举一反三:示例增强的(example augmented)自然语言处理
© 作者|龚政
机构|中国人民大学
研究方向|自然语言处理
本文对示例增强的(example augmented)自然语言处理的一些相关工作进行了介绍和探讨。文章也同步发布在AI Box知乎专栏(知乎搜索 AI Box专栏),欢迎大家在知乎专栏的文章下方评论留言,交流探讨!
引言
1. Retrieve and Edit
使用示例来增强模型的一个比较明显的应用场景是某些可以对示例中的答案直接进行copy的生成任务,在这一类工作中,模型会主要对检索出的示例做较多的文本内容上的参考。下面对两篇这方面的相关工作进行介绍:
Prototype-to-Style: Dialogue Generation with Style-Aware Editing on Retrieval Memory, IEEE/ACM Transactions on Audio, Speech, and Language Processing 2021
本文来自于剑桥大学、腾讯AI LAB以及香港中文大学,该篇文章主要关注于如何生成特定风格(Style)的对话,大体上的思路为将检索回来的对话内容作为模板,然后由模型根据指定的风格做内容上的编辑,如下图所示:
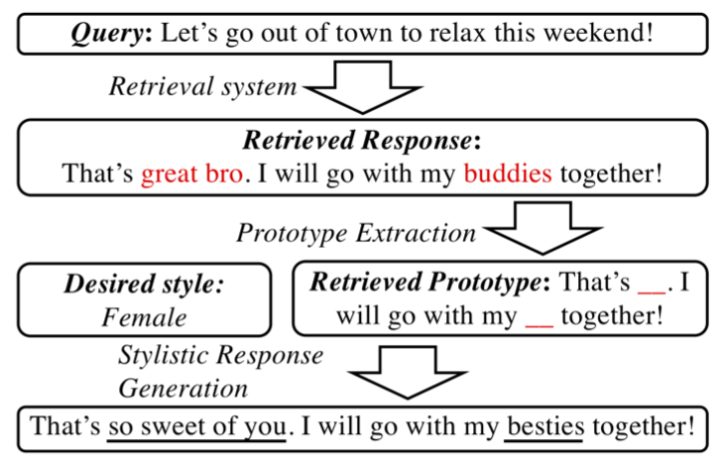
具体来说,本文介绍的方法主要包含三个模块,模板生成(Prototype Extraction)、风格特定的回复生成器(Stylistic Response Generator)以及如何训练(Learning)。
Prototype Extraction:本文通过对检索回来的response中和style相关词进行mask来得到一个response的模板。为了定义哪些词是和style相关的,本文对训练集中出现的所有词汇和style计算了pointwise mutual information (PMI),其中
Stylistic Response Generator:本文采用GPT2作为生成模型,将query、response prototype以及reference response用分隔符拼接作为输入,并加上对应的segment embedding进行区分。为了学习生成特定style的语言,本文为每个style学习了一个style embedding加到生成的response部分。整体框架如下图所示:
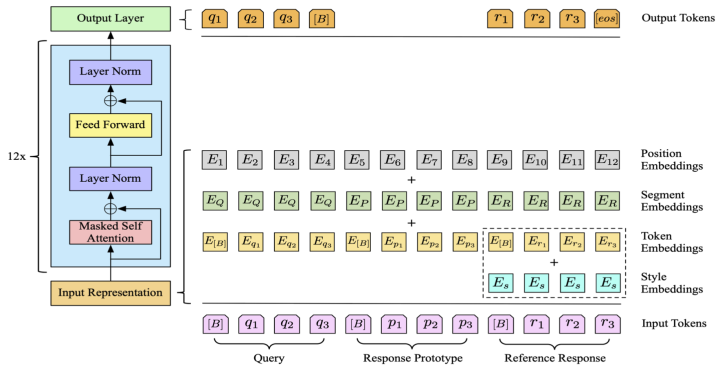
Learning:本文的训练部分没有涉及到检索模块,而是直接对训练样本中的reference response进行stylist word mask、random mask以及random replace三种denoise操作得到response prototype,这样做的好处在于既确保了训练时模板和reference之间的相关性,又避免了模型进行逐字逐句的复制粘贴。最后在训练的损失上,本文加大了stylist word的损失权重,并引入了query部分的LM Loss作为辅助损失。
Neural Machine Translation with Monolingual Translation Memory, ACL 2021
