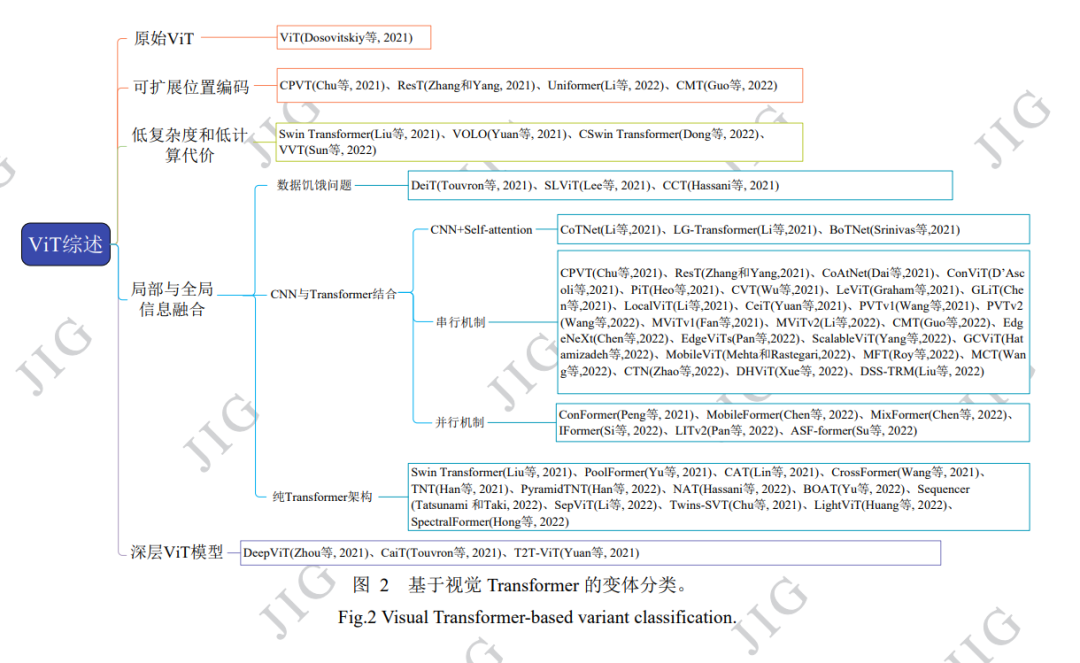
图像分类是图像理解的基础,对计算机视觉在实际中的应用具有重要作用。然而由于图像目标形态、类型的多样 性以及成像环境的复杂性,导致很多图像分类方法在实际应用中的分类结果总是差强人意,例如依然存在分类准确性低、假 阳性高等问题,严重影响其在后续图像及计算机视觉相关任务中的应用。因此,如何通过后期算法提高图像分类的精度和准 确性具有重要研究意义,受到越来越多学者的关注。近些年,随着深度学习技术的快速发展及其在图像处理中的广泛应用和 优异表现,基于深度学习技术的图像分类方法研究也取得了巨大进展。 为了更加全面地对现有方法进行研究,紧跟最新研 究进展,本文对 Transformer 驱动的深度学习图像分类方法和模型进行了系统梳理和总结。与已有主题相似综述论文不同, 本文重点对 Transformer 变体驱动的深度学习图像分类方法和模型进行归纳和总结,包括基于可扩展位置编码的 Transformer 图像分类方法、具有低复杂度和低计算代价的 Transformer 图像分类方法、局部信息与全局信息融合的 Transformer 图像分类 方法以及基于深层 ViT 模型的图像分类方法等,从设计思路、结构特点和存在问题等多个维度多个层面深度分析总结现有 方法模型。为了更好对不同方法模型进行比较分析,在 ImageNet、CIFAR-10 和 CIFAR-100 等公开图像分类数据集上,采用 准确率、参数量、浮点运算数(FLOPs)、总体分类精度(overall accuracy, OA)、平均分类精度(average accuracy, AA)和 Kappa(κ) 系数等评价指标,对不同方法模型的分类性能进行了实验评估。最后,对未来研究发展方向进行了展望。 http://www.cjig.cn/jig/ch/reader/view_abstract.aspx?flag=2&file_no=202208060000002&journal_id=jig 图像分类旨在识别图像中存在目标对象所属具 体类别,是图像处理和计算机视觉领域的重要研究 方向,具有重要实际应用价值。然而由于实际应用 中,图像目标的形态、类型多样,且成像环境复杂, 现有方法的分类效果却总是差强人意,存在分类准 确性低、假阳性高等问题,严重影响其在后续图像 及计算机视觉相关任务中的应用。因此,如何通过 后期算法提高图像分类的精度和准确性,具有重要 研究意义,受到越来越多学者的关注。 在过去的最近十几年间,由于其优异的特征提 取能力,以卷积神经网络 (convolutional neural network,CNN)及其变体,如 VGGNet(Visual Geometry Group) (Simonyan 和 Zisserman,2015)、Inceptions (Szegedy 等,2014)、ResNe(X)t(residual networks)(He 等, 2015; Xie 等, 2017)、DenseNet(densely connected convolutional network)(Huang 等, 2018)、MobileNet (Howard 等, 2017)、EfficientNet (Tan 和 Le,2019)、 RegNet (Parmar 等, 2019)和 ConvNeXts (Liu 等, 2022) 等为代表的深度学习技术被广泛应用于各种图像处 理任务,并取得了较好的处理效果。