本文综述了强化学习(Reinforcement Learning, RL)在大语言模型(Large Language Models, LLMs)推理方面的最新进展。RL 在推动 LLM 能力边界方面取得了显著成功,特别是在数学与代码等复杂逻辑任务中表现突出。因此,RL 已逐渐成为将 LLM 转变为大型推理模型(Large Reasoning Models, LRMs)的基础方法。随着该领域的快速发展,RL 在 LRM 上的进一步扩展不仅面临算力资源上的挑战,还涉及算法设计、训练数据与基础设施等方面的根本性问题。为此,我们认为有必要重新回顾该方向的发展历程,重新评估其演进轨迹,并探索促进 RL 向人工超级智能(Artificial SuperIntelligence, ASI)可扩展性的策略。特别地,我们系统考察了自 DeepSeek-R1 发布以来,RL 在 LLM 与 LRM 推理能力上的研究进展,涵盖基础组件、核心问题、训练资源以及下游应用,以识别未来的机遇与研究方向。我们希望本综述能够推动 RL 在更广泛推理模型上的研究。
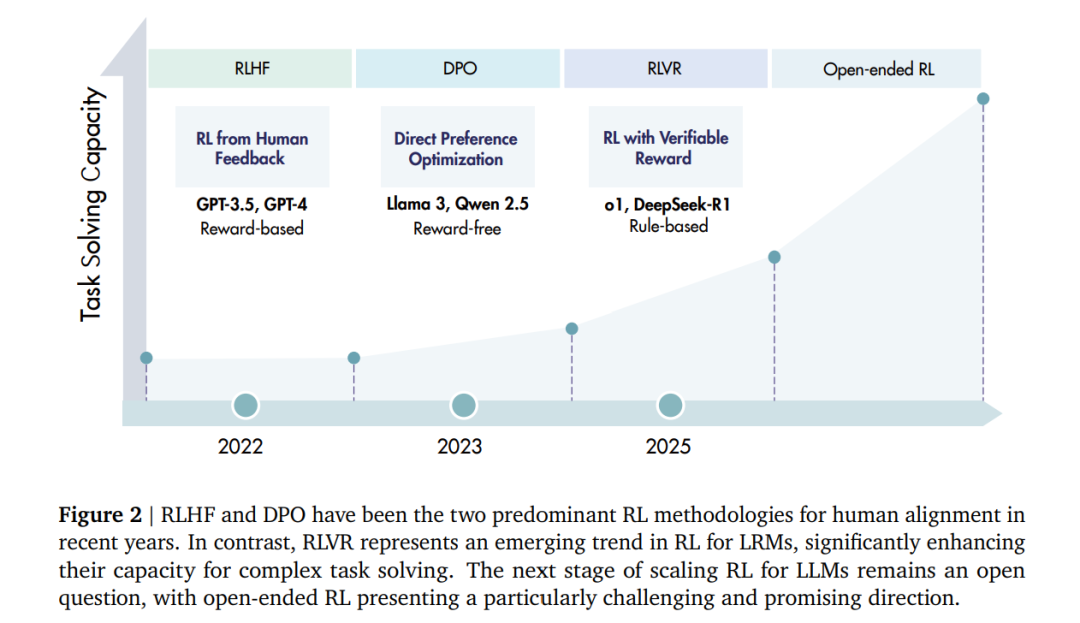
强化学习(Reinforcement Learning, RL)[Sutton et al., 1998] 多次证明,狭义且明确的奖励信号可以驱动人工智能体在复杂任务上达到超越人类的水平。具有里程碑意义的系统如 AlphaGo [Silver et al., 2016] 和 AlphaZero [Silver et al., 2017],完全依赖自我对弈与奖励反馈进行学习,在围棋、国际象棋、日本将棋和 Stratego 游戏中超越了世界冠军 [Perolat et al., 2022; Schrittwieser et al., 2020; Silver et al., 2018],确立了 RL 作为一种可行且前景广阔的高水平问题求解技术的地位。 在大语言模型(Large Language Models, LLMs)时代 [Zhao et al., 2023a],RL 最初作为一种后训练策略,用于实现人类对齐 [Ouyang et al., 2022] 而崭露头角。诸如 基于人类反馈的强化学习(Reinforcement Learning from Human Feedback, RLHF)[Christiano et al., 2017] 与 直接偏好优化(Direct Preference Optimization, DPO)[Rafailov et al., 2023] 等方法被广泛采用,用于微调预训练模型,使其能够遵循指令并反映人类偏好,从而显著提升了模型的有用性、诚实性与无害性(helpfulness, honesty, harmlessness, 3H)[Bai et al., 2022b]。 近期,一个新的趋势正在兴起:面向大型推理模型(Large Reasoning Models, LRMs)的强化学习 [Xu et al., 2025a]。其目标不仅在于对齐行为,更在于激励推理过程本身。两个最新的里程碑(即 OpenAI o1 [Jaech et al., 2024] 与 DeepSeek-R1 [Guo et al., 2025a])表明,通过使用可验证奖励(Reinforcement Learning with Verifiable Rewards, RLVR)训练 LLMs ——例如数学答案的正确性,或代码的单元测试通过率——可以使模型具备长程推理能力,包括规划、反思与自我纠错。