本文来自于香港中文大学和腾讯AI LAB,是ACL 2021的outstanding paper。
另一个可以将示例作为模板的应用场景是机器翻译,通过检索出和当前输入相似的source sentence,模型完全可以参考检索样例的target sentence来生成当前输入的翻译。但是这种方法通常需要配备大量的对齐语料作为检索库,本文则尝试解决这个痛点,采用单语言的语料库作为检索库来增强模型。本文的模型框架图如下:
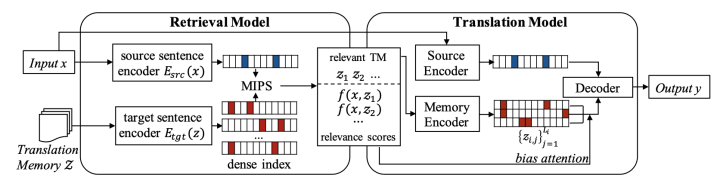
Retrieval Model:本文设置的检索语料库为目标语言的单语言语料库。本文首先采用Dual-Encoder的方式分别对输入句子和检索库中的句子进行编码,然后通过点积得到相似度,最后用FAISS得到和输入句子最为相关的M个检索示例。为了对Retrieval Model和后面的Translation Model进行统一训练,这M个检索示例和输入句子的相似度会进一步被用于后面的翻译过程。这里检索模型存在一个冷启动的问题,也就是随机初始化的检索模块会检索出与输入毫无关系的检索示例,这可能会让整个模型学习到直接忽略掉检索示例来完成翻译任务。因此本文还设计了两个sentence-level和token-level的对齐任务来帮助检索模块初始化。
Translation Model:翻译模块在进行生成时同时利用了输入句子和检索回来的示例。具体来说,模型首先和标准的Seq2Seq模型一样,通过Encoder对输入句子进行编码,然后用自回归的方式在Decoder端生成需要预测token的表示 。在此基础上,本文继续将每个检索示例分别用Encoder编码,将得到的表示拼接后喂给Decoder作cross-attention,得到对每一个示例的每一个token的attention score,这些attention score会被之前检索时得到的相似度进一步加权。最后预测token的概率分布由两部分加权组成,一部分是模型正常使用自回归方式得到的概率,另一部分是由attention score主导的直接copy检索示例中的token的概率。
2. Retrieve Rather Than Memorize
深度学习模型的一个重要特性是具有良好的泛化能力,即模型在训练集上学习到的知识可以很好的泛化到测试集上。以下两篇论文表明,比起完全依靠训练将训练集中的知识全部保存在模型参数当中,直接将具有帮助的样本检索出来可能更为高效。
PAQ: 65 Million Probably-Asked Questions and What You Can Do With Them, TACL 2021
本文来自于FaceBook和伦敦大学学院,已发表在TACL 2021。
当前Open Domain QA任务通常首先对大规模的文档语料库进行检索,再基于检索出文档内容做阅读理解得到最终答案,这种方式需要大量的空间和时间来存储和检索文档语料。本文首先设计了一种数据增强的方式,提出了一个包含65M自动生成的QA Pair的数据集 Probably Asked Questions (PAQ),然后基于这个数据集对上述解决ODQA任务方法的缺陷做了两方面的探索:
1、Closed-Book QA (CBQA),通过在大量的问答对上对模型进行微调,让模型直接学习问题到答案的映射,从而可以不借助外部知识/语料来回答问题。
