摘要
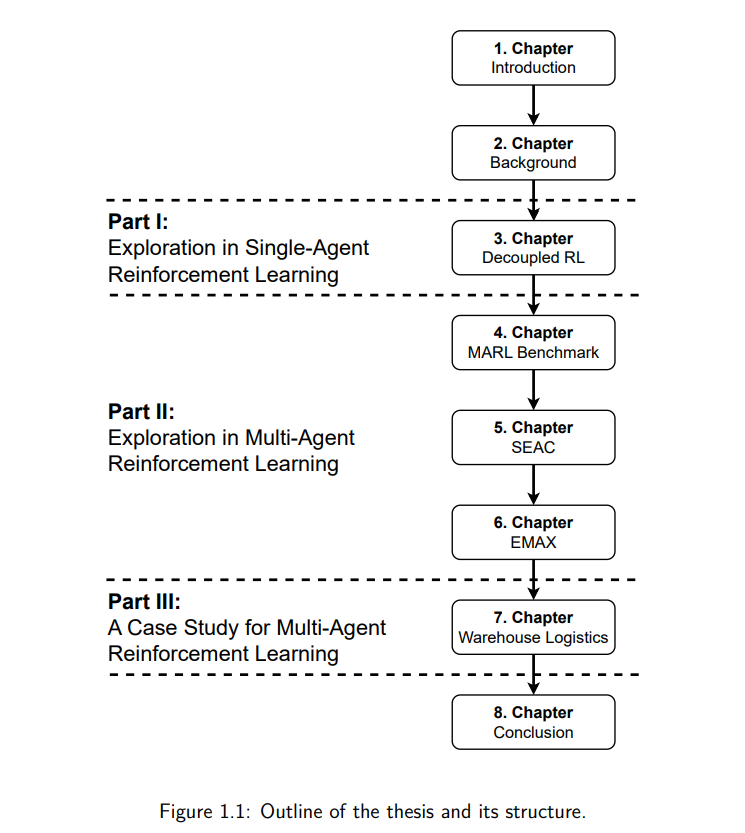
本论文关注于强化学习(RL),其中决策代理通过与环境的交互并接收奖励反馈来学习理想的行为。从交互中学习决策与大多数机器学习范式不同,强化学习代理不仅需要学习如何收集数据以指导未来的决策,还需要学习最大化累积奖励的期望行为。这些过程被称为探索和利用。本文的重点是强化学习中的探索问题,并提出了引导代理高效收集数据、平衡探索与利用的创新解决方案。 论文的第一部分关注于在稀疏奖励环境中单智能体强化学习的探索问题。在这种环境下,单个决策代理通过与环境的交互学习,并且很少(或几乎不)从环境中获得非零奖励。在这种挑战性环境中,一个常见的探索方法是引入内在奖励,通过内在奖励激励代理进行探索。然而,通过引入这个第二优化目标,代理需要显式并小心地平衡内在奖励的探索目标与环境中外在奖励的利用目标。为了解决这个问题,我们提出了分解强化学习(DeRL)。在DeRL中,代理为探索和利用学习独立的策略,以适应这两种策略的不同目标。探索策略通过内在奖励进行训练,用于收集有价值的数据以供利用策略使用,而利用策略则在收集的数据上进行训练,以解决任务。我们展示了DeRL在样本效率和对探索与利用之间权衡的超参数的鲁棒性方面,优于现有的内在动机驱动的探索方法。 在论文的后续部分,我们将重点转向多智能体强化学习(MARL)中的探索问题。在MARL中,多个决策代理通过与共享环境的交互共同学习。本文关注于需要代理合作的环境,即代理需要学习协调其行为以达成共同目标。与单智能体强化学习相比,这一额外的考虑使得学习过程和探索变得更加复杂,因为现在需要考虑代理之间的交互。本文对MARL的第一个贡献是对十种算法在25个合作性共享奖励环境中的综合基准测试。作为这一研究的一部分,我们开源了EPyMARL,一个扩展了现有PyMARL代码库的MARL代码库,增加了更多的算法、支持更多环境,并增强了可配置性。在分析这一基准测试后,我们识别出MARL中存在的挑战,尤其是在奖励信息稀缺的环境中如何高效训练代理进行合作。针对这一挑战,我们提出了共享经验的演员-评论员算法(SEAC)。SEAC利用许多多智能体环境中的对称性,跨代理共享经验,并通过演员-评论员算法从所有代理的集体经验中进行学习。在实验中,我们证明了经验共享显著提高了学习效率,并帮助代理同时学习多种技能。然而,对于基于价值的算法,经验共享的效果不如预期,因为这些算法的代理不会显式学习策略。 为了引导基于价值的MARL算法的探索,我们提出了多智能体探索的集成价值函数(EMAX)。EMAX为每个代理训练一组价值函数,并引导代理的探索朝向可能需要多个代理协作的状态和动作。通过这种方式,代理能够更高效地协调其行为,我们证明了EMAX作为三种常见基于价值的MARL算法的扩展,可以显著提高训练的样本效率和稳定性。 最后,本文展示了一个案例研究,讨论了MARL在仓库物流自动化中的应用。本章是与Dematic GmbH的行业合作成果,我们在其中形式化了仓库物流问题,并提出了一个双重解决方案来应对这一环境的可扩展性挑战。我们的方法利用多智能体学习架构的层次化分解,并屏蔽掉被认为无效的动作。通过这些技术,简化了个体代理的学习目标,使MARL代理能够更高效地学习,并在更多代理和位置的较大仓库实例中扩展,同时超越了行业标准启发式算法和传统MARL算法的性能。