数据的稀缺性。最后,推理作为“元 token”提升了所有其他 token 的效能,其形式正在从纯语言推理演变为结合多模态反馈和测试时自适应计算的动作 token 推理。 • 新兴的动作 token 类型:动作 token 类型受到基础模型能力的驱动。更强的模型及新兴模态(如音频、触觉)将催生新的 token 类型与子类型。 • VLA架构发展趋势:高效的VLA模型可能采用分层架构。顶层利用语言描述与代码执行长时规划与逻辑控制;短期内,底层预计将整合视频预测的目标状态、轨迹的流建模以及可供性的三维交互预测,形成中间动作表示,最终映射为原始动作。长期来看,底层将朝着完全端到端方式演进,直接从子任务级输入预测原始动作。推理模块始终贯穿于整个VLA模型体系,根据需求动态介入。 • 从模仿学习到强化学习:通过引入强化学习,VLA模型可克服模仿学习的局限,实现更类人的试错探索与自主学习。然而,实际部署仍需更高效的强化学习算法,以应对高重置成本与低交互效率问题。此外,多模态大模型(VLM)可用于自动生成密集奖励函数,从而加速模型训练与部署。 • 从VLA模型走向VLA智能体:应有意识地推动VLA模型向VLA智能体演进,后者是具备主动性的系统,在感知-动作能力之上融合记忆、探索、规划与反思等更广义的认知结构。这一转变也要求从当前线性处理架构过渡至更复杂的双向图结构拓扑。 • 进步的三元组:模型、数据与硬件:具身智能(Embodied AI)的目标是应对物理世界中无结构、开放性的问题情境,这一目标要求模型、数据与硬件三者协同演进。然而目前的研究仍受限于受约束的机器人平台与稀缺的高质量具身数据,大多数研究仍局限在与真实世界差距较大的实验室设定中,导致该领域仍处于初期阶段。实现强健的通用智能,需要模型、数据与硬件同步发展,而非各自为战。 • 安全性与对齐性:当前的VLA研究主要聚焦于模型能力,未来的工作必须更加重视安全性与人类对齐问题。

1. 引言
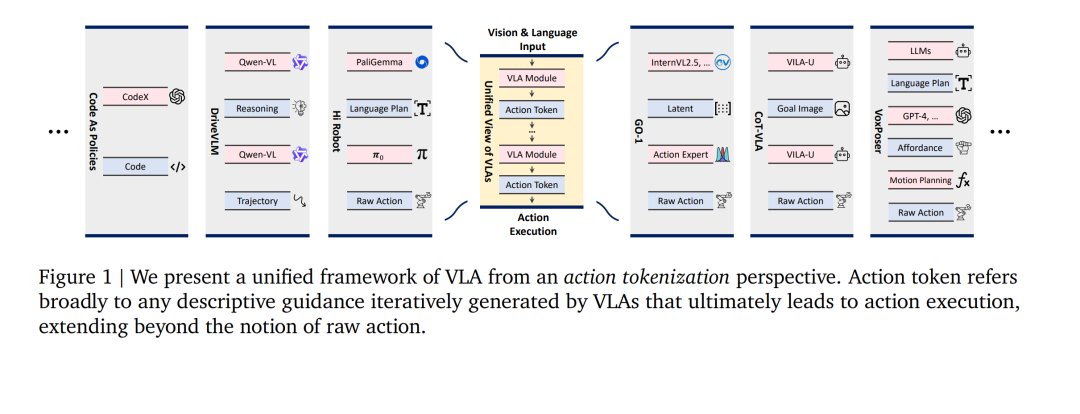
近年来,人工智能(AI)在迈向通用智能的道路上取得了显著进展。其中的核心推动力是基础模型(Foundation Models)[1, 2]的兴起——这类模型通常是基于互联网规模数据训练的大型神经网络,能够通过学习训练语料中蕴含的多样知识与模式,获得广泛且可迁移的能力。以大型语言模型(LLMs)为代表,如GPT-4 [3] 和 DeepSeek-R1 [4],在自然语言理解、推理与生成方面表现出色,构成众多文本应用的基础。与此同时,视觉基础模型(VFMs)如 CLIP [5]、DINO [6, 7] 与 SAM [8, 9],也在多种视觉任务中展现出强泛化能力。 在此基础上,视觉-语言模型(VLMs)进一步融合视觉与文本模态,实现了多模态处理与生成,代表性模型包括 GPT-4o [10]、Gemini 2.5 Pro [11] 和 Qwen2.5-VL [12]。这些模型共同具备广泛的世界知识、在复杂任务中的优异表现,以及对新颖场景的良好泛化能力,使其具备高度的通用性,可广泛应用于多个领域。 然而,尽管这些模型能力卓越,它们仍局限于数字世界,难以直接作用于现实物理任务。为突破这一边界,研究者开始探索如何利用基础模型的感知与认知能力来提升任务执行效果,从而将智能拓展至物理世界。这一研究方向促成了视觉-语言-动作模型(Vision-Language-Action, VLA)的兴起。我们将其正式定义为:在视觉与语言输入条件下生成动作的模型,并基于至少一种大规模视觉或语言基础模型构建。 例如,SayCan [13]、PaLM-E [14] 和 Code as Policies [15] 利用LLMs或VLMs的语言与代码生成能力,生成用自然语言或可执行代码表达的高层动作计划,随后由低层控制器解释并执行;另一些研究则侧重于从基础模型中提取可执行知识,如为任务相关物体生成可供性 [16],或预测场景级轨迹以引导下游控制 [17]。