2、QA-Pair retriever (RePAQ),通过检索问答对而不是文档来帮助模型回答当前问题,这种检索方式相比起之前的检索范式在内存、速度和准确性方面都具有优势。
本文所涉及的模型结构图以及部分实验结果如下:
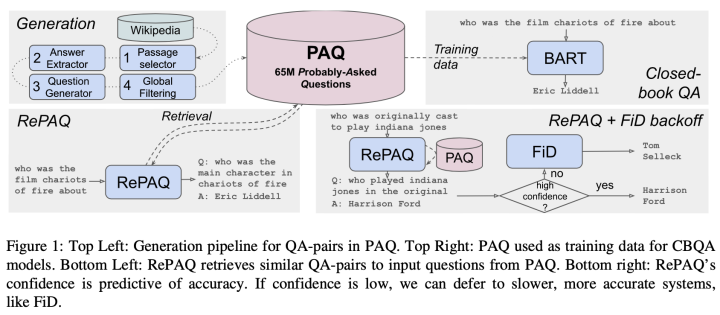
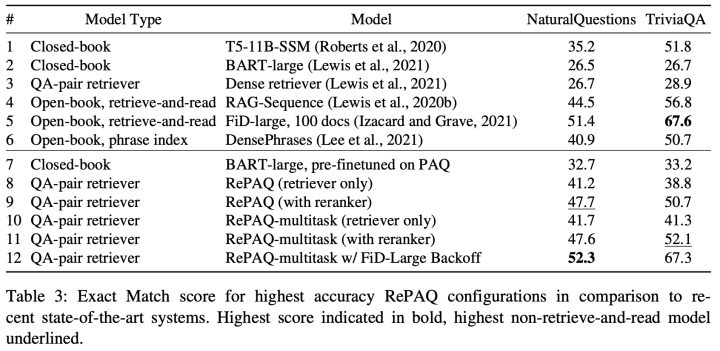
笔者在这里不对该篇论文的数据生成和利用方法进行详细介绍,主要关注论文中的部分实验结果。对比实验结果中2、7行以及3、8行我们可以看到,语料库的扩充无论是对微调还是检索都是有增益,这一点非常直观。另外对比3、4行可以发现,使用QA对作为外部知识进行增强的效率远远不如用传统的文档作为外部知识。最后对比第7、8行发现,通过检索QA对来增强模型的效果要大幅度超过将模型放在PAQ数据集上进行微调,这似乎表明,即便相比起文档来说,QA-Pair包含的信息量较少,但针对大量QA-Pair中包含的知识,将其存储在外部非参数化的模块中也要优于存储在模型的参数当中。
Training Data is More Valuable than You Think: A Simple and Effective Method by Retrieving from Training Data,ACL 2022
本文来自于微软,已被ACL 2022所录取。该篇论文的思想比起上一篇论文更加直接,直接从训练集中检索相似的example来帮助模型完成当前任务,并且本文所使用的方法也较为简单:(1) 使用BM25作为检索器,这里模型在训练时会将训练样本本身从检索语料中过滤掉。(2) 通过文本拼接的方式利用检索回来的示例。
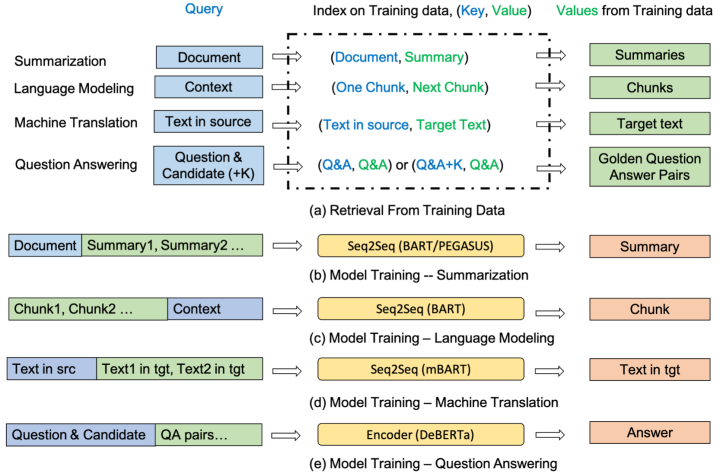
如上图所示,本文在摘要、语言模型、机器翻译和QA四个任务上进行了评测,基本都在原本的模型基础上取得了一定增益。值得注意的是,本文进行实验的数据集都不算太小,不过这也表明了,即便是在下游任务微调时,模型也很难将训练集中的全部内容存储在参数当中并加以利用,因此可以直接通过从训练集中检索具体的示例来对模型进行增强。
3. Case-Based Reasoning
这一部分的两篇工作主要关注于Knowledge Base Question Answering(KBQA)任务,旨在学习相似的example是如何解决问题的,即解决问题的路径/流程,可能是除了复制粘贴以外对example的利用方式最为make sense的一部分工作。
Case-Based Reasoning for Natural Language Queries over Knowledge Bases, EMNLP 2021
本文来自马萨诸塞大学阿默斯特分校和Google,已发表在EMNLP 2021。该篇论文面向有监督的KBQA场景,即每一个query(问题)都被标注了一个对应的logic form(可以看做是一种推理路径),问题的答案可以通过在Knowledge Base上执行问题标注的logic form(推理路径)得到。本文旨在为当前query检索出相似的case,然后利用这些相似case的推理路径生成当前query的推理路径,以得到最终的答案。本文模型的大致框架如图所示:
