
机器之心报道
编辑:泽南「成立公司之后,我们陆续发布开源模型,一切进展顺利,」王小川表示。 在业界都惊讶于百川智能平均 28 天发布一款大模型的时候,这家公司并没有停下脚步。 9 月 6 日下午的发布会上,百川智能宣布正式开源微调后的 Baichuan-2 大模型。

这是百川自 8 月发布 Baichuan-53B 大模型后的又一次新发布。本次开源的模型包括 Baichuan2-7B、Baichuan2-13B、Baichuan2-13B-Chat 与其 4bit 量化版本,并且均为免费可商用。 除了模型的全面公开之外,百川智能此次还开源了模型训练的 Check Point,并公开了 Baichuan 2 技术报告,详细介绍了新模型的训练细节。百川智能创始人兼 CEO 王小川表示,希望此举能够帮助大模型学术机构、开发者和企业用户深入了解大模型的训练过程,更好地推动大模型学术研究和社区的技术发展。
- Baichuan 2 大模型开原链接:https://github.com/baichuan-inc/Baichuan2
- 技术报告:https://cdn.baichuan-ai.com/paper/Baichuan2-technical-report.pdf
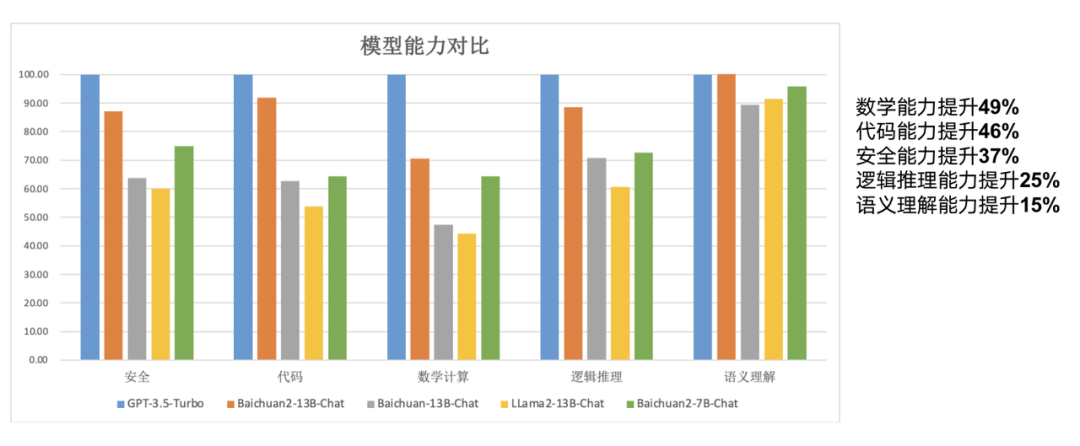
今天开源的模型相对于大模型而言体量「较小」,其中 Baichuan2-7B-Base 和 Baichuan2-13B-Base 均基于 2.6 万亿高质量多语言数据进行训练,在保留了上一代开源模型良好的生成与创作能力,流畅的多轮对话能力以及部署门槛较低等众多特性的基础上,两个模型在数学、代码、安全、逻辑推理、语义理解等能力有显著提升。 「简单来说,Baichuan7B 70 亿参数模型在英文基准上已经能够与 LLaMA2 的 130 亿参数模型能力持平。因此,我们可以做到以小博大,小模型相当于大模型的能力,而在同体量上的模型可以得到更高的性能,全面超越了 LLaMA2 的性能,」王小川介绍道。 其中 Baichuan2-13B-Base 相比上一代 13B 模型,数学能力提升 49%,代码能力提升 46%,安全能力提升 37%,逻辑推理能力提升 25%,语义理解能力提升 15%。
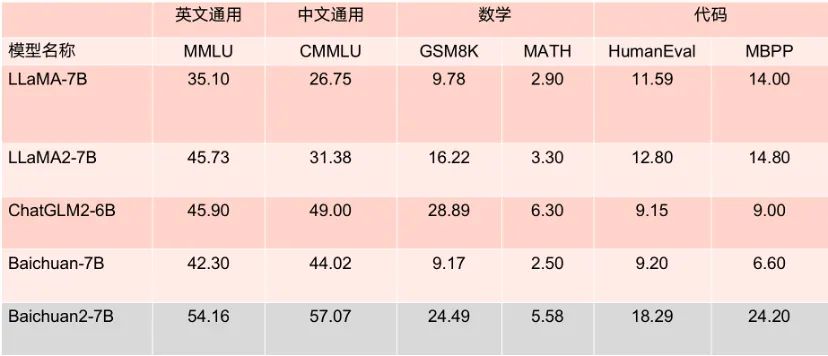
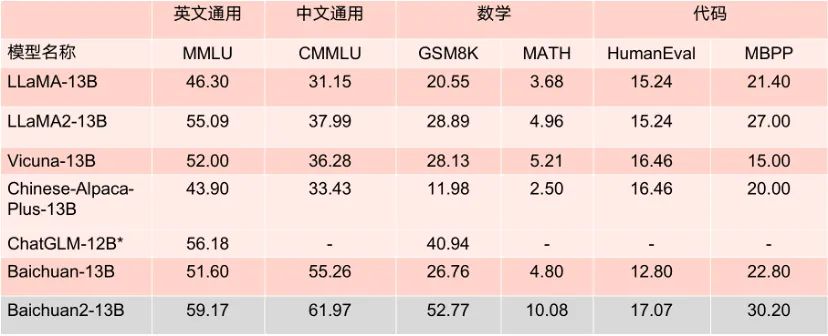
据介绍,在新的模型上,百川智能的研究者们从数据获取到微调进行了很多优化。 「我们借鉴了之前做搜索时的更多经验,对大量模型训练数据进行了多粒度内容质量打分,使用了 2.6 亿 T 的语料级来训练 7B 与 13B 的模型,并且加入了多语言的支持,」王小川表示。「我们在千卡 A800 集群里可以达到 180TFLOPS 的训练性能,机器利用率超过 50%。在此之外,我们也完成了很多安全对齐的工作。」 