

检索增强生成(RAG)是一种强大的技术,通过从外部来源检索附加信息(如知识、技能和工具),增强下游任务的执行。图谱由于其内在的“由节点通过边连接”的特性,能够编码大量异质性和关联性的信息,这使得它成为RAG在众多现实应用中的宝贵资源。因此,近年来我们看到越来越多的研究关注将图谱与RAG结合,即图谱增强生成(GraphRAG)。然而,与传统的RAG不同,在传统RAG中,检索器、生成器和外部数据源可以在神经嵌入空间中统一设计,而图谱结构化数据的独特性(如多样化格式和领域特定的关联知识)在设计GraphRAG时,尤其是在不同领域的应用中,带来了独特且显著的挑战。鉴于其广泛的应用性、相关的设计挑战以及GraphRAG的快速发展,迫切需要对其关键概念和技术进行系统且最新的综述。基于这一动机,我们提出了关于GraphRAG的全面且最新的综述。我们的综述首先通过定义其关键组成部分(包括查询处理器、检索器、组织器、生成器和数据源)来提出一个整体性的GraphRAG框架。此外,我们认识到,不同领域中的图谱展示了不同的关联模式,并且需要专门的设计,因此我们回顾了针对每个领域量身定制的GraphRAG技术。最后,我们讨论了研究挑战,并集思广益,提出了激发跨学科机会的研究方向。我们的综述资源库可以通过以下链接公开访问:https://github.com/Graph-RAG/GraphRAG/。
1 引言
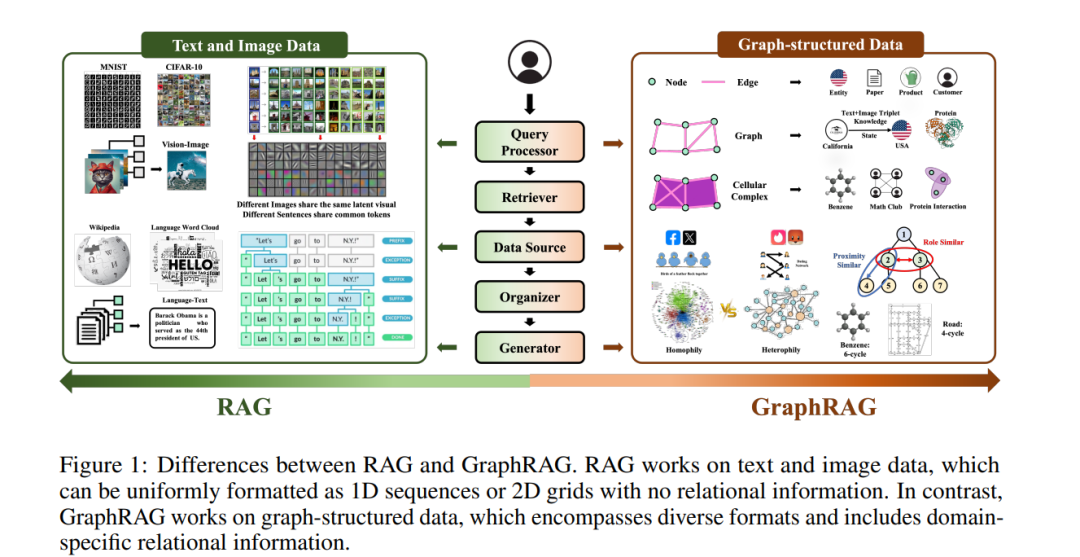
**检索增强生成(RAG)**作为一种通过从外部数据源检索附加信息来提升下游任务执行的强大技术,已经成功应用于各种现实世界的应用中[86, 119, 512, 549]。在RAG框架中,检索器根据用户定义的查询或任务指令检索附加的知识、技能和工具。检索到的内容会被一个组织器加以精炼,并与原始查询或指令无缝结合,随后输入生成器以生成最终答案。例如,在进行问答(QA)任务时,经典的“检索-再阅读”框架[190, 195, 466, 560]通过检索外部事实知识来提升答案的准确性,这对于促进社会福祉并减轻高风险场景中的风险(如医疗、法律、金融和教育咨询[465, 470, 513])具有显著的益处。此外,最近大规模语言模型(LLM)的进展进一步强调了RAG在增强LLM的社会责任方面的作用,如减少幻觉[396]、提高可解释性和透明度[202]、实现动态适应性[359, 418]、减少隐私风险[510, 511]、确保可靠性/鲁棒性响应[104, 458]以及促进公平对待[361]。
在RAG取得前所未有的成功基础上,考虑到图谱在现实世界应用中的普遍性[543],最近的研究探索了将RAG与图结构数据相结合。与文本或视觉数据不同,图结构数据通过其固有的“由节点通过边连接”的特性编码异质性和关联性的信息。例如,通过社交关系连接的社交网络中的个体通常表现出同类行为[290],规划中的序列决策步骤遵循因果依赖关系[452],而分子中的原子属于相同功能组时具有独特的结构属性[102, 506]。设计利用关系信息的RAG需要将其核心组件(如检索器和生成器)进行调整,以无缝地整合图结构数据,从而形成图谱增强生成(GraphRAG)。与主要使用语义/词汇相似性检索的RAG不同,GraphRAG通过利用基于图的机器学习(如图神经网络(GNN))和图/网络分析技术(如图遍历搜索和社区检测[97, 427])在捕捉关系知识方面提供了独特的优势。