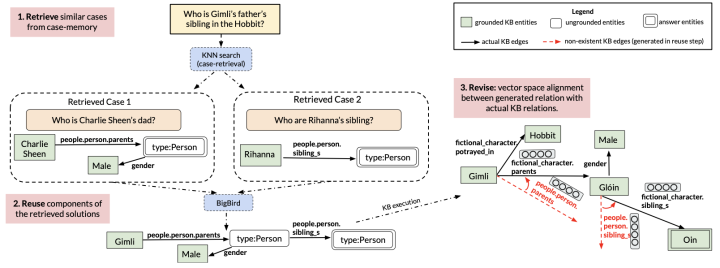
本文提出的模型具体包含三个部分,Retrieve、Reuse以及Revise:
Retrieve:本文采取使用DPR(Dense Passage Retriever)的方式对query的文本进行编码、检索和训练。其中本文希望得到的检索器能更加注重问题的形式而不是其中包含的具体实体,例如对于问题 谁是小明的哥哥?,本文更希望检索得到 谁是小红的哥哥?而不是 谁是小明的爸爸?,因此检索器对文本进行编码时会将实体部分mask掉。
Reuse:本文采用生成的方式来生成当前query的logic form。具体来说,本文将检索得到的query- logic form对全部拼接起来,然后喂给Seq2Seq模型用自回归的方式生成当前query的logic form。由于拼接起来的输入可能会特别长,本文在这里采用BigBird模型来生成logic form。
Revise:由于不确定某些生成的关系路径是否存在于Knowledge Base中,本文进一步对生成的logic form进行修正。本文首先用预训练好的TransE模型对Knowledge Base进行编码,然后将生成结果中不存在的关系替换为当前Knowledge Base中与其最相似的关系。
Knowledge Base Question Answering by Case-based Reasoning over Subgraphs , Arxiv 2022
本文来自马萨诸塞大学阿默斯特分校和Google,和上一篇文章来自于同一个一作。
KBQA问题通常处于一个弱监督的环境当中,即我们只能获取到问题以及答案,并不能得到在Knowledge Base上获取答案的具体推理路径。该篇文章在上一篇论文的基础上进一步解决弱监督的KBQA问题,主要对上一篇论文的Reuse和Revise部分进行修改,将其替换为子图收集和图上推理两个部分,大致框架如图:
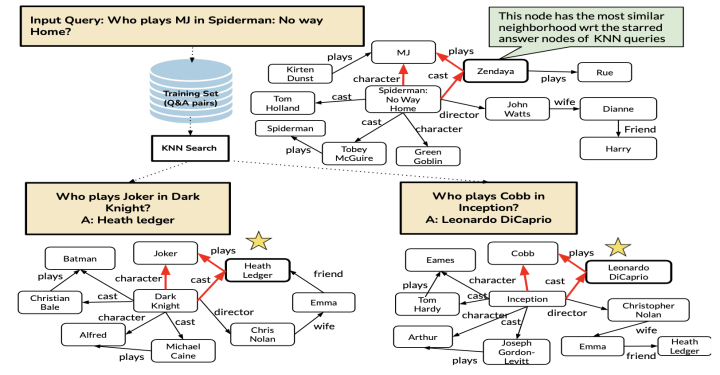
子图收集:由于在弱监督场景中,对检索到的case只能获取问题和答案,本文将问题和答案中的实体全部抽取出来,并在Knowledge Base上抽取出所有链接问题实体和答案实体的路径,得到一个sub-graph,可以看作是不那么精准的推理路径。然后利用检索示例得到的子图的relation对输入query中的实体在Knowledge Base上进行延伸,最后得到一个输入query在KB上的一个子图。
图上推理:本文用GNN对子图进行编码,认为在不同的子图当中,答案实体的表示应该是互相之间更为接近的,并且在训练中强化这个假设,即拉近答案实体之间的距离,拉远答案实体和其他实体间的距离。在推理时,本文用GNN对每个检索示例和输入query的子图进行编码,选取输入query的子图中和所有检索子图的答案实体最为相似的实体作为问题的最终答案。
4. Chain Of Thought
还有一类example-based方法是in-context learning,即通过喂给模型一些问题-答案对作为prompt,让模型“学会”回答当前的题目。这一部分工作的特点在于对模型的要求较高,基本只适用于大规模的预训练语言模型,而对example的要求较低,模型更多的是参考根据问题生成答案这样一种形式,而不需要从example中获取额外的知识.