本次开源的两个模型在各大评测榜单上的表现优秀,在 MMLU、CMMLU、GSM8K 等几大权威评估基准中,以较大优势领先 LLaMA2,相比其他同等参数量大模型,表现也十分亮眼,性能大幅度优于 LLaMA2 等同尺寸模型竞品。 更值得一提的是,根据 MMLU 等多个权威英文评估基准评分 Baichuan2-7B 以 70 亿的参数在英文主流任务上与 130 亿参数量的 LLaMA2 持平。
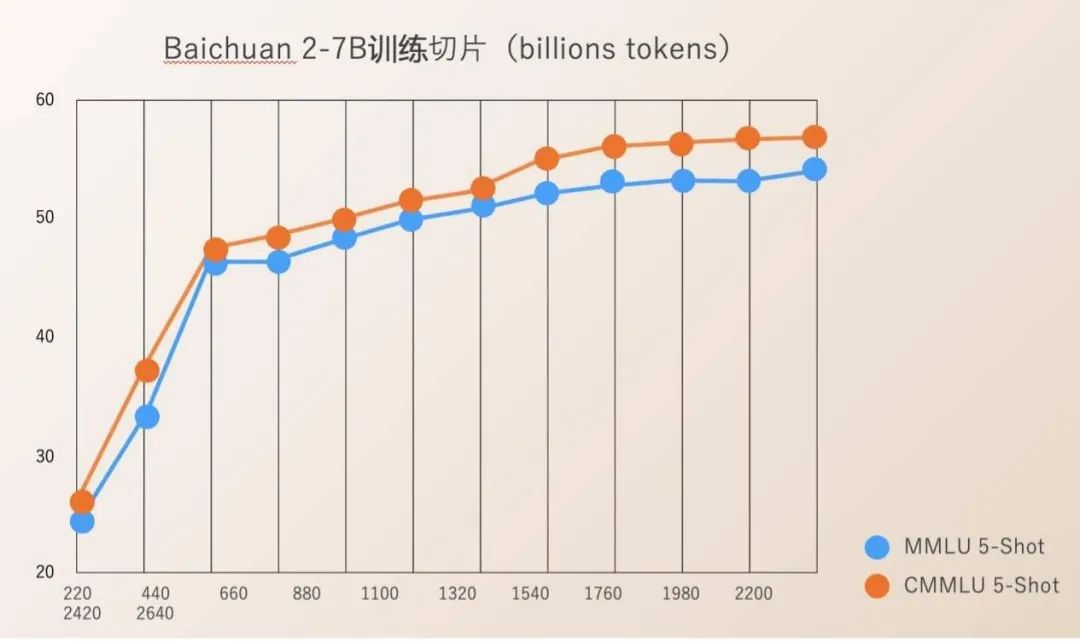
Baichuan2-7B 和 Baichuan2-13B 不仅对学术研究完全开放,开发者也仅需邮件申请获得官方商用许可后,即可以免费商用。 「除了模型发布以外,我们也希望对学术领域做更多的支持,」王小川表示。「除了技术报告以外,我们也把 Baichuan2 大模型训练过程中的权重参数模型进行了开放。这对于大家理解预训练,或者进行微调强化能够带来帮助。这也是在国内首次有公司能开放这样的训练过程。」 大模型训练包含海量高质量数据获取、大规模训练集群稳定训练、模型算法调优等多个环节。每个环节都需要大量人才、算力等资源的投入,从零到一完整训练一个模型的高昂成本,阻碍了学术界对大模型训练的深入研究。 百川智能本次开源了模型训练从 220B 到 2640B 全过程的 Check Point。这对于科研机构研究大模型训练过程、模型继续训练和模型的价值观对齐等极具价值,可以推动国内大模型的科研进展。
此前,大部分开源模型只是对外公开自身的模型权重,很少提及训练细节,开发者们只能进行有限的微调,很难深入研究。 百川智能公开的 Baichuan 2 技术报告详细介绍了 Baichuan 2 训练的全过程,包括数据处理、模型结构优化、Scaling law、过程指标等。 百川智能自成立之初,就将通过开源方式助力中国大模型生态繁荣作为公司的重要发展方向。成立不到四个月,便相继发布了 Baichuan-7B、Baichuan-13B 两款开源免费可商用的中文大模型,以及一款搜索增强大模型 Baichuan-53B,两款开源大模型在多个权威评测榜单均名列前茅,目前下载量超过 500 万次。 上周,首批大模型公众服务拍照落地是科技领域的重要新闻。在今年创立的大模型公司中,百川智能是唯一一家通过《生成式人工智能服务管理暂行办法》备案,可以正式面向公众提供服务的企业。 凭借行业领先的基础大模型研发和创新能力,此次开源的两款 Baichuan 2 大模型,得到了上下游企业的积极响应,腾讯云、阿里云、火山方舟、华为、联发科等众多知名企业均参加了本次发布会并与百川智能达成了合作。据介绍,百川智能的大模型在 Hugging Face 上近一个月来的下载量已达到 337 万。 按照此前百川智能的计划,在今年他们还要发布千亿参数大模型,并在明年一季度推出 「超级应用」。
© THE END 转载请联系本公众号获得授权 投稿或寻求报道:content@jiqizhixin.com