还有一类工作专门通过预训练构建具身动作序列的潜在表示,并使VLMs适应于预测这些表示,随后由策略控制器进行解码与执行 [18]。此外,亦有研究尝试将视觉与语言领域中观察到的扩展规律(Scaling Laws)[19, 20] 引入具身智能领域,构建大规模具身数据集,并基于视觉-语言基础模型进行端到端训练,从而实现通用型智能体 [21, 22, 23]。 上述多样化的技术路径促使VLA模型在机器人操作[24, 25]、导航任务[26, 27] 与自动驾驶[28, 29, 30] 等场景中快速涌现,展现出在多任务学习 [31]、长时序任务完成 [22] 和强泛化能力 [32] 方面的潜力。凭借基础模型的智能能力,VLA为解决具身AI中长期存在的问题(如数据稀缺与跨身体可迁移性差)提供了新思路,并为智能体在开放物理环境中通过开放词汇指令完成开放式任务铺平了道路。 然而,VLA模型的快速发展、令人鼓舞的实验成果与日益多样化的架构,亟需一次及时而系统性的回顾,以为未来研究提供指导。尤其值得注意的是,看似各异的架构背后存在显著的共性:我们观察到,现有VLA模型通常可抽象为一个统一框架,即:视觉与语言输入经过一系列VLA模块的迭代处理,生成一串动作 token(action tokens),这些 token 逐步编码出更具信息性与可执行性的指导,最终产出可执行动作。 我们将VLA模块正式定义为:在VLA模型中支持端到端梯度传播的最大可微子网络,或不可微的功能模块(如运动规划)。若多个神经组件相连且联合优化,它们视为同一模块的一部分。借鉴VLM中语言与图像 token 的命名方式,我们将VLA模块的输出统一称为动作 token。此外,某些在VLA模块内构建的语义中间表示(如通过专用预训练获得的潜在表示 [18] 与目标图像 [33])也被视为动作 token。 图1展示了几个代表性VLA模型中VLA模块与动作 token 的实例,说明它们如何在我们提出的统一框架下进行表征与理解。从该视角看,VLA模型的主要差异在于动作 token 的构建与组织方式。这些 token 可归为八类:语言描述 [24, 31]、代码 [15, 34]、可供性 [16, 35]、轨迹 [36, 37]、目标状态 [38, 33]、潜在表示 [39, 18]、原始动作 [21, 22] 和推理 [40, 41]。图2则以一个具身任务为例,展示了各类 token 的常见形式。 值得强调的是,动作 token 的设计几乎影响VLA模型的方方面面,包括基础模型的选择、数据需求、训练与推理效率、可解释性、可扩展性,以及跨任务与跨环境的适用性。因此,动作 token 的构建方式(即“动作离散化”)是VLA模型设计的核心所在,亟需深入理解。 尽管其重要性日益凸显,当前学术界对于动作 token 构建的系统性理解仍十分有限。本综述旨在填补这一空白,从动作离散化的视角出发,对VLA研究进行结构化梳理。我们首先回顾视觉与语言基础模型的发展历程,探讨其设计选择、扩展策略与能力表现;随后聚焦具身智能,尤其是VLA模型的演进过程,并将VLA定位为下一代AI发展的前沿(第2节)。在此基础上,我们通过提出动作 token 的分类体系、定义、对比与组织模式,介绍VLA研究的整体格局(第3节);之后各章节将深入分析每一类动作 token 的研究动机、代表方法、属性特征、优势与局限,以及未来改进方向(第4至11节)。我们还总结了可扩展的数据来源,为后续研究提供支持(第12节)。最后,结合当前研究现状与新兴趋势,提出推动VLA领域发展的未来研究方向(第13节)。 通过这一视角,我们希望为下一代具身智能系统的设计与发展提供有价值的洞见与可行的指导。