Chain of Thought Prompting Elicits Reasoning in Large Language Models, Arxiv 2022
本文来自于Google。该篇文章在标准的prompt的基础上,提出为每个example加入对问题答案的解释(explanation),目标在于让模型模仿给出的example的思维过程并为当前query生成自己的思维过程,让in-context learning的生成结果更具有可解释性并且提升效果。本文将这种加入explanation的prompt称之为Chain Of Thought Prompt,具体例子如下图所示:
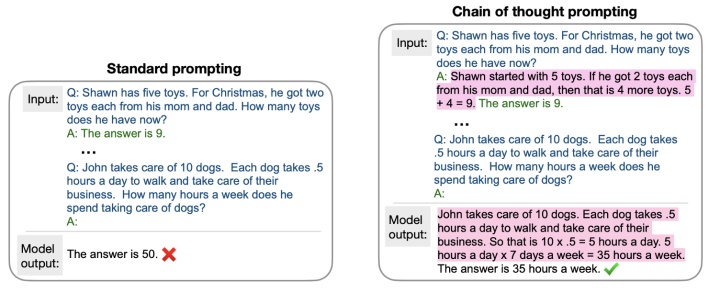
本文在Arithmetic、Symbolic以及Commonsense Reasoning三类任务上做了实验,发现相较于原本的Standard Prompt方式,Chain Of Thought Prompt能够更大程度上的挖掘大规模语言模型的能力。其中论文在算数部分的实验结果如下图:
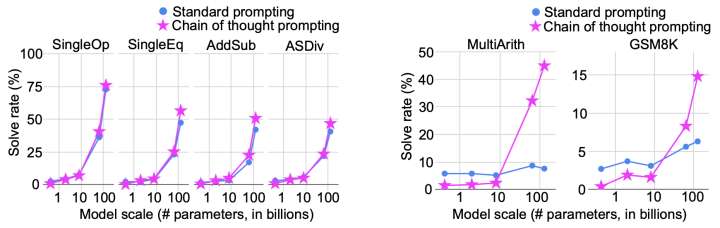
可以看出,在左边较为简单的任务上测试时,两种方法效果随着模型参数量级的提升都呈指数级上升,但在右边较难的数据集上测试时,相比于Standard Prompting,Chain Of Thought更能保持对大模型能力的利用。
The Unreliability of Explanations in Few-Shot In-Context Learning, Arxiv 2022
本文来自于得克萨斯大学奥斯汀分校。该篇论文在QA和NLI任务的三个数据集上对Chain Of Thought方法进行了实验,实验发现在这些数据集上,Chain Of Thought并不总是会带来增益,即效果并不比Standard Prompt方式好,实验结果如下图,其中P-E和E-P分别表示在Chain Of Thought中将explanation拼接在答案的前面还是后面。

论文进一步对GPT3生成的解释进行了分析,并从两个角度对其进行评估:(1) 正确性,生成的解释是否违背了上下文中给出的某些条件。(2) 一致性,生成的解释是否能推导出模型给出的答案。结果发现GPT3生成的这些解释具有很好的一致性和很差的正确性,并且模型对于做错的题目,基本都生成了错误的解释。

基于这个发现,本文最后提出用rule-based的方法对模型生成解释的正确性进行了预估,然后设计了多个校准方法对预估为错误的解释进行校准,从而使得模型的chain of thought的效果要优于standard prompt,例如生成多个解释和答案并选取第一个预估解释为正确的答案作为最终预测。
总结:本文针对 Example Augment 这一主题对八篇论文进行了简要介绍,除开最后一部分工作不涉及检索以外,前三部分工作都可以归类到检索增强这一大类工作中。其中第一部分和第三部分对example的利用方式比较直观,都比较显式的利用了相似的example中可以参考的部分用于帮助解答当前任务(内容以及方法)。第三部分对推理路径的参考在笔者看来很具有启发性,相比起包含丰富知识的文档,包含知识较少的example的优势除了使用起来更加轻便以外,还在于能够提供具体的可参考的问题解决模式,这一点和第四部分的chain of thought(思维模式)有所相似。目前看来第三部分对推理过程的抽象还局限在结构化的推理路径,第四部分使用了自然语言形式的explanation,但是利用方式并不像第三部分那样直观,更多的在依靠大规模预训练语言模型本身的强大性能,期待未来的工作能将这两部分的特点有所结合。
更多推荐

ACL 2022 主会长文论文分类整理

SIGIR2022|推荐系统相关论文分类整理
稠密检索模型的zero-shot能力究竟如何?