作为后起之秀, 这些年在自然语言处理领域大放异彩的 Transformer(Vaswani 等, 2017)模型,由于较强的远 距离建模和并行化序列处理能力,近年来逐渐引起 图像处理和计算机视觉领域研究者的兴趣,并在目 标检测(Carion 等, 2020)、语义分割(Wang 等, 2021)、 目标跟踪(Chen 等,2021)、图像生成(Jiang 等,2021)和 图像增强(Chen等,2021)等应用中表现出良好的应用 性能。ViT(vision transformer) (Dosovitskiy 等,2021) 是 google 团队提出的第一个利用堆叠的 Transformer 编码器代替传统 CNN 的网络模型。相 较于传统 CNN,ViT 通过将输入图像划分为一个个 的图像块(patch),实现对待处理图像的全局建模和 并行化处理,极大提升了模型的图像分类能力。目 前尽管 ViT 模型在图像处理和计算机视觉应用中已 取得了很好成效,但研究(Guo 等,2022)发现,与目 前最先进的 CNN 模型相比,现有 ViT 模型在视觉 任务中的表现仍存在差距。分析其原因,主要有: (1) 绝对位置编码导致现有模型可扩展性能差;(2) 自注意力机制与分辨率计算上呈二次方关系带来高 昂的计算开销;(3) 缺乏归纳偏置导致数据饥饿和收 敛速度慢问题;(4) 深层 Transformer 存在注意力崩 溃问题。 针对上述问题,在过去的两年间,研究者们开 展了更为深入地研究,并先后推出数篇关于 Transformer 的技术综述,如(Tay 等,2022)回顾了 Transformer 的效率,(Khan 等,2021)和(Han 等, 2022) 总结了一些早期的视觉 Transformer 和一些注意力 模型,(Lin 等, 2022)提供了对 Transformer 的各种变 体的系统评论,并粗略地给出了 Transformer 在不同 视觉任务中的应用。(Liu 等,2022)提出根据动机、结 构和使用场景组织这些方法。(Xu 等, 2022)根据任务 场景对它们进行分类。 与以上已有综述论文不同,为了使读者对最新 研究进展有一个更为全面、更为系统、更为深入的 了解,紧跟最新研究进展,本文对 2021 年 1 月至 2022 年 12 月 31 间发表的各种 Transformer 驱动的 深度学习图像分类方法和模型进行了系统梳理,重 点对 ViT 变体驱动的图像分类方法进行了归纳和总 结,包括可扩展的位置编码、低复杂度和低计算代 价、局部信息与全局信息融合以及深层 ViT 模型等。
本文主要贡献如下: (1) 分类总结了近年来 Transformer 驱动的深度 学习图像分类方法和模型,介绍了各类方法的核心 思想,分析了现有方法存在问题,以及可能的解决 方案; (2) 系统梳理了 Transformer 驱动的深度学习图 像分类任务需要解决的关键性科学问题,并对未来 的研究方向及发展趋势进行了展望。 本文其余部分的安排如下:第 1 节简要介绍 Transformer 基本概念、原理和结构;第 2 节先简单 介绍 ViT 的概念、原理和结构,随后由 ViT 设计之 初所存在的问题出发对可扩展的位置编码、低复杂 度和低计算代价、局部信息与全局信息融合以及深 层 ViT 模型进行介绍;第 3 节对不同方法模型的实 验结果进行分析;第 4 节对未来研究发展趋势和研 究方向进行了展望。