例如,考虑查询“用于治疗上皮样肉瘤且影响EZH2基因产物的药物是什么?”[450],仅依赖于语义/词汇相似性进行的BM25或嵌入式检索会忽略图结构中编码的关系知识。相反,一些GraphRAG方法会沿着关系路径“疾病(上皮样肉瘤)→[指示]→药物←[靶标]←基因/蛋白质(EZH2基因产物)”遍历图谱,检索上皮样肉瘤疾病的邻居,通过关系[指示],检索EZH2基因的邻居,通过关系[靶标],并找到它们交集中的药物[185, 270, 427]。此外,一些领域涉及具有极其复杂几何形状的实体,这要求设计专门的图编码器(或更精确地说,几何编码器)以适当表达这些结构特征[276, 525]。例如,分子图中的3D结构[]以及常见的产品分类层级树结构(如亚马逊[527])和文档分割结构(如使用Adobe Acrobat时[535]),以及社交网络(如Snap[276])中的结构,都需要精心设计的图编码器来捕捉结构的细微差别。简单地将节点文本转换为语言并输入LLM无法表达复杂的几何信息,并且随着邻接层次的增大,文本描述呈指数级增长,从而变得不可行。
尽管GraphRAG相对于RAG具有上述优势,设计合适的GraphRAG面临前所未有的挑战,原因在于图结构数据存在以下差异:
-
差异1 - 统一格式与多样格式信息:与传统RAG不同,传统RAG中语义信息可以统一表示为图像补丁的二维网格或文本语料的二维序列,而图结构数据往往包含多种格式,并存储在异质的数据源中[4, 26, 433]。例如,文档图将实体嵌入为句子块[97, 427],知识图将图信息存储为三元组或路径[38],分子图由高阶结构(如细胞复合物)构成[26],如图1所示。一些图数据可能甚至是多模态的(例如,文本属性图同时包括结构属性和文本属性,场景图结合了结构和视觉)。因此,这种多样性要求不同的RAG设计。对于检索器,传统RAG假设目标信息被索引在图像或文本语料库中,可以统一表示为向量嵌入,并支持“一刀切”的嵌入检索。然而,GraphRAG的检索器必须考虑目标信息的具体格式和来源,使得“一刀切”的设计变得不切实际。在处理知识图问答时,节点、边或子图的信息通常通过图搜索进行检索,而不是直接依赖基于嵌入的相似性检索[418, 490]。这种检索操作通常通过实体链接、关系匹配和图搜索算法(如广度优先搜索、深度优先搜索、蒙特卡洛树搜索和A*搜索)来识别相关的节点/边/子图[394, 418, 568],如果仅通过深度学习基于嵌入的相似性搜索,是无法实现的。此外,检索器的设计应确保足够的几何表达能力,以捕捉结构细节。例如,在从规划图中检索API以实现特定目标时[354, 355, 452],必须使检索器具备方向感知能力。这使得API可以按正确的顺序执行资源依赖操作,从而防止冲突并避免无效操作。同样,设计能够区分高阶子图结构的表达性检索器,例如区分6环苯和4星甲烷,3星T型交叉口与4星道路,这对于药物设计中的疾病治疗[138]以及城市规划中的道路建设[208]至关重要。除了检索器外,生成器也需要专门的设计。当检索内容包括复杂的图结构和文本属性时,简单地将子图的文本语言化并将其连接到提示中可能会掩盖关键信息。在这种情况下,使用图编码器(如GNN)对图进行编码,再将其融入生成过程中,可以帮助保留结构的细微差别[133, 243, 433, 442, 454]。
-
