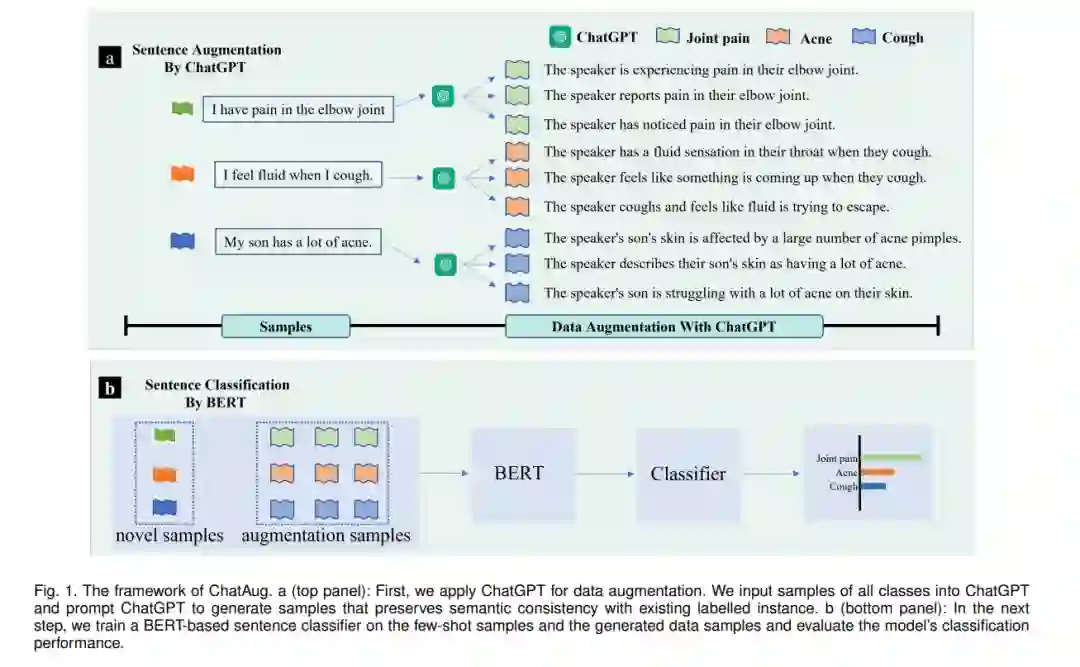
在许多自然语言处理(NLP)任务中,文本数据增强是克服有限样本挑战的有效策略。这一挑战在少样本学习场景中尤其突出,在这种场景中,目标域中的数据通常要少得多,质量也较低。缓解此类挑战的一种自然且广泛使用的策略是对训练数据进行数据增强,以更好地捕获数据不变性并增加样本大小。然而,现有的文本数据增强方法要么不能保证生成数据的正确标注(缺乏忠实度),要么不能保证生成数据的足够多样性(缺乏完整性),或者两者兼有。受最近大型语言模型的成功,特别是ChatGPT的发展的启发,本文提出了一种基于ChatGPT的文本数据增强方法(名为ChatAug)。ChatGPT在具有无与伦比的语言丰富性的数据上进行训练,并采用大规模人类反馈的强化训练过程,使模型与人类语言的自然性具有亲和力。我们的文本数据增强方法ChatAug将训练样本中的每个句子重新短语为多个概念相似但语义不同的样本。然后,增强后的样本可以用于下游模型训练。在小样本学习文本分类任务上的实验结果表明,与当前主流的文本数据增广方法相比,ChatAug方法在测试精度和增广样本分布方面具有更好的性能。
自然语言处理(NLP)的有效性在很大程度上依赖于训练数据的质量和数量。由于可用的训练数据有限,这在实践中是一个常见的问题,原因是隐私问题或人工标注的高成本,训练一个准确的NLP模型,使其很好地泛化到未见过的样本,可能是一项挑战。训练数据不足的挑战在少样本学习(FSL)场景中尤其突出,其中在原始(源)域数据上训练的模型有望从新(目标)域[1]中的少数示例中泛化。许多FSL方法在克服这一挑战的各种任务[2]中显示出良好的效果。现有的FSL方法主要集中在通过更好的架构设计来提高模型的学习和泛化能力[3],[4],[5],以预训练语言模型为基础,然后使用有限的样本对其进行微调[6]与元学习[4],[7]或基于提示的方法[8],[9],[10],[11]。然而,这些方法的性能仍然受到源领域和目标领域数据质量和数量的本质限制。
除了模型开发,文本数据增强还可以克服样本量的限制,并与NLP中的其他FSL方法协同工作。数据增强通常与模型无关,不涉及对底层模型架构的更改,这使得这种方法特别实用,适用于广泛的任务。在NLP中,有几种类型的数据增强方法。传统的文本级数据增强方法依赖于对现有样本库的直接操作。一些常用的技术包括同义词替换、随机删除和随机插入[14]。最近的方法利用语言模型来生成可靠的样本以进行更有效的数据增强,包括反向翻译[15]和潜空间[16]中的词向量插值。然而,现有的数据增强方法在生成文本数据的准确性和多样性方面存在局限性,在许多应用场景[14]、[17]、[18]中仍然需要人工标注。
GPT族[8]、[19]等(超大型)语言模型的出现,为生成类似于人工标注数据的文本样本带来了新的机遇,极大地减轻了人工标注人员[20]的负担。llm以自监督的方式进行训练,随着开放域中可用的近无限数量的文本语料库的扩展。llm的大参数空间也使它们能够存储大量的知识,而大规模的预训练(例如,训练GPTs中的自回归目标)使llm能够为语言生成编码丰富的事实知识。此外,ChatGPT的训练遵循Instruct-GPT[21],利用人工反馈强化学习(RLHF),从而使其能够对输入产生更有信息和公正的响应。
受语言模型成功应用于文本生成的启发,提出了一种新的数据增强方法ChatAug,利用ChatGPT生成辅助样本用于小样本文本分类。通过在通用领域和医疗领域数据集上的实验,测试了ChatAug的性能。与现有的数据增强方法相比,ChatAug方法在句子分类准确率上有两位数的提升。对生成文本样本的忠实度和完整性的进一步研究表明,ChatAug可以生成更多样化的增强样本,同时保持其准确性(即与数据标签的语义相似度)。llm的发展将带来人类水平的标注性能,从而彻底改变NLP中的少样本学习和许多任务领域。