OpenAI 的研究报告 [Jaech et al., 2024] 显示,o1 的性能随着 **额外 RL 训练(更多训练算力)以及推理阶段更长的“思考时间”(更多测试时算力)**而持续提升 [Brown et al., 2024; Liu et al., 2025l; Snell et al., 2024],揭示了一条超越仅依赖预训练的新扩展维度 [Aghajanyan et al., 2023; Kaplan et al., 2020]。DeepSeek-R1 [Guo et al., 2025a] 则采用基于规则的显式准确性奖励(数学)以及编译或测试驱动的奖励(代码任务)。这种方法表明,大规模强化学习,特别是 群体相对策略优化(Group Relative Policy Optimization, GRPO),能够在基础模型尚未经过后续对齐阶段前,就诱导出复杂的推理行为。 这一转变将“推理”重塑为一种可以被显式训练和扩展的能力 [OpenAI, 2025a,b]:LRMs 会在测试时分配大量计算预算,用于生成、评估和修正中间的思维链(chain-of-thought, CoT)[Wei et al., 2022],并且其性能会随着该预算的增加而提升。这种动态提供了一条与预训练阶段的数据和参数扩展正交的能力提升路径 [Aghajanyan et al., 2023; Kaplan et al., 2020],同时利用了奖励最大化目标 [Silver et al., 2021],在存在可靠验证器时自动利用可检验的奖励(例如竞赛数学 [Guo et al., 2025a; Jaech et al., 2024]、竞技编程 [El-Kishky et al., 2025] 以及部分科学领域 [Bai et al., 2025])。此外,RL 还能通过支持自生成训练数据 [Silver et al., 2018; Zhao et al., 2025a] 来突破数据限制 [Shumailov et al., 2024; Villalobos et al., 2022]。因此,RL 越来越被视为一项有潜力通过持续扩展,在更广泛的任务上实现人工超级智能(Artificial SuperIntelligence, ASI)的关键技术。 与此同时,RL 在 LRM 上的进一步扩展引入了新的约束,不仅涉及算力资源,还包括算法设计、训练数据与基础设施。RL 应如何以及在何处扩展,以实现高水平智能并产生现实价值,仍是未解的问题。因此,我们认为当前正是重新审视该领域发展并探索提升 RL 可扩展性以迈向人工超级智能的合适时机。 总而言之,本文综述了 RL 在 LRM 上的最新研究,主要贡献如下:
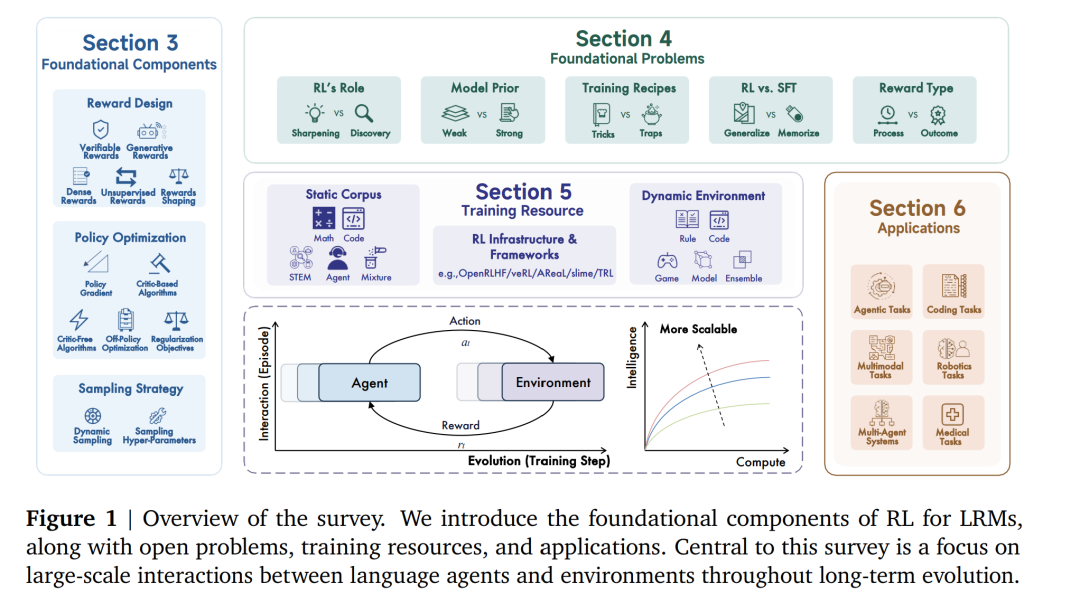
我们介绍了 LRM 场景下的 RL 建模初步定义(§2.1),并梳理了自 OpenAI o1 发布以来前沿推理模型的发展(§2.2)。 * 我们回顾了 RL for LRM 的基础组件,包括奖励设计(§3.1)、策略优化(§3.2)、采样策略(§3.3),并比较了各研究方向与技术路径。 * 我们讨论了 RL for LRM 的基础性与仍具争议的问题(§4),如 RL 的角色(§4.1)、RL 与监督微调(SFT)的关系(§4.2)、模型先验(§4.3)、训练范式(§4.4)与奖励定义(§4.5),并指出这些问题值得进一步探索以推动 RL 的持续扩展。 * 我们考察了 RL 训练资源(§5),包括静态语料(§5.1)、动态环境(§5.2)与训练基础设施(§5.3)。这些资源在研究与生产中均可复用,但仍需进一步标准化与发展。 * 我们回顾了 RL 在多种任务中的应用(§6),涵盖代码任务(§6.1)、智能体任务(§6.2)、多模态任务(§6.3)、多智能体系统(§6.4)、机器人任务(§6.5)以及医疗应用(§6.6)。 * 最后,我们讨论了 RL 在语言模型中的未来研究方向(§7),包括新算法、新机制、新特性及更多潜在研究路径。