差异2 - 独立信息与相互依赖信息:在传统RAG中,信息是独立存储和使用的。例如,文档会被分割成块,如单独的句子、段落或固定数量的标记,并根据文档上下文和下游任务进行处理[21, 560]。每个块然后被独立地索引并存储在向量数据库中。这种独立性阻止了检索捕捉块之间的关系,从而在需要多跳推理和长远规划的任务中影响性能。然而,GraphRAG将块存储为相互连接的节点,边表示它们的关系,这可以为检索、组织和生成带来好处。在检索过程中,这些边可以实现多跳遍历,捕捉与现有检索块共享逻辑连接的其他块。此外,检索到的内容可以根据语义意义(例如重新排序[43, 171, 255])以及它们的结构关系(例如图修剪[376, 430])进行组织。在生成阶段,通过将互依性(例如位置编码[360, 547])压缩到生成器中,可以将更多的结构信号编码到生成的内容中。
-
差异3 - 域不变性与领域特定信息:图结构数据中的关系是领域特定的。与图像和文本不同,图像和文本的不同领域通常共享可迁移的语义[253, 285],如图像中的纹理和颗粒,或文本中由分词器定义的词汇,而图结构数据缺乏显式的可迁移单元。图像和文本中的这一共享基础为设计几何不变的编码器奠定了基础,并支持著名的数据扩展法则。然而,对于图结构数据,生成图的数据生成过程在不同领域之间变化显著。这种变化使得关系信息高度领域特定,因此几乎不可能设计出适用于不同领域的统一GraphRAG。例如,在预测学术论文的主题时,广泛接受的同类假设建议检索论文的参考文献来指导其主题预测[561]。然而,当在航班网络中分类机场的角色时,这种同类假设不适用,因为枢纽往往在一个国家中稀疏分布且没有直接连接[67]。此外,即使在相同领域的相同图中,不同的任务也可能需要不同的GraphRAG设计。例如,在设计自动化邮件补全系统以提高公司内部沟通效率时,应考虑内容相关性和语气一致性[428]。为了确保生成邮件的内容相关性,可能假设相近的邮件(即来自相同对话线程的邮件)共享相似的内容,因此应检索这些邮件进行参考。然而,为了保持语气一致性,可能需要检索来自具有相似角色的员工的邮件,即使它们之间没有紧密的社交关系(例如,上下级之间),但仍具有相似的结构角色(如不同团队的经理)。
尽管GraphRAG的上述差异推动了该领域的广泛研究,但目前该领域的研究仍然碎片化,不同研究之间在概念、技术和数据集上存在显著差异。此外,当前的GraphRAG研究主要集中在知识图和文档图上,如图2所示,通常忽略了其他领域(如基础设施图)的广泛应用。这种失衡不仅阻碍了GraphRAG的进一步发展,还可能产生“泡沫效应”,限制未来探索的范围。为了解决这些挑战,我们提出了一个全面且最新的GraphRAG综述,旨在从全局视角统一GraphRAG框架,同时从局部视角专门化每个领域的独特设计。我们综述的关键贡献如下:
- GraphRAG的整体框架:我们提出了一个包含五个关键组件的GraphRAG整体框架:查询处理器、检索器、组织器、生成器和图数据源。在每个组件内,我们回顾了具有代表性的GraphRAG技术。
- GraphRAG在不同领域的专门化:我们将GraphRAG设计分为10个不同的领域,基于其具体应用,包括知识图、文档图、科学图、社交图、规划与推理图、表格图、基础设施图、生物学图、场景图和随机图。对于每个领域,我们回顾了它们的独特应用和具体的图构建方法。然后,我们总结了每个领域中每个组件的独特设计,并收集了丰富的基准数据集和工具资源。
- 挑战与未来方向:我们突出当前GraphRAG研究的挑战,并指出进一步推动GraphRAG进入新领域的未来机遇。