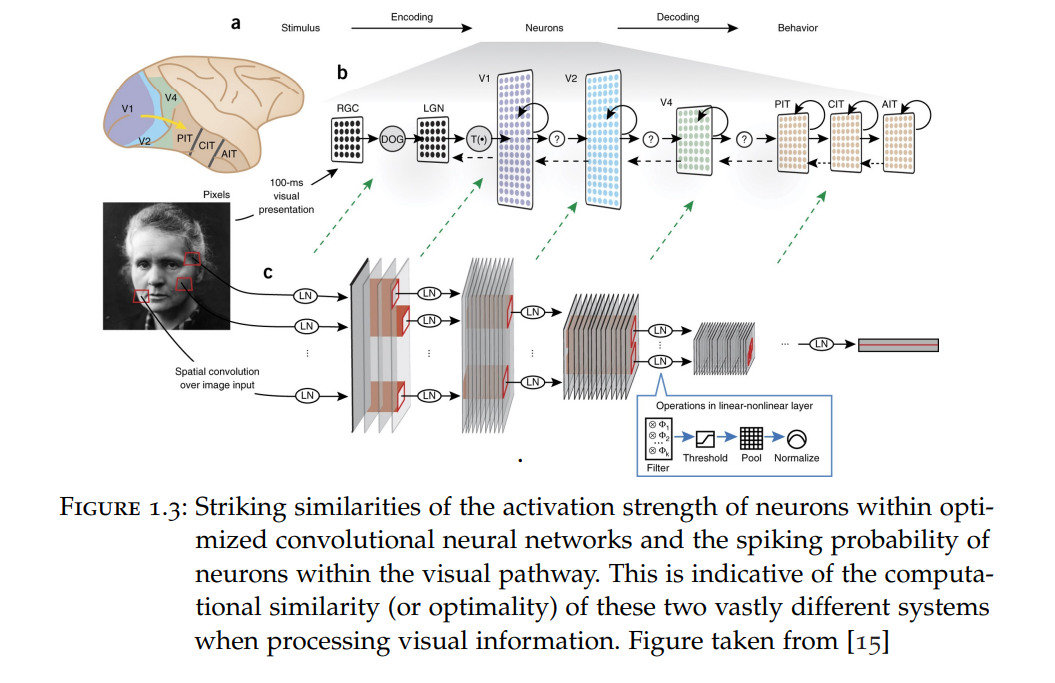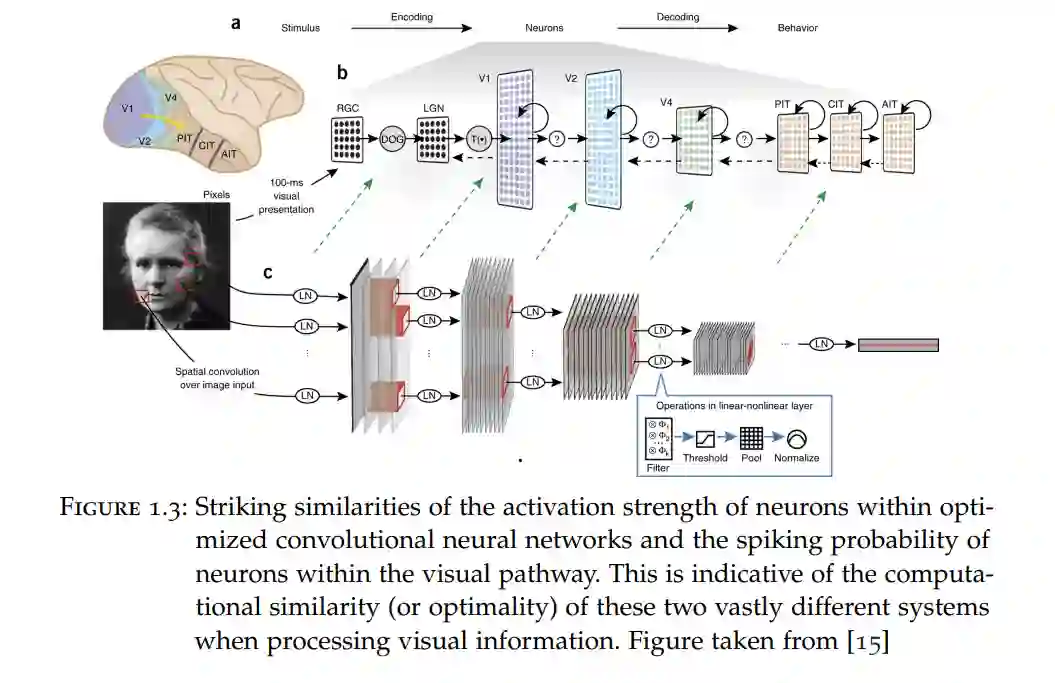
我们目前正经历着一场人工智能(AI)革命。生成式AI和特别是大型语言模型(LLMs)的显著改进正在推动这场革命。然而,这些大规模AI系统虽然强大,但更难理解。一旦训练完毕,它们的内部工作机制仍然是一个既迷人又可能令人恐惧的谜团。问题在于,作为这些系统的创造者,我们如何理解和控制它们,以及是什么驱动它们的行为。 在本论文中,我将尝试通过机械解释性(MI)的工具来理解深度神经网络的某些特性。这些工具让人联想到神经科学家的工具:1)分析脑细胞的连接性(连接组学) 2)测量和分析神经元活动 3)测量在进行中的计算中的主动干预的效果。尽管对大型深度学习模型的严格理解尚不可及,但在本论文中,我将提供通过迭代解释性实现这一目标的可能路径的证据:一个设计、训练和分析AI系统的迭代过程,其中通过MI获得的洞察力导致更强大和更可解释的模型。 首先,我提供了证据,证明在单独研究时,可以理解Transformer(用于LLMs的人工神经网络架构)令人着迷的上下文学习特性。作为第一步,我们分析了在少量回归数据上训练的小型Transformer模型的权重。通过使用MI的工具,我们可以逆向工程这些训练好的Transformer,这些Transformer配备了线性自注意力层,并展示了它们在前向动态中基于梯度下降和上下文数据隐含地学习内部模型。 其次,我将解决这一简单设置中的一个重要缺陷,并通过训练自回归Transformer更接近LLMs。在这里,我们训练模型来预测由线性动态获得的元素序列中的下一个元素。同样,借助神经科学家的工具,我们可以逆向工程这些自回归模型,并确定模型内部 i)构建优化问题 和 ii)通过基于梯度下降的算法解决这些问题。隐藏在模型权重中的这个算法允许我们在训练后将模型重新用作上下文学习者。基于这些洞察,我们然后闭合了解释性循环,并提出了一种新的自注意力层,该层可以在设计时在单个层内解决已识别的优化问题。在提供更好解释性的同时,我们在简单实验和语言建模中展示了性能的改进。 第三,我将展示在元学习和持续学习背景下的另一个迭代解释性的例子,我们在其中改进了著名的与模型无关的元学习(MAML)的性能和解释性。MAML的目标是学习一种网络初始化,使网络能够快速适应新任务。基于通过机械解释性获得的先前洞察,我们提出了稀疏MAML,这是一种MAML变体,此外还决定主动停止学习某些权重:它学会了在哪里学习。尽管在常见的少样本分类和持续学习基准中表现出性能改进,稀疏MAML提供了一个成功解释性循环的另一个例子,因为所学习的解决方案在设计上允许更好的解释性。